《架构师》专题
-
架构师技能图谱 V1.2
系统架构能力 基本理论 扩展性设计 可用性设计 可靠性设计 一致性设计 负载均衡设计 过载保护设计 灾难恢复和备份 协议设计 二进制协议 文本协议 接入层架构设计 DNS 轮询 动静态分离 静态化 反向代理 LVS F5 CDN 逻辑层架构设计 连接池 串行化技术 影子 Master 架构 批量写入 配置中心 去中心化 通讯机制 同步与异步 MQ Cron RMI RPC 数据层架构设计 缓存优化
-
注册Avro架构时出错:“字符串”RestClientException:注册的架构与早期架构不兼容;
我试图使用Avro模式向我的经纪人发送消息,但“我总是收到错误: 2020-02-01 11:24:37.189[nioEventLoopGroup-4-1]错误应用程序-未经处理:POST-/api/orchestration/org。阿帕奇。Kafka。常见的错误。SerializationException:注册Avro架构时出错:io导致“字符串”。汇合的。Kafka。阴谋论。客户Rest
-
从GraphiQL下载架构
我目前正在使用apollo android和iOs库,这需要我下载模式。是否可以从graphicql下载模式?目前,我一直从命令行收到错误,无法从GraphiQL界面手动下载。提前谢谢!
-
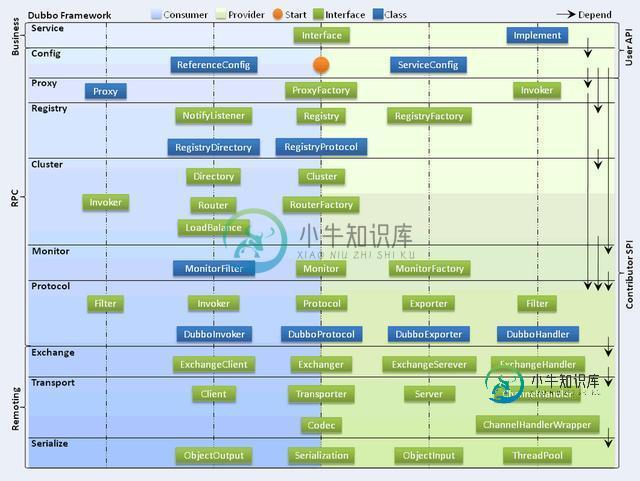 Dubbo的架构设计?
Dubbo的架构设计?本文向大家介绍Dubbo的架构设计?相关面试题,主要包含被问及Dubbo的架构设计?时的应答技巧和注意事项,需要的朋友参考一下 Dubbo框架设计一共划分了10个层: 服务接口层(Service):该层是与实际业务逻辑相关的,根据服务提供方和服务消费方的业务设计对应的接口和实现。 配置层(Config):对外配置接口,以ServiceConfig和ReferenceConfig为中心。 服
-
12 RESTful架构(SOAP,RPC)
推荐: http://www.ruanyifeng.com/blog/2011/09/restful.html
-
Zookeeper架构 - Zookeeper仲裁
为仲裁模式选定足够的服务器是很重要的。无论系统延迟和奔溃,仲裁者必须保证任何的更新请求Zookeeper都会积极的响应并保存,直到另外一个请求取代它。 这个例子就是在第一章提到过的脑裂场景之一。为了避免这个问题,这个例子中仲裁者的数量不得低于三个,这是五台服务器的大多数。为了继续运行,整个Zookeeper集合必须保证三台服务器可用。为了确认更新请求已经成功的完成了,Zookeeper集合需要至少
-
获取表的架构
问题内容: 给定一个SQLConnection对象,如何获得单个表的架构? 前几天我在尝试这种方法,我似乎能够从运行查询所获得的数据集中获取模式,但是我可以从连接中获得的所有模式信息似乎都与可用的表有关。而不是表格上的实际详细信息。 我敢肯定有一个简单的方法可以做到这一点。 问题答案: 我认为从查询(通过GetSchemaTable)访问架构是唯一的方法。如果您只对模式感兴趣,则可以运行不返回任何
-
DataJpaTest不创建架构
我有一个使用Spring Boot的中等规模项目,我正在尝试使用嵌入式H2创建我的第一个DataJpaTest,但我遇到了以下例外: 我已经尝试了这一点,并使用了一个模式。sql,还有这个和使用测试。测试/资源中的属性,以及其他答案。但什么都没用。我真的很困惑;这是我第一次在Spring Boot中遇到无法解决的问题。 我的实体类定义为: 关于如何强制Hibernate在H2中创建模式的任何建议?
-
ElasticSearch是否有架构?
本文向大家介绍ElasticSearch是否有架构?相关面试题,主要包含被问及ElasticSearch是否有架构?时的应答技巧和注意事项,需要的朋友参考一下 ElasticSearch可以有一个架构。架构是描述文档类型以及如何处理文档的不同字段的一个或多个字段的描述。Elasticsearch中的架构是一种映射,它描述了JSON文档中的字段及其数据类型,以及它们应该如何在Lucene索引中进行索
-
蓝牙框架结构
本文向大家介绍蓝牙框架结构,包括了蓝牙框架结构的使用技巧和注意事项,需要的朋友参考一下 蓝牙网络技术使用近距离的短波,超高频(UHF)无线电波无线连接移动设备,以形成个人局域网(PAN)。数据在蓝牙设备之间作为数据帧进行传输。定义了两种基本帧格式,用于以基本数据速率传输数据和用于以增强数据速率传输数据。 具有基本数据速率的蓝牙帧格式 具有基本速率的蓝牙帧包含三个部分,访问代码,标头和数据,如下图所
-
spark StructType的Avro架构
这实际上与我之前的问题相同,但使用Avro而不是JSON作为数据格式。 我正在使用一个Spark数据框架,它可以从几个不同的模式版本之一加载数据: 我正在使用Spark Avro加载数据。 它可能是版本一文件或版本二文件。但是我希望能够以相同的方式处理它,将未知值设置为“null”。我之前的问题中的建议是设置模式,但是我不想重复自己在文件中编写模式,也不想重复自己在和朋友中编写模式。如何将avro
-
Cassandra架构表建议
1)我应该能够通过addedtime进行范围查询,比如从x日期到y日期 2)我应该能够按appname查询,并使用addedtime按升序排列行 我怎样才能做到这一点?我可以更改表模式。 另外,我已经创建了两个DC和三个节点的Cassandra集群。
-
Cassandra表架构更改
我使用Datastax Cassandra3.0,同时使用cqlsh模式在cassandra中创建表,正在更改列名,列名按字母顺序排列。请看下面。 这是创建表时的结构。 ...每月一次的瓦尔查尔, ...分配int, ...evdate日期, ...paymentterms int, ...percentageofpayment int, ...变体int, ...paymenttermsumma
-
Databricks表/架构部署
目的 我们使用Databricks集群进行ETL流程,使用Databricks笔记本进行DS、ML和QA活动。 目前,我们不使用Databricks目录或外部Hive Metastore。我们以Spark StructType格式编程定义模式,并将路径硬编码如下: 表/some_table.py 我们时不时地进行一些重构,更改表的路径、模式或分区。这是一个问题,因为Database ricks是开
-
XML架构xs:choice inside xs:sequence
下面的XML是我试图验证的: 为了验证这个XML,我编写了以下XSD文件: 但一旦我上传文件并尝试使用以下w3网站验证它,我得到以下错误: 事先多谢。