《架构师》专题
-
为什么应用于图像切割的CNN一般都具有Encoder-Decoder架构?
本文向大家介绍为什么应用于图像切割的CNN一般都具有Encoder-Decoder架构?相关面试题,主要包含被问及为什么应用于图像切割的CNN一般都具有Encoder-Decoder架构?时的应答技巧和注意事项,需要的朋友参考一下 Encoder CNN一般被认为是进行特征提取,而decoder部分则使用提取的特征信息并且通过decoder这些特征和将图像缩放到原始图像大小的方式去进行图像切割。
-
C#安全地构建一个SQL字符串以使用实体框架执行
问题内容: 我正在通过命令使用EF执行一些SQL 。 我想确保我的sql字符串完全干净,因此逻辑方法是使用带有参数的对象来构建它。 但是我不想使用SqlCommand来执行它,我只是想让SqlCommand吐出一个可以插入到EF调用中的字符串。 有没有办法做到这一点,或者有另一种确保我不会注射的方法? 问题答案: EF是否不开箱即用? 您应该能够使用参数进行调用,因此它将像处理SQL注入一样处理:
-
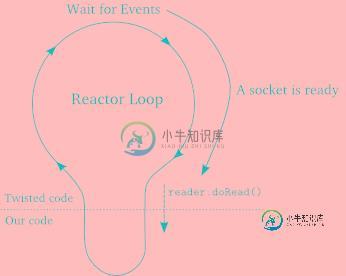 使用Python的Twisted框架构建非阻塞下载程序的实例教程
使用Python的Twisted框架构建非阻塞下载程序的实例教程本文向大家介绍使用Python的Twisted框架构建非阻塞下载程序的实例教程,包括了使用Python的Twisted框架构建非阻塞下载程序的实例教程的使用技巧和注意事项,需要的朋友参考一下 第一个twisted支持的诗歌服务器 尽管Twisted大多数情况下用来写服务器代码,但为了一开始尽量从简单处着手,我们首先从简单的客户端讲起。 让我们来试试使用Twisted的客户端。源码在twisted-
-
Thinkphp 框架基础之源码获取、环境要求与目录结构分析
本文向大家介绍Thinkphp 框架基础之源码获取、环境要求与目录结构分析,包括了Thinkphp 框架基础之源码获取、环境要求与目录结构分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Thinkphp 框架基础之源码获取、环境要求与目录结构。分享给大家供大家参考,具体如下: 获取ThinkPHP 获取ThinkPHP的方式很多,官方网站(http://thinkphp.cn)是最好的
-
 ASP.NET MVC5网站开发之业务逻辑层的架构和基本功能 (四)
ASP.NET MVC5网站开发之业务逻辑层的架构和基本功能 (四)本文向大家介绍ASP.NET MVC5网站开发之业务逻辑层的架构和基本功能 (四),包括了ASP.NET MVC5网站开发之业务逻辑层的架构和基本功能 (四)的使用技巧和注意事项,需要的朋友参考一下 业务逻辑层在Ninesky.Core中实现,主要功能封装一些方法通过调用数据存储层,向界面层提供服务。 一、业务逻辑层的架构 Ninesky.Core包含三个命名空间Ninesky.Core、Nine
-
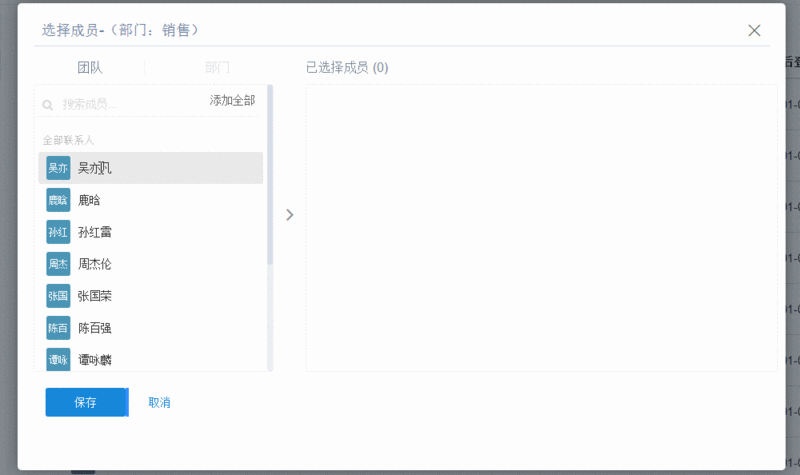 Vue.js递归组件实现组织架构树和选人功能案例分析
Vue.js递归组件实现组织架构树和选人功能案例分析本文向大家介绍Vue.js递归组件实现组织架构树和选人功能案例分析,包括了Vue.js递归组件实现组织架构树和选人功能案例分析的使用技巧和注意事项,需要的朋友参考一下 大家好!先上图看看本次案例的整体效果。 **浪奔,浪流,万里涛涛江水永不休。如果在jq时代来实这个功能简直有些噩梦了,但是自从前端思想发展到现在的以MVVM为主流的大背景下,来实现一个这样繁杂的功能简直不能容易太多。下面就手把手带您
-
如何获取另一个模型中定义的猫鼬数据库的架构
问题内容: 这是我的文件夹结构: 我在Songs.js文件中的代码 这是我在文件albums.js中的代码 我怎样才能让albums.js知道 SongSchema 被定义AlbumSchema 问题答案: 您可以直接使用Mongoose获取在其他地方定义的模型: 要在您的示例中通过albums.js获取架构,您可以执行以下操作:
-
如何在SQL Server 2008中限制用户访问仅一个架构的对象?
问题内容: 我想在SQL Server 2008中将用户限制为只有一个架构,并且只能在该架构中选择“选择”特权。 问题答案: DENY和GRANT的组合。例如:
-
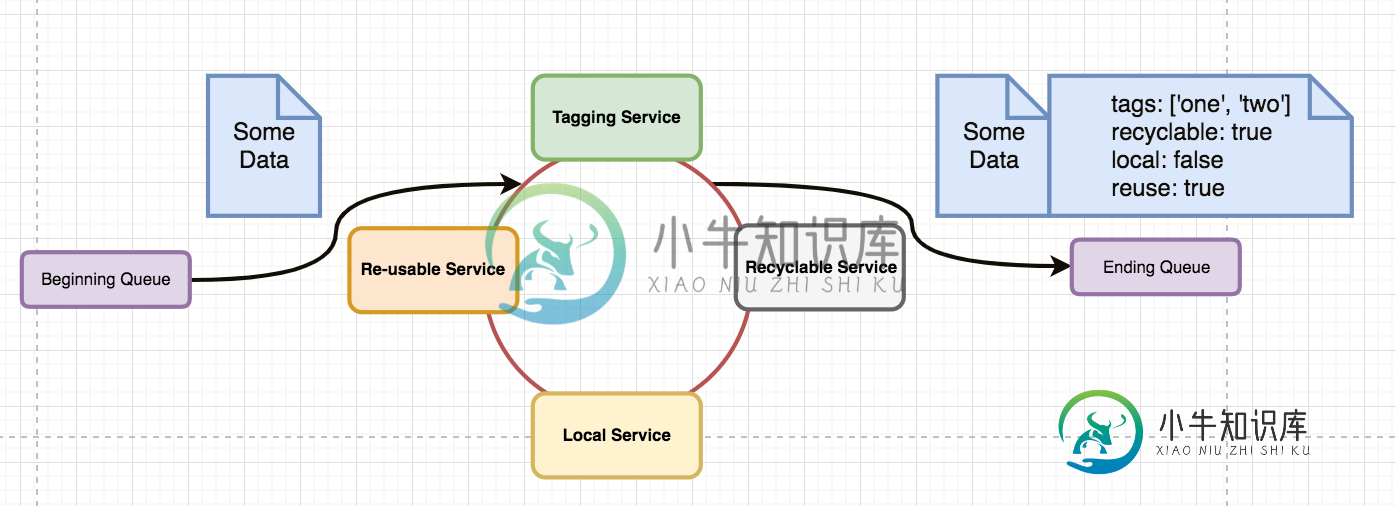 微服务架构-在顺序无关紧要时通过服务传递消息
微服务架构-在顺序无关紧要时通过服务传递消息tl;博士:“我如何通过一堆异步、无序的微服务推送消息,并知道该消息何时通过每个微服务?” 我正在努力为特定的微服务体系结构找到合适的消息传递系统/协议。这不是一个“哪个是最好的”问题,而是一个关于我的设计模式/协议选项的问题。 我在开始队列上有一条消息。假设带有序列化JSON的RabbitMQ消息 我需要该消息通过任意数量的微服务 这些微服务中的每一个都是长时间运行的,必须是独立的,并且可以用多
-
Kafka Avro Producer(kafka-avro-console-生产者)发送到kafka连接时的架构错误
我正在尝试使用kafka-avro-convore-生产者发布一条具有键(带有模式)和值(带有模式)的消息。kafka环境(kafka的conFluent 6.2.0版本、连接、zoomaster、模式注册表)都正确启动,我可以确认我的连接器已安装。问题是当我发送消息时,我的Sink连接器失败并出现我无法诊断的错误。 感谢您的帮助: 我生成一条AVRO消息,如下所示: 并在连接日志中接收以下错误:
-
如何用新的导航架构组件禁用导航中的某些片段?
null 在调用之前和之后,我尝试了,但都不起作用(这是有意义的:在它没有要弹出的内容之前;在它只关闭刚刚添加的片段之后)。这是否意味着唯一的方法是重写来拦截它,并确保在这些情况下不会被调用? 谢了!
-
如何将架构和一些数据从SQL Server复制到另一个实例?
问题内容: 我的产品使用SQL Server数据库- 每个客户端在自己的Intranet上都有自己的部署实例。该数据库大约有200个表。它们中的大多数是只有几行的配置表,但是有几个事务数据表可能有几百万行。通常,我需要对客户的配置问题进行故障排除,因此我需要他们的数据库的副本才能在我的开发系统上本地使用…但是由于交易数据的原因,该副本可能很大,这使得客户很难发送我可以备份。我需要一种方法来备份/复
-
组织。冬眠工具架构。spi。CommandAcceptanceException:执行DDL“创建表电影”时出错
我有一个spring boot应用程序,它在H2上运行sql以在启动期间创建数据库表。该项目位于github。 我有实体叫ovie.java 我运行的sql在github下面和上面- 我插入的csv文件在这里 当我运行Spring应用程序时,我得到以下错误- 在org.h2.engine.Pocal.prepare创建(Pocal.java:615)~[h2-2.1.210.jar: 2.1.21
-
在镶木地板数据上使用 Avro 架构动态创建 Hive 外部表
我正在尝试动态(不在Hive DDL中列出列名和类型)在镶木地板数据文件上创建一个Hive外部表。我有底层镶木地板文件的Avro模式。 我尝试使用以下DDL: 我的 Hive 表是使用正确的架构成功创建的,但是当我尝试读取数据时: 我得到以下错误: 有没有一种方法可以成功地创建和读取Parquet文件,而不用在DDL中提到列名和类型列表?
-
AVRO 架构演进 添加具有默认失败反序列化的可选列
在阅读avro文档时,例如[1],我了解到,支持模式演化,如果我添加了具有指定默认值的列,它应该是向后兼容的(当我再次删除它时,甚至是向前兼容的)。听起来不错,所以我添加了一个列,定义为: 并尝试从一开始就使用具有此架构的某个主题,它失败并显示消息: 提供更多的信息。Avro模式定义了一个顶级类型,具有2个字段。描述消息类型的字符串,以及N种类型的并集。可以读取所有N-1个未修改的类型,但是不能读