《架构师》专题
-
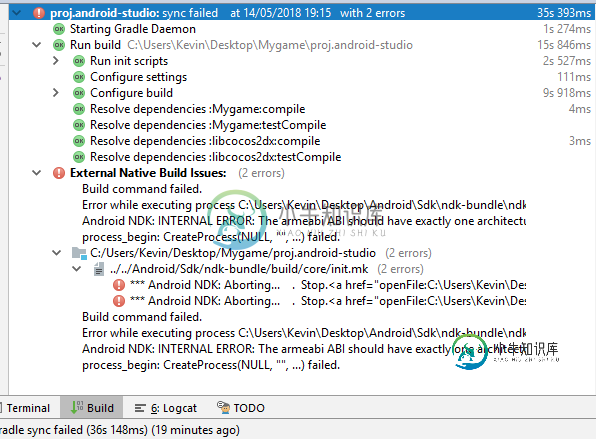 我的NDK项目由于CPU架构相关的问题而无法编译
我的NDK项目由于CPU架构相关的问题而无法编译有人能解释一下为什么我会出现这些错误吗?
-
即使我是数据库所有者,更改架构传输也会失败
我在GitHub上问过这个问题,但我认为我们可以把它变成一个更通用的问题,以便更快地获得一些有用的想法。首先,我在这里运行脚本,它显示我是db-owner组的成员。 这是在名为“自动编辑”的旧工具的安装脚本上。尽管存在以下问题,但我能够为特定表启用自动审核,并且它工作正常。 提供的脚本将一些存储的proc存储在带有我的用户名的模式下,然后稍后尝试将它们传输到“审计”模式。自动编辑概念和存储的过程实
-
当架构更新时,作用域“session”对当前线程不是活动的
我把它叫做: 也从这里打电话:
-
以编程方式添加安全方案时,架构从组件中消失
我最近从Springfox转换为Springdoc-openapi,以便为Spring Boot Rest API服务生成OpenAPI。 在我加了一个安全方案之前,一切都运行得很好。一旦我这样做了,我的计划就不再出现了,SwaggerUI页面上出现了一个错误: pom.xml的片段: 来自配置得代码段: 对我的v1组来说,一切都很好。我的模式出现在Swagger UI页面上,并且在生成的API-
-
关于SpringMVC如何使用@RequestMapping注释实现RESTfull架构的一些澄清
我正在学习Spring核心认证,我对SpringMVC如何处理REST网络服务有些怀疑。 阅读留档我发现了这个例子: 好的,它显示了2SpringMVC方法(我认为应该将其声明为控制器类,是真的吗)。 这些方法都处理对 /orders 资源的 HTTP 请求(根据 REST 样式,其中资源被视为管理一种数据和状态并提供此类处理的编程元素)。 在这种情况下,如果对 /订单的 HTTP 请求是 GET
-
 面经刺客 | 字节飞书基础架构产品 日常实习面经
面经刺客 | 字节飞书基础架构产品 日常实习面经是和我的背景非常非常match的技术产品,因此也抱有比较大的期待。但是可能因为面试时间拖得比较久,在hr面当天突然改为加一轮业务面,在这一轮业务面(三面)挂了。比较遗憾。 个人背景 深圳大学23届计算机本科+网络与新媒体双学位,准备留学申is/cs/ds研究生。 一段数据分析实习,主要做了几个内部工具,承担部分数据产品职能;若干零碎产品项目&用户研究经历;业余爱好是摄影、影视拍摄,恰过小钱。 职业
-
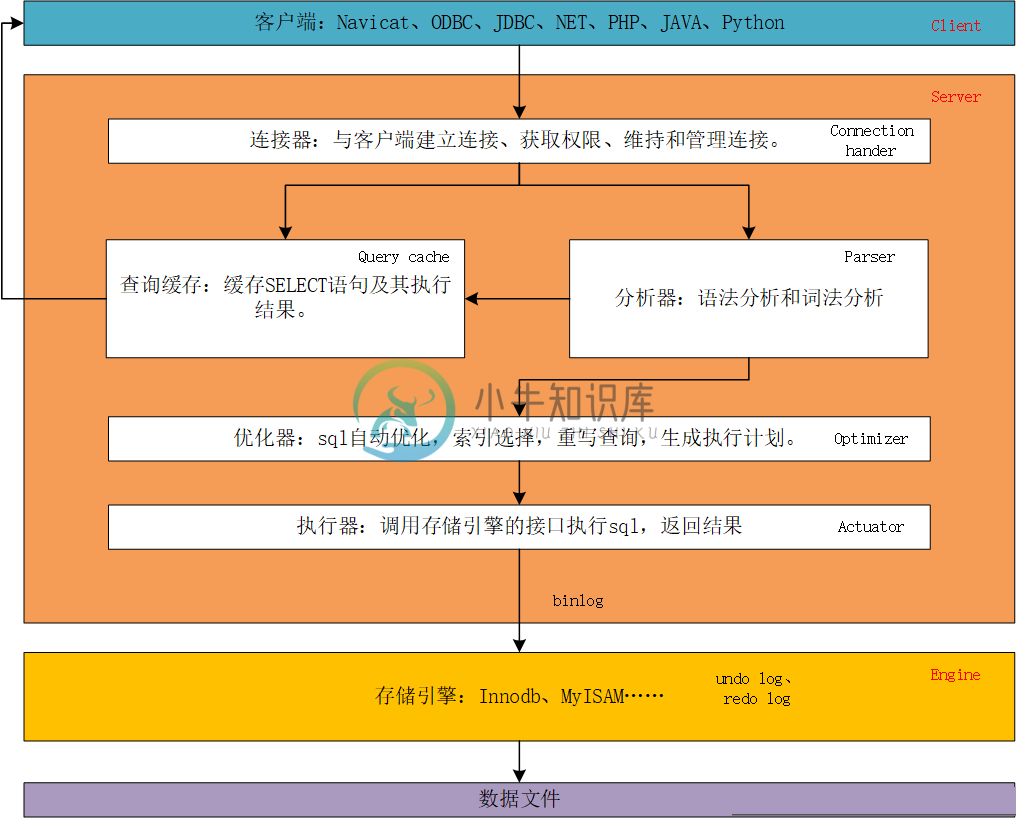 MySQL的基础架构以及一条查询sql语句的执行流程
MySQL的基础架构以及一条查询sql语句的执行流程主要内容:1 Mysql整体架构,2 连接器,2 查询缓存,4 分析器,5 优化器,5.1 索引选择的逻辑,6 执行器,7 一条查询sql的执行流程详细介绍了Mysql的基础架构以及一条查询sql的执行流程。 如果不想作为一个只能简单的写写sql工程师,而是想要深入的学习MySQL,那么我们有必要首先从宏观的角度来了解MySQL的整体架构,只有把握住了整体,才能深入细节。 面试中高级工程师的时候,常常被问到:一条sql语句在mysql中如何执行的?在学习了本文之后,你将会得到答案。 1 Mysq
-
浅谈laravel框架与thinkPHP框架的区别
本文向大家介绍浅谈laravel框架与thinkPHP框架的区别,包括了浅谈laravel框架与thinkPHP框架的区别的使用技巧和注意事项,需要的朋友参考一下 主要区别:(thinkPHP更适合国人的编码习惯) 1、渲染模版方式的不同: 在Laravel框架里,使用return view()来渲染模版; 而ThinkPHP里则使用了$this->display()的方式渲染模版; 2、在Lar
-
12. 项目框架搭建 - 12.2 框架设计
实现概要 koa2 搭建服务 MySQL作为数据库 mysql 5.7 版本 储存普通数据 存储session登录态数据 渲染 服务端渲染:ejs作为服务端渲染的模板引擎 前端渲染:用webpack2环境编译react.js动态渲染页面,使用ant-design框架 文件目录设计 demo源码 https://github.com/ChenShenhai/koa2-note/blob/master
-
DYLD:未为框架内的框架加载库
我正在尝试嵌入一个使用另一个框架的框架,这个框架在模拟器中工作得很好,但在iOS设备上会崩溃: DYLD:未加载库:@rpath/framework.framework/frameworkB引用自:/private/var/mobile/containers/bundle/application/b072cd7c-8595-4AE4-a506-26832a0f4402/frameworktest.
-
解构 - 结构体
类似地,解构 struct 如下所示: fn main() { struct Foo { x: (u32, u32), y: u32 } // 解构结构体的成员 let foo = Foo { x: (1, 2), y: 3 }; let Foo { x: (a, b), y } = foo; println!("a = {}, b = {}, y = {
-
微服务架构,用于频繁访问数据;在内存解决方案中?
问题内容: 让我们定义以下 用例 : 必须完成一个模拟任务,其中涉及[ day1,day2,…,dayN ]上的迭代/模拟。迭代的每个步骤都取决于先前的步骤,因此顺序是预先定义的。 任务具有由 Object1 表示的状态,该对象将在迭代的每个步骤中更改。 迭代步骤涉及2个不同的任务: Task1 和 Task2 。 为了完成 Task1 ,需要来自 Database1的 数据。 为了实现 Task
-
从会话工厂以编程方式获取休眠的默认架构名称?
问题内容: 我想知道是否可以通过某种方式从会话工厂获取默认架构名称?我需要得到它的原因是因为我必须使用一个本机SQL,并且我有多个会话工厂用于多个模式和一个数据源。所有生成的hibernate查询都由具有选择访问其他模式权限的单个用户运行。 问题答案: 我刚刚发现,hibernate具有{h-schema}替换项,可以在本机sql查询中使用。因此,当您连接到oracle数据库中的一个架构并希望针对
-
如何制作同时支持 32 位和 64 位架构的 Android 应用程序?
我刚刚收到并阅读了Google Play的时事通讯,其中提到从明年开始,该商店“将要求具有本机库的新应用程序和应用程序更新除了32位版本外还提供64位版本”。 对于那些还没有读过的人来说,它指出: 2019年64位支持需求 Android 5.0 中引入了对 64 位架构的平台支持。如今,超过40%的Android设备上线支持64位,同时仍保持32位兼容性。对于使用本机库的应用,64 位代码通常提
-
 字节跳动基础架构后端开发面经(春招实习-已转正)
字节跳动基础架构后端开发面经(春招实习-已转正)我也来回馈一下牛客的uu们吧 本人2023届某末流985硕…… 字节跳动基础架构后端实习一二三面 基础架构后端实习一面(36min / 3.18日) 自我介绍 面试问题 STL中的容器的底层实现,简单讲几个(简单讲了vector,array,unordered_map) unordered_map与map的底层实现的区别 Linux中的哪些troubleshooting工具? GDB用法?如何用G