《架构师》专题
-
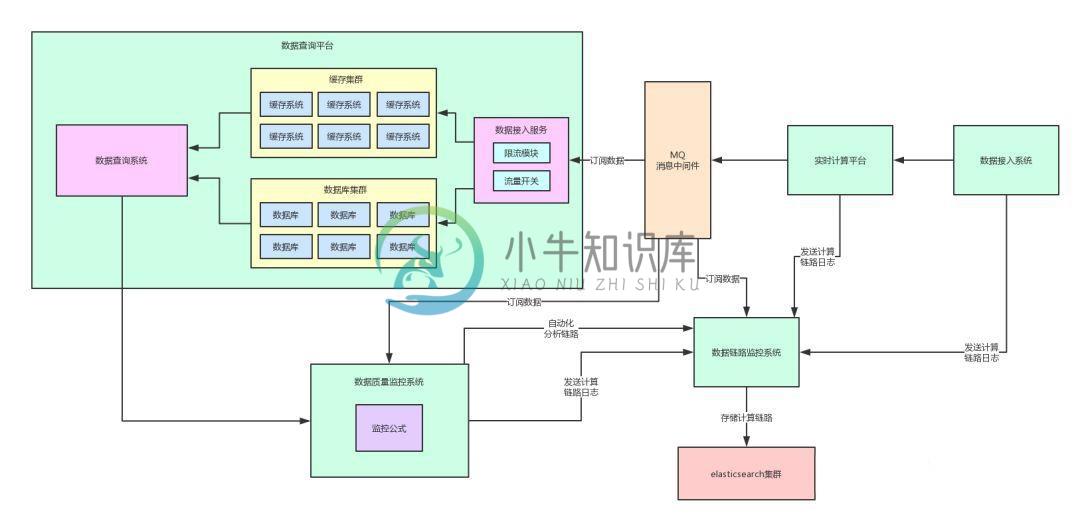 关于订阅场景的架构设计
关于订阅场景的架构设计主要内容:一、前情提示,二、选择性的订阅部分核心数据,三、RabbitMQ的queue与exchange的绑定,四、direct exchange实现消息路由,五、按需订阅的代码实现,六、更加强大而且灵活的按需订阅一、前情提示 上一篇文章《你以为架构师天天就画图写PPT吗,告诉你其他事儿多了去了~》,我们已经给出了一整套的数据一致性的保障方案。 我们从如下三个角度,给出了方案如何实现。并且通过数据平台和电商系统进行了举例分析。 核心数据的监控 数据链路追踪 自动化数据链路分析 目前为止,我们的架
-
第一天 Android架构与环境搭建
第一天 Android架构与环境搭建 1.1 android基础 1.1.1 Android是什么? 是一个针对移动设备的操作系统和软件平台 基于Linux内核 由 Google和开放手机联盟OHA开发的 容许使用Java语言来开发和管理代码 Android开放源代码,Android遵从Apache Software License (ASL)2.0版本的协议 Android于2007年11月5日
-
架构原理 - 自动发现的配置
ES 是一个 P2P 类型(使用 gossip 协议)的分布式系统,除了集群状态管理以外,其他所有的请求都可以发送到集群内任意一台节点上,这个节点可以自己找到需要转发给哪些节点,并且直接跟这些节点通信。 所以,从网络架构及服务配置上来说,构建集群所需要的配置极其简单。在 Elasticsearch 2.0 之前,无阻碍的网络下,所有配置了相同 cluster.name 的节点都自动归属到一个集群中
-
3. 迁移指南 - 3.1 分解原架构
在和客户讨论分解数据、服务和团队后,客户经常向我提出这样的问题,“太棒了!但是我们要怎样实现呢?”这是个好问题。如何拆分已有的单体应用并把他们迁移上云呢? 事实证明,我已经看到了很多成功的例子,使用增量迁移这种相当可复制的模式,我现在向我所有的客户推荐这种模式。SoundCloud和Karma就是公开的例子。 本节中,我们将讲解如何一步步地将单体服务分解并将它们迁移到云上。 新功能使用微服务形式
-
中间件及架构 - MAVLink消息机制
translated_page: https://github.com/PX4/Devguide/blob/master/en/middleware/mavlink.md translated_sha: 95b39d747851dd01c1fe5d36b24e59ec865e323e MAVLink消息 所有消息的概述可以在这里找到. 创建自定义MAVLink消息 这篇教程是假设你已经在 msg/
-
中间件及架构 - uORB消息机制
translated_page: https://github.com/PX4/Devguide/blob/master/en/middleware/uorb.md translated_sha: 18f5865bf5265934136cf5d18f838203c3db2100 uORB消息机制 简介 uORB是一种用于线程间/进程间进行异步发布-订阅的消息机制的应用程序接口(API)。 在这个教
-
总体介绍 - 多层次架构体系
1.2 ABP总体介绍 - 层架构体系 1.2.1 前言 为了减少复杂性和提高代码的可重用性,采用分层架构是一种被广泛接受的技术。为了实现分层的体系结构,ABP遵循DDD(领域驱动设计)的原则,将工程分为四个层: 展现层(Presentation):向用户提供一个接口(UI),使用应用层来和用户(UI)进行交互。 应用层(Application):应用层是表现层和领域层能够实现交互的中间者,协调业
-
 腾讯 云架构测开一面凉经
腾讯 云架构测开一面凉经第一次面,还是准备不太充分了😮💨 1.自我介绍 2. 讲项目和自己负责的部分,反问并介绍了一下,可能感觉没什么技术点后面就没问了 3.开始问绩点和基础知识 问了计网的问题OSI模型,TCP/IP 和传输层的作用 问了 Java 有哪些数据结构还有一个忘记了 4.开放性测试问题:一个电梯交付了从哪方面进行测试 5.手撕代码20 分钟,没跑出来但是讲了下思路他陷入了沉思然后解释了 6.最后反问
-
 24提前批 抖音 推荐架构 C++
24提前批 抖音 推荐架构 C++23 年 8 月面的 自我介绍 列式存储的优势 被问烂了 主流列式数据库,主流使用场景 列式存储压缩算法(lz4、snappy、zstd区别) https://bbs.huaweicloud.com/blogs/detail/278702 RAII怎么使用的 你的性能提升来自于哪里 c++类型转换static_cast和dynamic_cast dynamic_cast可以把子类指针转父类吗 ht
-
 架构与思维 系统容量设计
架构与思维 系统容量设计主要内容:1.分析过程,2.系统容量评估时机,3.评估的步骤,4.案例说明,5.总结何为设计容量,从技术上说就是运用一些策略对系统容量进行预估的过程。 数据量、并发量、带宽、注册用户规模、活跃用户规模、在线用户规模、消息长度,图片大小、网盘空间容量,内存CPU容量等。 1.分析过程 TPS(Transactions Per Second):每秒事务数 QPS(Query Per Second):每秒请求数,QPS其实是衡量吞吐量的一个常用指标,就是说服务器在一秒的时间内处理了多少
-
架构与思维 系统容量设计
主要内容:1.分析过程,2.系统容量评估时机,3.评估的步骤,4.案例说明,5.总结何为设计容量,从技术上说就是运用一些策略对系统容量进行预估的过程。 数据量、并发量、带宽、注册用户规模、活跃用户规模、在线用户规模、消息长度,图片大小、网盘空间容量,内存CPU容量等。 1.分析过程 TPS(Transactions Per Second):每秒事务数 QPS(Query Per Second):每秒请求数,QPS其实是衡量吞吐量的一个常用指标,就是说服务器在一秒的时间内处理了多少
-
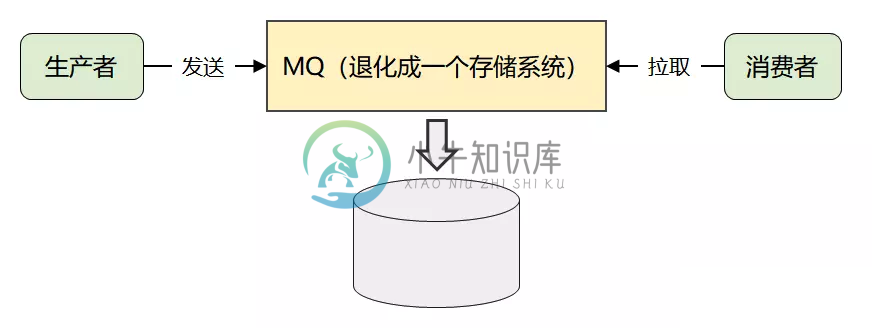 Kafka高性能设计之架构设计
Kafka高性能设计之架构设计主要内容:1.Kafka 的技术难点,2.Kafka 架构设计,3.Kafka的宏观架构设计,4.Kafka 的整体架构1.Kafka 的技术难点 Kafka 为实时日志流而生,要处理的并发和数据量非常大。可见,Kafka 本身就是一个高并发系统,它必然会遇到高并发场景下典型的三高挑战:高性能、高可用和高扩展。 为了简化实现的复杂度,Kafka 最终采用了很巧妙的消息模型:它将所有消息进行了持久化存储,让消费者自己各取所需,想取哪个消息,想什么时候取都行,只需要传递一个消息的 offset 进行
-
 soul推荐架构oc,终于有offer了
soul推荐架构oc,终于有offer了时间线: ---------------- 9.14 一面 总时长:27min 1. 算法题:力扣148:合并链表 2. 简单介绍一下项目 3. 项目是否上线? 4. 说说你项目的一些亮点 5. 线程池的核心参数(7个)?核心线程满了会怎么样? 6. 说一说锁升级过程? 7. 缓存击穿、穿透、雪崩?怎么解决? 8. AOP怎么实现的? 9. 分布式锁有哪些使用场景?怎么实现一个分布式锁? 10.
-
无服务器框架请求验证程序架构:如何不接受json架构中未包含的对象键和值对?
Im使用请求验证器模式来验证传入的post请求- 测验json文件: 无服务器.yml 文件: 没关系,当属性“名称”不包含在post请求中时,它正在验证,但是正如您在我的json文件中看到的,属性中只有名称。当我包含像- 我想要的只是我在test.json文件上设置的键和值对才会被接受。我还没有看到任何关于json架构的文档,希望它有一个替代的解决方案。
-
Flyway:找到非空架构“public”,没有架构历史记录表!在空数据库上使用baseline()
我正在尝试使用kotlin Spring Boot、jpa和postgreSQL配置flyway。我的gradle依赖项是: 我的application.properties文件是: 使用jpa和hibernate创建表和条目按预期工作。但是,在空数据库上进行示例迁移会导致: 我的目录结构是spring Initializer生成的默认目录结构,我的迁移位于: