《大数据》专题
-
 歌尔大数据秋招
歌尔大数据秋招#歌尔# 项目 ETL部分 拉链表的设计与作用 数据量的大小 为什么选择kmeans,介绍一下其他的聚类方法 八股 介绍下数据仓库的分层 大数据中的数据倾斜 hive开窗函数 spark streaming和flink的区别 sort by 和 order by的区别 有没有用过doris等 (没用过) 什么时候可以来实习
-
 百度 大数据一面
百度 大数据一面自我介绍 实习工作介绍 事实表与维度表如何搭建 星型模型与雪花模型 维度冗余 业务场景理解 数据倾斜原因和常见手段 手撕 一道sql: 连续登录7天用户 两道算法: 二维动态规划 n! 尾数0的个数
-
 星环科技 大数据
星环科技 大数据项目 垃圾回收,JVM调优 Elasticsearch 结构 索引 集群分片 redis 数据结构 mysql优化,事务 ,索引,MVCC 聊天
-
 百度大数据一面
百度大数据一面4.27 1h B2B,百度电商部门 介绍完自己直接开始写算法题 随机数据的峰值,如 1 2 3 6 5 8 7,返回 6 或 8都行,要求时间复杂度O(lgN) 斐波那契数列,要求时间复杂度O(lgN),矩阵解法 求两个字符串的最长公共子串,如 abcedfgh 和 bcedgh 最长公共子串是bced 求两个字符串的最长公共子序列,如 abcedfgh 和 bcedgh 最长公共子序列是bce
-
从多维数组中放大数据
问题内容: 我是PHP的新手,我需要针对以下问题的快速解决方案,但似乎无法提出一个解决方案: 我有一个像这样的多维数组 我想使用来以某种方式返回包含逗号的字符串分隔字符串,像这样。 通过上述功能有可能达到这种效果吗?如果没有,请提出替代解决方案。 问题答案: 非常简单: 以及php v5.5.0中的新功能:
-
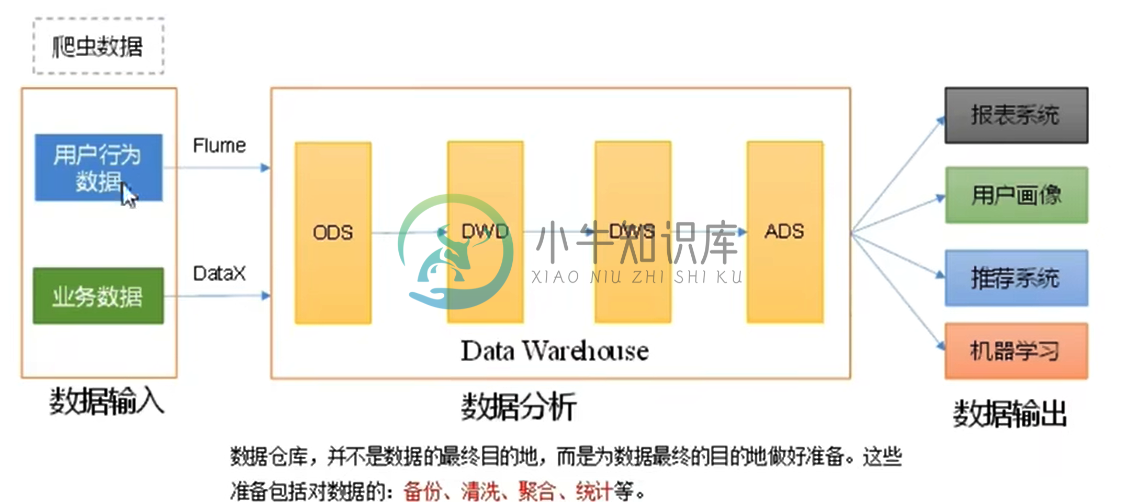 大数据平台之数据存储
大数据平台之数据存储主要内容:1.大数据生态技术,2.数据存储,3.数据存储的发展,4.数据存储的方式1.大数据生态技术 数据存储处理: 清洗, 关联, 规范化, 组织建模, 通过数据质量的检测, 数据分析然后提供相应的数据服务 离线数仓: 实时数仓: 以Kafka, cancal/Maxwell/FlinkCdc为区分, 离线数仓为Hive, Sqoop 实时数仓:分层: Ods, Dwd, Dim, Dwm, Dws, Ads 离线数仓分层: Ods. Dwd, Dws, Dwt, Ads 实
-
Spring数据排序操作超出最大大小
我是相当新的Spring和MongoDB,并有一个问题,从我的MongoDB拉数据。我试图获得相当大的数据量,并收到以下异常: 执行器错误:操作失败:排序操作使用超过最大33554432字节的RAM。添加索引,或指定一个较小的限制。;嵌套异常是com.mongodb.MongoExc0019: Execator错误:操作失败:排序操作使用超过内存的最大33554432字节。添加索引,或指定较小的限
-
Neo4j查找数据库的最大字节大小
我找到了关于如何计算neo4j数据库大小的以下信息:https://neo4j.com/developer/guide-sizing-and-hardware-calculator/#_disk_storage
-
加载大于 h2o 中内存大小的数据
我正在尝试在h2o中加载大于内存大小的数据。 H2o博客提到: 下面是连接到h2o 3.6.0.8的代码: 给 我试着把一个169 MB的csv加载到h2o中。 这抛出了一个错误, 这表示内存溢出错误。 问:如果H2opromise加载大于其内存容量的数据集(如上面的博客引述所说的交换到磁盘机制),这是加载数据的正确方法吗?
-
JavaScript中数组的最大大小
问题内容: 上下文:我正在构建一个读取rss feed并在后台更新/检查feed的小站点。我有一个数组来存储要显示的数据,另一个数组来存储已显示的记录的ID。 问题:在事情变慢或变慢之前,数组可以在Javascript中容纳多少个项目。我没有对数组进行排序,但是正在使用jQuery的inArray函数进行比较。 该网站将保持运行状态,并进行更新,并且不太可能经常重启/刷新浏览器。 如果我想从数组中
-
Java数组有最大大小吗?
问题内容: Java数组可以包含的元素数量是否有限制?如果是这样,那是什么? 问题答案: 即使测试很容易,也没有找到正确的答案。 在最新的HotSpot VM中,正确的答案是。一旦超出此范围: 你得到:
-
大摇大摆的模式数组
thoses线有什么问题 “data”属性应该是$ref中给出的模式类型的数组,但这是结果 好的,似乎正确的方法是tu把$ref直接放在items键下,我的问题是使用保留键“status”,那么,我如何在对象模式中使用保留键呢? 在我的客户机模式中,我将属性status放了两次,但我没有看到它已经存在,所以当我更改属性名时,它起作用了,我在想“status”可能是一个保留的关键字。
-
了解TCP数据包大小限制和UDP数据包大小限制
我正在使用在我的客户端应用程序中执行以及 最大数据包大小限制也存在于中,即?但是我可以使用中的发送大于最大数据包大小的数据块 这是怎么运作的?这是因为是基于流的,负责在较低层创建数据包吗?有什么方法可以增加UDP中的最大数据包大小吗? 当我在客户端读取时,我从服务器端发送的UDP数据包的一些字节是否可能丢失?如果是,那么有没有办法只检测UDP客户端的损失?
-
Elastic search不提供大量的页面大小数据
问题内容: 要获取的数据大小:大约20,000 问题:在python中使用以下命令搜索Elastic Search索引数据 但没有得到任何结果。 如果我给的尺寸小于或等于10,000,则可以正常使用,但不能与20,000一起使用, 请帮助我找到最佳的解决方案。 PS:在深入研究ES时发现此消息错误: 结果窗口太大,从+大小必须小于或等于:[10000],但为[19999]。有关请求大数据集的更有效
-
加载大于h2o中的内存大小的数据
问题内容: 我正在尝试加载大于h2o中的内存大小的数据。 H2o 博客提到: 这是连接到的代码: 给 我试图将169 MB的csv加载到h2o中。 这引发了错误, 这表示内存不足错误。 问题:如果H2o承诺加载大于其内存容量的数据集(如上面的博客引文所述,交换到磁盘机制),这是加载数据的正确方法吗? 问题答案: 由于性能太差,默认情况下前一会默认禁用“交换到磁盘”。流血边缘(不是最新稳定的)具有启