《大数据》专题
-
UDP数据包大小和数据包丢失
我一直在写一个程序,它使用UDP上的停止和等待协议通过局域网和广域网发送数据包。我最近一直在测试我的程序,并注意到较大的数据包(接近64k字节)的丢包率更高。直觉上这是有道理的,但实际原因是什么?
-
如何从PHP大数组中获取数据
我有一个包含玩家数据的数组。这个数组根据玩家的数量而变化。数组看起来像这样: 我只想从每个玩家的数组中获取玩家名。我该怎么做?输出应该是如下所示的字符串:我在Internet或YouTube上没有找到任何内容。答案当然简单明了,但我还没有找到。 Im使用PHP 8.0.13。
-
适用于大型数据库的数据库?
问题内容: 我正在进行的一个项目在不久的将来可能会跨越几百万行,所以我正在研究我使用的数据库,因为这肯定会证明是一个问题。据我所读,一旦涉及到表的2,000,000行问题,SQL的所有形式都会出现问题。对于这些大型项目,有没有推荐好的数据库? 我正在谈论的是一个网站,归档旧条目并不理想,但是如果证明这是我无法克服的问题,则可以这样做。 谢谢。 问题答案: 我已经在MS SQL Server中使用了
-
批量插入大量数据到数据库
我创建了一个向MySql数据库插入数百万个值的程序。我读到过有关批插入的文章,它将优化我的程序并使其更快,但当我尝试这样做时,它以同样的方式工作。我没有将每个值插入数据库,而是每次将500个值保存在一个列表中,然后将它们插入一个大循环中,如下所示: 然后我删除列表中的所有值,并再次开始收集500个值。它不应该工作得更好吗? 我的插入代码是: 我有一些问题: 1。为什么当我批量插入时它不能更快地工作
-
 Zoom 0810数据方向笔试 大数据 2022.8.10
Zoom 0810数据方向笔试 大数据 2022.8.10选择题:25题 考试内容有SQL语句,数据库,spark(包括给你一段spark程序让你输出结果),hive,数学(概率论的一些东西) 编程题:两题 1.算法题:一个数=x平方+y平方+z平方,求有多少质数满足这个条件(具体记不清了,大概是这样) 2.sql题:给你日期和工资,求平均涨薪幅度和平均涨薪时间(思路是使用lead窗口函数,然后两列相减) 总结:第一次考试,选择题花了50分钟,一定要把选
-
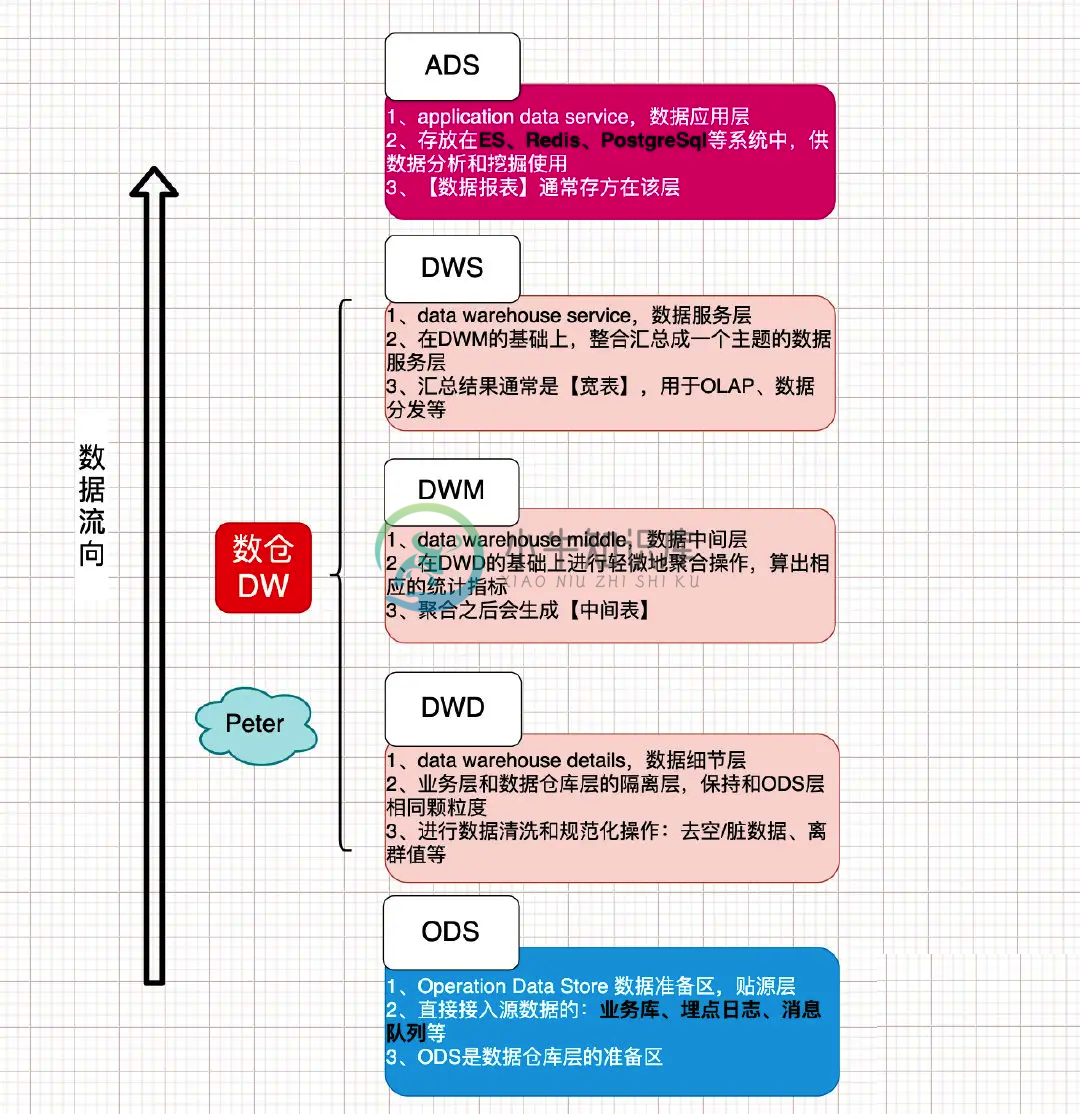 大数据数仓高级面试题【8道】
大数据数仓高级面试题【8道】主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
为什么H2数据库文件大小的增长超过了数据大小
我有一个h2数据库文件,文件大小已经增长到5GB。我删除了一些数据以缩小文件的大小。但即使从数据库中删除了一半记录,文件大小仍然保持不变。 我已经尝试了以下所有选项来减少数据库大小,但没有一个对我有用。 我的连接字符串如下所示: 注: 我们正在结清我们已经开始的交易 文件中没有5GB的数据 有人能给我建议一些解决方法或修复方法来减少我的数据库大小吗
-
_GET中的URL参数的最大大小
问题内容: 我正在使用REST访问PHP服务器:所有数据都作为URL参数在GET请求中传递。参数之一以query_string到达服务器,但不在_GET全局中。但是,缩短参数(截止值似乎是512个字符左右)可以让它通过。 假设我已正确诊断问题,是否可以更改此最大大小?我在文档中没有找到任何解释,甚至没有提及此限制。这是在Debian挤压/ Apache 2.2.16 / PHP 5.3.3上。 问
-
大数上的最大素因子失败
我在研究Euler项目的问题,这是问题五: 最大素因子问题3 13195的素因子为5、7、13和29。 600851475143的最大质因数是什么? 我得到了工作代码: 因数(19*19*19*19*19*19*19*19*19*1999989899) x=33170854034208712,最后一个系数=182128674 33170854034208712 有人知道为什么这没有得到正确的答案吗
-
Thymeleaf开关为整数,大小写大于
我在data-th-case=“${gt6}”上得到一个错误。在Thymeleaf有办法做到这一点吗? 提前谢了。
-
 上海银行大数据开发(数仓)数据一面
上海银行大数据开发(数仓)数据一面离线数仓项目介绍 hdfs读流程 hdfs 中datanode怎么与namenode交互 mr过程 hive数据倾斜,介绍原因和解决方案 介绍一下网络结构,tcp在哪一层 java有哪些集合类 介绍java接口 MySQL索引 数据结构(B+树) 反问 上海银行数仓技术框架
-
pytorch下大型数据集(大型图片)的导入方式
本文向大家介绍pytorch下大型数据集(大型图片)的导入方式,包括了pytorch下大型数据集(大型图片)的导入方式的使用技巧和注意事项,需要的朋友参考一下 使用torch.utils.data.Dataset类 处理图片数据时, 1. 我们需要定义三个基本的函数,以下是基本流程 这里,我将 读取图片 的步骤 放到 __getitem__ ,是因为 这样放的话,对内存的要求会降低很多,我们只是将
-
弹性搜索未提供大量的页面大小数据
问题内容: 要获取的数据大小:大约20,000 问题:在python中使用以下命令搜索Elastic Search索引数据 但没有得到任何结果。 如果我给的尺寸小于或等于10,000,则可以正常工作,但不能与20,000相匹配, 请帮助我找到最佳的解决方案。 PS:在深入研究ES时发现此消息错误: 结果窗口太大,从+大小必须小于或等于:[10000],但为[19999]。有关请求大数据集的更有效方
-
mysql 大表批量删除大量数据的实现方法
本文向大家介绍mysql 大表批量删除大量数据的实现方法,包括了mysql 大表批量删除大量数据的实现方法的使用技巧和注意事项,需要的朋友参考一下 问题参考自:https://www.zhihu.com/question/440066129/answer/1685329456 ,mysql中,一张表里有3亿数据,未分表,其中一个字段是企业类型,企业类型是一般企业和个体户,个体户的数据量差不多占50
-
infinispan文件存储大小与数据大小不成比例
我编写了一个小型infinispan缓存PoC(下面的代码),以尝试评估infinispan的性能。运行它时,我发现对于我的配置,infinispan显然无法从磁盘中清除缓存项的旧副本,导致磁盘空间消耗比预期的要多几个数量级。 如何将磁盘使用率降低到实际数据的大致大小? 以下是我的测试代码: 这是infinispan配置: Infinispan(应该是?)配置为写入缓存,其中包含RAM中的20个最