《大数据》专题
-
 科大讯飞 大数据工程师 一面凉经
科大讯飞 大数据工程师 一面凉经笔试过了一个月给捞起来了 一面 45min 1. 自我介绍 2. 细聊项目,很细(一上来就忘了数据量,尴尬) 3. 特征工程怎么做的 4. iv值的计算方法 5. AUC的计算方法 6. 正反例不平衡对auc有影响吗 7. 知道过拟合吗 8. 逻辑回归怎么解决过拟合问题 9. 写个函数指针 10. pandas库有哪些数据类型 11. 怎么取两个dataframe有差异的部分(忘了具体函数了,讲了
-
复数的大小
我正在做一个关于复数的项目,来解释更多(a+bi),其中“a”是复数的实部,“b”是它的虚部。(a和b是实数但“i”不是) 我很难实现一个大小方法,而不是返回一个实数,作为一个双倍,我得到无穷大。 这就是我正在尝试实现的内容:(a+bi)=√(a^2+b^2) 我的代码片段 假设实数和虚数都是double.max_value。为什么mag会返回无穷大而不是1.8961503816218352 E1
-
大整数加法
题目描述 输入2个大正整数(长度可能达到1000位),求两者之和。 输入格式: 测试数据有多组,处理到文件尾。每组测试数据输入两个正整数A和B。 输出格式: 对于每组测试,在一行上输出A+B的结果。 输入样例: 2222222222 44444444444 输出样例: 46666666666 解题代码 #include<iostream> #include<string> using namesp
-
数组最大值
问题 你需要找出数组中包含的最大的值。 解决方案 你可以使用 JavaScript 实现,在列表推导基础上使用 Math.max(): Math.max [12, 32, 11, 67, 1, 3]... # => 67 另一种方法,在 ECMAScript 5 中,可以使用 Array 的 reduce 方法,它与旧的 JavaScript 实现兼容。 # ECMAScript 5 [12,
-
 兴金数金,大数据实习面经
兴金数金,大数据实习面经一,上来就问了项目里日志的处理量,50w 100M左右 二,问项目里如何解决Hbase的热点问题,面试官没听明白,后面就直接问热点问题如何解决的 答的就举年份例子,加盐,预分区 三,Kafka里是如何leader和follow是如何实现同步的 具体怎么实现同步我确实不知道,我就答的是offset在follow和leader挂了后如何在实现同步的,面试官说我似乎说了又没说明白,后面查了一下,下
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
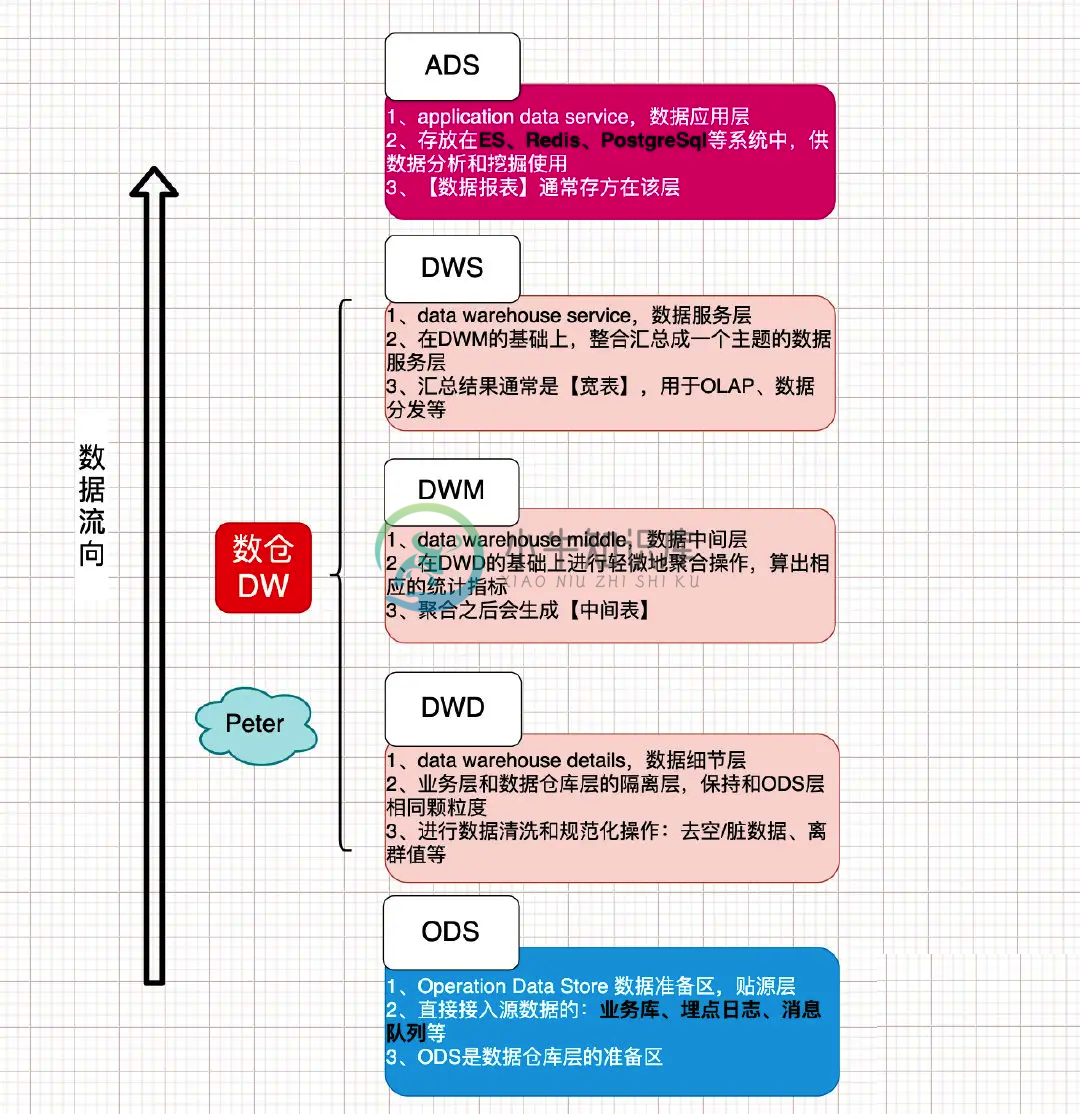 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
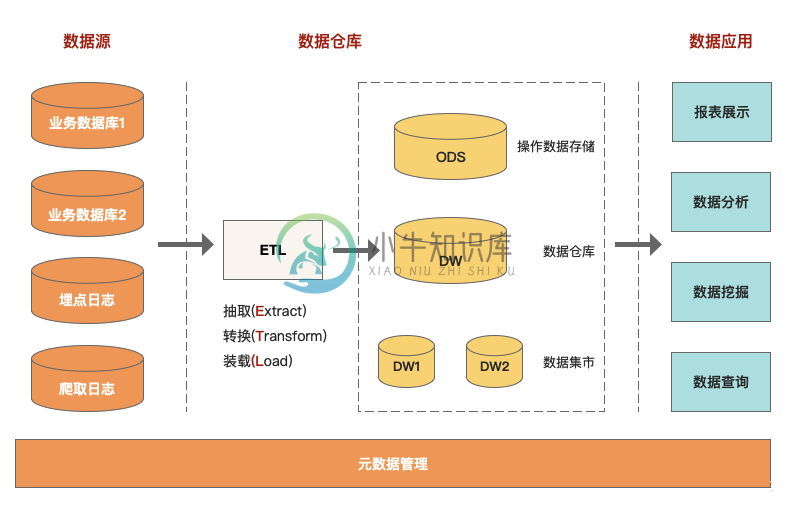 大数据数仓高级面试题 2
大数据数仓高级面试题 2主要内容:1、什么是数据仓库?,2、数据仓库和数据库的区别?,3、如何构建数据仓库?,4、什么是数据中台?,5、数据中台、数据仓库、大数据平台、数据湖的关键区别是什么?,6、大数据有哪些相关的系统?,7、如何建设数据中台?,8、数据仓库最重要的是什么?,9、概念模型、逻辑模型、物理模型分别介绍一下?,10、SCD常用的处理方式有哪些?,11、怎么理解元数据?,12、数仓如何确定主题域?,13、如何控制数据质量?,,,,1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、
-
 快手数据研发一面(大数据、数仓、数开)
快手数据研发一面(大数据、数仓、数开)项目为sgg经典离线数仓 1. 自我介绍 2. 项目介绍(难点、亮点) 3. 根据难点亮点提问 4. 数据域是什么,如何划分数据域,为什么这样划分数据域 5. DIM层维度表的设计原则 6. DWD层事实表设计要点 7. mapreduce shuffle流程 8. maptask和reduce task 与哪些因素有关 9. 数据热点(数据倾斜)在哪些场景下出现,如何解决 10. spark是为
-
 SqlServer 数据库 三大 范式
SqlServer 数据库 三大 范式本文向大家介绍SqlServer 数据库 三大 范式,包括了SqlServer 数据库 三大 范式的使用技巧和注意事项,需要的朋友参考一下 1 概述 一般地,在进行数据库设计时,应遵循三大原则,也就是我们通常说的三大范式,即第一范式要求确保表中每列的原子性,也就是不可拆分;第二范式要求确保表中每列与主键相关,而不能只与主键的某部分相关(主要针对联合主键),主键列与非主键列遵循完全函数依赖关系,
-
neo4j中的大数据导入
我正在导入大约1200万个节点和1300万个关系的数据。 是否可以在短时间内直接从sql导入这些数据,因为neo4j以其快速处理大数据而闻名?有什么建议或帮助吗? 以下是CSV使用的加载(数字上的索引(num)):
-
Postgres数据库大小命令
查找所有数据库大小的命令是什么? 我可以使用以下命令找到特定数据库的大小:
-
 蔚来大数据笔试 7.17
蔚来大数据笔试 7.17第一题合并两个二叉树lc617 第二题爬楼梯,多少种爬法,10000级楼梯 第三题滑动窗口的最大值lc239 #蔚来提前批笔试#
-
 京东方大数据面试
京东方大数据面试7.22一面 spark的底层原理 spark yarn client和yarn cluster的区别 dataframe如何创建 数仓项目中用了几个节点,各个组件如何部署的 HA介绍一下 数仓分层介绍 hadoop的一些命令 hadoop如何更改文件所有者 kafka的监控 linux命令,vim编译器的命令 集群间节点是如何通信的 core-site文件一般配置什么内容 ranger权限管理的