《大数据》专题
-
大数据
Kubernetes community中已经有了一个Big data SIG,大家可以通过这个SIG了解kubernetes结合大数据的应用。 在Swarm、Mesos、kubernetes这三种流行的容器编排调度架构中,Mesos对于大数据应用支持是最好的,spark原生就是运行在mesos上的,当然也可以容器化运行在kubernetes上。当前在kubernetes上运行大数据应用主要是sp
-
pandas数据框的最大大小
问题内容: 我试图使用s或函数读取稍大的数据集,但我一直遇到s。数据框的最大大小是多少?我的理解是,只要数据适合内存,数据帧就应该可以,这对我来说不是问题。还有什么可能导致内存错误? 就上下文而言,我试图在《2007年消费者金融调查》中阅读ASCII格式(使用)和Stata格式(使用)。该文件的dta大小约为200MB,而ASCII的大小约为1.2GB,在Stata中打开该文件将告诉我,对于22,
-
 科大讯飞大数据一面
科大讯飞大数据一面#科大讯飞求职进展汇总##春招# 面试官人很好,还挺帅(有点像shy哥? 全程拷打简历,会重点问实习和2个左右项目 本来我在不断引导面试官问我数据库和机器学习方面的内容,但是面试官好像不怎么想问,连数据怎么清洗的这种都没问,就问了聚类了解那些?k-means聚类怎么优化?肘部法则和肘部加速的区别? 由于我项目大都是deep learning方向的,所以都在让我讲dl方向的东西 还有就是项目遇到了哪
-
FIELDDATA数据太大
问题内容: 我打开kibana并进行搜索,但出现碎片失败的错误。我查看了elasticsearch.log文件,然后看到此错误: 有什么办法可以增加593.9mb的限制? 问题答案: 您可以尝试在配置文件中将fielddata断路器的限制提高到75%(默认值为60%),然后重新启动集群: 或者,如果您不想重启群集,则可以使用以下方法动态更改设置: 试试看。
-
大数据与 MapReduce
大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力。 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则随意浏览后就离开。 对于你来说,可能很想识别那些有购物意愿的用户。 那么问题就来了,数据集可能会非常大,在单机上训练要运行好几天。 接下来:我们讲讲 MapRedece 如何来解决这样的问题 MapRedece Hadoop 概述 Had
-
 歌尔大数据
歌尔大数据自我介绍 数仓分层 为什么分层 为什么建模 星型模型,雪花模型 数据库的三范式 范式建模和维度建模的区别,优缺点 如果给你一个任务,一个月完成,你怎么规划 反问 oc
-
 博世大数据
博世大数据一面 英文自我介绍 mr的shuffle zookeeper选举 spark内存管理 hbase中region的拆分 数仓中都有什么表 怎么处理缓慢变化维,拉链表有用过吗 yarn的架构 namenode ha的实现 namenode启动过程中怎么确定哪个是active哪个是standby spark sql用的多吗 手撕 中等leetcoode,合并区间 二面 自我介绍 家哪里的 对博世有什么了
-
 ZDNS大数据岗
ZDNS大数据岗一面:55min 0、自我介绍 1、介绍一下项目,一个离线,一个实时。离线Hive on Spark 实时:Flink + Kafka 2、Spark作业流程、Client,Cluster模式 3、Flink水位线,窗口,FlinkSQL,时间语义和SparkStreaming区别 4、Hive事实表、应用场景 5、实时项目怎么做的,FlinkSQL怎么用的 6、查找算法,排序算法有啥,说说冒泡,
-
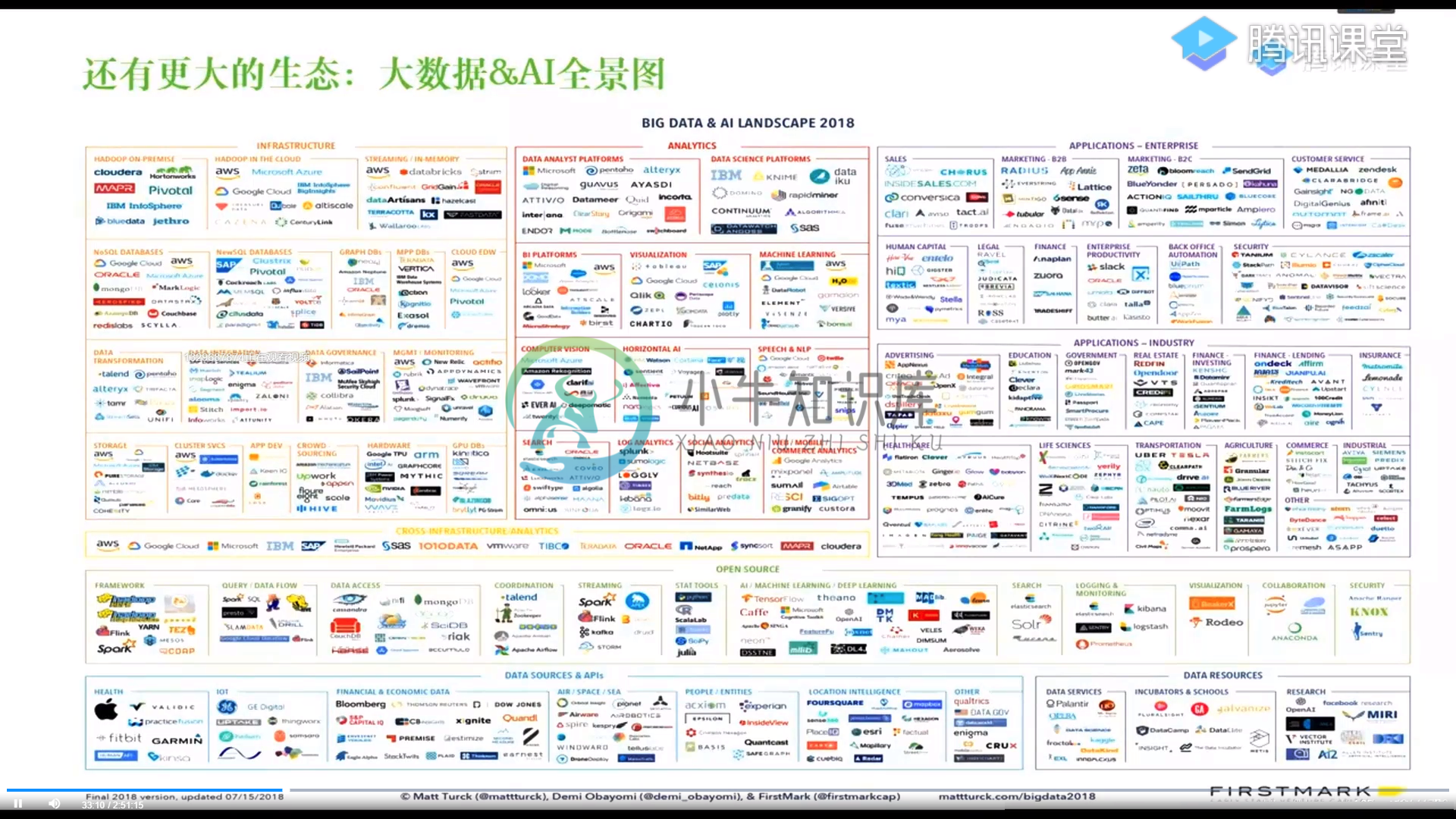 大数据生态
大数据生态fink生态 spark生态 hadoop生态 大数据技术体系与主流技术栈
-
大数据认证
2018年的20个主要的大数据认证 “大数据”一词反映了一个非常实际的增长趋势。到2020年,每个人每秒将产生1.7MB数据。根据调研机构IDC公司的调查,2020年全球数据量将增加到44万亿GB。数以亿计的智能手机和数十亿台物联网(IoT)设备每分钟产生的近300万个Facebook帖子和近300万个视频,每秒约有40,000次谷歌搜索查询。 而大数据认证的数量也在不断增加,尽管不尽相同。这些资
-
 腾讯 - 大数据
腾讯 - 大数据投的 Teg 云架构平台,结果被大数据捞了,一面就挂了。 一面 3.28 自我介绍 介绍冷存储项目 介绍阿里tianchi比赛 线程和进程区别,协程和线程区别? 页表实现 如果访问进程地址空间,在page table 中找不到,会发生什么? 做题 输入一串0和1组成的字符串。重新排列这个字符串使得任何一个字符都不是它前面两个字符的和。比如011就不满足,因为0+1=1。 010,110,111都是
-
 大华二面 大数据开发c++
大华二面 大数据开发c++1.hashmap底层数据结构 2.virtual的使用场景,虚函数表 3.设计模式 4.多线程同步的方法 5.三次握手 6.智能指针有哪些,如何设计一个share_ptr? 7. vector是如何实现的,和list相比有何优缺点? 8.想问我网络编程方面的,我说不熟悉,跳过了…… 9.c++ 源文件到可执行文件的过程 9.多线程适用于那些应用场景? 10.stl哪些容器是线程安全的 11.补充
-
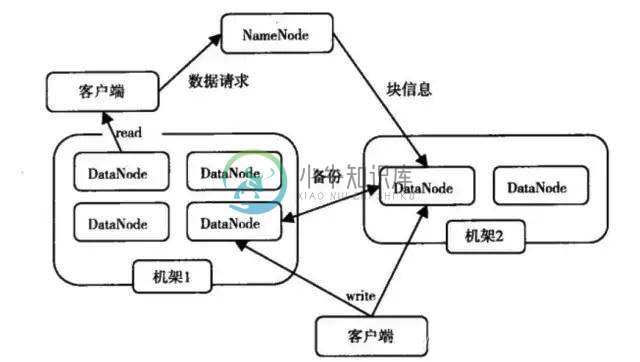 大数据技术十大核心原理
大数据技术十大核心原理主要内容:1.数据核心原理:从“流程”核心转变为“数据”核心,2.数据价值原理:有功能是价值转变为数据是价值,3.全样本原理:从抽样转变为需要全部数据样本,4.关注效率原理:由关注精确度转变为关注效率,5.关注相关性原理:由因果关系转变为关注相关性,6.预测原理:从不能预测转变为可以预测,7.信息找人原理:从人找信息,转变为信息找人,8.机器懂人原理:由人懂机器转变为机器更懂人,9.电子商务智能原理:大数据改变了电子商务模式,让电子商务更智能,科学进步越来越多地由数据来推动,海量数据给数据分析既
-
 科大讯飞一面凉经 | 大数据
科大讯飞一面凉经 | 大数据一面 共 30min 自我介绍 实习经历介绍 项目介绍:数仓分层的理解 为什么用spark而不用hadoop 为什么spark比hadoop快 spark开始计算的标志 java抽象类和接口的区别 对继承和多态的理解 最近有想要学习的新技术吗 #科大讯飞##秋招##大数据#
-
为什么H2数据库文件的大小要比数据大小大得多?
我有大约500MB的H2数据库。 H2的版本是1.2.147。 数据库的存储引擎是PageStore。 JDBC URL如下所示。 jdbc:h2:file://C:/h2/client;如果存在=真;MVCC=真;数据库\u事件\u侦听器。H2DBMonitor';AUTO_SERVER=TRUE;对数=2 我做了一个版本的H2 1.4.192没有改变数据库的存储引擎。 当我的客户使用数据库时,