《格力结构设计岗》专题
-
向量和结构体
简介 本章中,我将讲解向量和结构体。 向量是一组通过整数索引的数据。与C语言中的数组不同,一个向量可以储存不同类型的数据。与表相比,向量更加紧凑且存取时间更短。但从另外一方面来说,向量是通过副作用来操作的,这样会造成负担。 Scheme中的结构体与C语言中的结构体类似。但Scheme中的结构体比C语言中的更容易使用,因为Scheme为结构体自动创建了读取函数和写入函数,这受益于Lisp/Schem
-
2.android源码结构
可以粗略分为4种: android核心源码,通常来自AOSP、LineageOS、或其他github项目 device,机型相关的配置,比如这个手机屏幕有多大、有几个摄像头、有几个物理按键 kernel,linux内核源码,手机厂商所谓的开源就是开的这个,因为linux源码是GPL开源协议,要求必须开源 vendor,设备特有的非开源文件,比如非开源的各种驱动、系统app,通常来自官方ROM提取
-
树结构工具-TreeUtil
介绍 考虑到菜单等需求的普遍性,有用户提交了一个扩展性极好的树状结构实现。这种树状结构可以根据配置文件灵活的定义节点之间的关系,也能很好的兼容关系数据库中数据。实现 关系型数据库数据 <-> Tree <-> JSON 树状结构中最大的问题就是关系问题,在数据库中,每条数据通过某个字段关联自己的父节点,每个业务中这个字段的名字都不同,如何解决这个问题呢? PR的提供者提供了一种解决思路:
-
废弃的 FTL 结构
Section Contents 废弃的指令列表 废弃的内建函数列表 老式的 macro 和 call 指令 转换指令 老式 FTL 语法 #{...}: 数字插值
-
Ocaml 程序的结构
现在我们将从整体上观察一些OCaml程序。我将传授以下内容:局部和全局定义,何时使用;;而何时用;,模块,嵌套函数,以及引用。为此我们会见到很多现在还不理解意义的目前还未接触过的OCaml概念。不用担心这些细节,只要专注于程序的整体形状以及我指出的那些特性。 局部"变量"(实际是局部表达式) 我们来看C中的average函数并且加一个局部变量。 double average (double a,
-
第十二章:结构
3.3 节中介绍了 Lisp 如何使用指针允许我们将任何值放到任何地方。这种说法是完全有可能的,但这并不一定都是好事。 例如,一个对象可以是它自已的一个元素。这是好事还是坏事,取决于程序员是不是有意这样设计的。 12.1 共享结构 (Shared Structure) 多个列表可以共享 cons 。在最简单的情况下,一个列表可以是另一个列表的一部分。 > (setf part (list 'b '
-
目录结构说明
原生目录 target:这个目录里定义了各平台及板级固件和 kernel 的编译配置 package:包含各个供固件使用的软件包的定义 tools:包含编译过程中主机所需的工具软件包 toolchain:定义获取和编译 kernel headers, C library, bin-utils, compiler, debugger 等组件 include:openwrt 基础编译脚本 script
-
工程目录结构
vsp_simulate 的目录结构如上图所示。 目录简介 tb/algorithm/: 用来放置对应的算法库,工程默认提供了 fft 和 logfbank 定点的实现,算法工程师即将调试和优化的算法(比如:aec、vad、doa等)放在这里。 tb/arch/xtensa/lsp-sim/: 是用来生成 lsp 的,其功能类似于 ld 链接脚本,算法开发者可以不用关心它。 tb/audio_da
-
源码目录结构
Electron 的源代码主要依据 Chromium 的拆分约定被拆成了许多部分。 为了更好地理解源代码,您可能需要了解一下 Chromium 的多进程架构。 源代码的目录结构 Electron ├── build/ - Build configuration files needed to build with GN. ├── buildflags/ - Determines the set o
-
 JVM的整体结构
JVM的整体结构字节码->类装载子系统->JVM->引擎/接口欧 类装载子系统:将字节码文件加载至大的Class文件.分为:加载,连接,初始化3部分 执行引擎: java代码执行流程 jvm的架构模型 hotspot虚拟机是基于栈的虚拟机
-
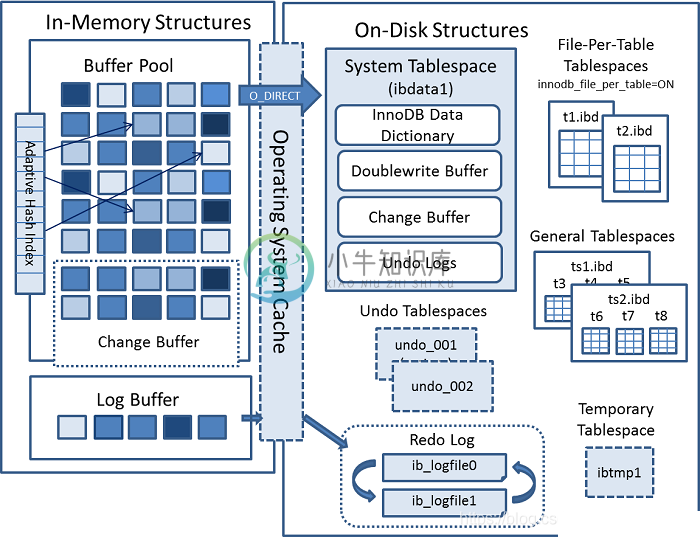 InnoDB的磁盘结构
InnoDB的磁盘结构主要内容:一、磁盘结构的内容,二、表空间,三、数据字典,四、双写缓冲区,五、日志,六、总结一、磁盘结构的内容 InnoDB磁盘结构主要包含表空间,数据字典,双写缓冲区、日志(重做日志和撤销日志)。说起内存结构和磁盘结构,很多人可能有点晕,确实,刚刚接触的或者没有搞清楚是什么问题的,一定会有些晕。其实这个如果搞过内存数据写物理文件的,就容易理解了。在内存中,会有一套数据结构,然后会把这些数据最终整理成一套易于和硬盘交互的结构,这样,就更容易程序的编写和维护。 如果单纯是为了实现功能,写代
-
内核数据结构
这不是 linux-insides-zh 中的一般章节。正如你从题目中理解到的,它主要描述 Linux 内核中的内部系统数据结构。比如说,中断描述符表 (Interrupt Descriptor Table), 全局描述符表 (Global Descriptor Table) 。 大部分信息来自于 Intel 和 AMD 官方手册。
-
工程目录结构
vsp_simulate 的目录结构如上图所示。 目录简介 tb/algorithm/: 用来放置对应的算法库,工程默认提供了 fft 和 logfbank 定点的实现,算法工程师即将调试和优化的算法(比如:aec、vad、doa等)放在这里。 tb/arch/xtensa/lsp-sim/: 是用来生成 lsp 的,其功能类似于 ld 链接脚本,算法开发者可以不用关心它。 tb/audio_da
-
 JavaScript设计模式之构造函数模式实例教程
JavaScript设计模式之构造函数模式实例教程本文向大家介绍JavaScript设计模式之构造函数模式实例教程,包括了JavaScript设计模式之构造函数模式实例教程的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JavaScript设计模式之构造函数模式。分享给大家供大家参考,具体如下: 一、构造函数模式概念 构造函数用于创建特定类型的对象——不仅声明了使用过的对象,构造函数还可以接受参数以便第一次创建对象的时候设置对象的成员值。
-
如何设计数据库架构以支持类别标记?
问题内容: 我正在尝试像“数据库设计标签”之类的东西,除了我的每个标签都分为几类。 例如,假设我有一个有关车辆的数据库。假设我们实际上对车辆不是很了解,因此我们无法指定所有车辆将具有的列。因此,我们将用信息“标记”车辆。 现在,您可以看到所有汽车都标有其制造商和型号,但其他类别并不完全匹配。请注意,汽车只能具有每个类别中的一个。IE。一辆汽车只能有一个制造商。 我想设计一个数据库来支持对所有梅赛德