《分布式锁》专题
-
其他 - 分布式manager节点
为了保证manager节点的容错性,我们最好将manager节点个数设定为奇数个。在网络被划分成2个部分情况下,奇数个manager节点能够较高程度的保证有投票结果的可能性。如果网络被划分成2个部分以上,投票有结果的可能性将不能被保证。 Swarm节点数 法定票数 允许manager不可用个数 1 1 0 2 2 0 3 2 1 4 3 1 5 3 2 6 4 2 7 4 3 8 5 3 9 5
-
分布式缓存 - IDistributedCache 接口
[命名空间: Serenity.Abstractions, 程序集: Serenity.Core] 所有 NoSQL 服务器类型提供了一个类似的接口,像”使用该键存储此值”、”给我该键对应的值”等。 Serenity 通过一个没有依赖特定 NoSQL 数据库类型的通用接口提供分布式缓存的支持: public interface IDistributedCache { long Increm
-
 分布式集群Hadoop和Hbase
分布式集群Hadoop和Hbase我有两个节点的完全分布式Hadoop和Hbase实例。HDFS在主机和从机上工作良好。但是HBase shell只在节点名格式化之后工作一次,并且集群是新的,之后我得到错误:error:org.apache.hadoop.HBase.PleaseHoldException:Master is initializing HBase 我也不能通过hbase shell从slave连接我总是得到错误连接
-
如何配置分布式Ehcache
我想在不同的 VM 上配置 Ehcache 实例,并在主机上运行 servlet,将这些缓存用作数据存储。缓存服务器必须形成一个集群,用于分布式缓存。 我搜索了任何地方(谷歌、stackoverflow、Ehachep留档)。但是,我找不到任何足够的“如何”文章。此外,我不可能使用企业产品(Terracotta BigMemory等)。 可以随意假设元素包含如上所述的客户信息。我只需要知道如何通过
-
2PC与Sagas(分布式事务)
我正在发展我对分布式系统的见解,以及如何在这样的系统中保持数据一致性,其中业务事务涵盖多种服务、有限的上下文和网络边界。 我知道有两种方法用于实现分布式事务: 2阶段提交(2PC) 萨加斯 2PC 是一种协议,供应用程序通过平台支持透明地利用全局 ACID 事务。据我所知,它嵌入在平台中,对业务逻辑和应用程序代码是透明的。 另一方面,Sagas是一系列本地事务,其中每个本地事务都会发生变化,并保存
-
1.14 分布式框架对比
Dubbo 是阿里巴巴公司开源的一个Java高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。不过,略有遗憾的是,据说在淘宝内部,dubbo由于跟淘宝另一个类似的框架HSF(非开源)有竞争关系,导致dubbo团队已经解散(参见http://www.oschina.net/news/55059/druid-1-0-9 中的评论),反到是
-
16. 分布式爬虫原理
在前面我们已经掌握了Scrapy框架爬虫,虽然爬虫是异步多线程的,但是我们只能在一台主机上运行,爬取效率还是有限。 分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,将大大提高爬取的效率。 16.1 分布式爬虫架构 回顾Scrapy的架构: Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。 如果有新的Request产生,就会放到队列里面,随后Reque
-
 ZooKeeper 分布式进程协同
ZooKeeper 分布式进程协同ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现,是 Hadoop 和 Hbase 的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
-
第6章 分布式编程
本章描述如何编写运行于Erlang节点网络上的分布式Erlang程序。我们描述了用于实现分布式系统的语言原语。Erlang进程可以自然地映射到分布式系统之中;同时,之前章节所介绍的Erlang并发原语和错误检测原语在分布式系统和单节点系统中仍保持原有属性。 动机 我们有很多理由去编写分布式应用,比如: 速度 我们可以把我们的程序切分成能够分别运行于多个不同节点的几个部分。比如,某个编译器可以将一个
-
分布式MinIO快速入门
分布式Minio可以让你将多块硬盘(甚至在不同的机器上)组成一个对象存储服务。由于硬盘分布在不同的节点上,分布式Minio避免了单点故障。 分布式Minio有什么好处? 在大数据领域,通常的设计理念都是无中心和分布式。Minio分布式模式可以帮助你搭建一个高可用的对象存储服务,你可以使用这些存储设备,而不用考虑其真实物理位置。 数据保护 分布式Minio采用 纠删码来防范多个节点宕机和位衰减bit
-
分布式的工作流程
假设Alice现在开始了一个新项目,在/home/alice/project建了一个新的git 仓库(repository);另外Bob的工作目录也在同一台机器,他要提交代码。 Bob 执行了这样的命令: $ git clone /home/alice/project myrepo 这就建了一个新的叫"myrepo"的目录,这个目录里包含了一份Alice的仓库的 克隆(clone). 这份克隆和
-
5.3-分布式计算框架
类型 实现框架 应用场景 批处理 MapReduce 微批处理 Spark Streaming 实时流计算 Storm
-
5.2-分布式文件系统
数据存储容量的问题。 数据读写速度的问题。 数据可靠性的问题。 几种常见 RAID 的对比|名称|优点|缺点| |------|------|------| |RAID 0|使用 N 块磁盘的 RAID 0,将数据从内存写入磁盘时,将数据分成 N 块,并发写入,读取同理。所以,读写速度是单盘的 N 倍。|任何一块盘损坏,数据完整性破坏,数据不可用。| |RAID 1|数据写入磁盘时,将一份数据同时
-
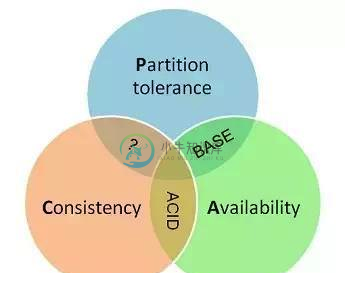 分布式理论:BASE理论
分布式理论:BASE理论主要内容:前言,正文,小结前言 BASE理论是由eBay架构师提出的。BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网分布式系统实践的总结,是基于CAP定律逐步演化而来。其核心思想是即使无法做到强一致性,但每个应用都可以根据自身业务特点,才用适当的方式来使系统打到最终一致性。 正文 1. CAP的3选2伪命题 实际上,不是为了P(分区容错性),必须在C(一致性)和A(可用性)之间任选其一。分区的情况很少
-
Tiny分布式计算框架
其于职业介绍所、工头、工人、工作模型的分布式计算框架。 职业介绍所有两种,一种是本地职业介绍所,一种是远程职业介绍所。顾名思义,本地职业介绍所就是在当前计算机上的,远程职业介绍所用于连接到远程职业介绍所的。 工人、工头都可以加入到职业介绍所,所以加到本地或远程种业介绍所都是可以的。 在同一个职业介绍所中,具有同样类型的工人、工头和工作都存在的时候,工作就可以被安排下去执行。当然,有两种安排方式,一