《分布式锁》专题
-
5.3 分布式 Git - 维护项目
除了如何有效地参与一个项目的贡献之外,你可能也需要了解如何维护项目。 这包含接受并应用别人使用 format-patch 生成并通过电子邮件发送过来的补丁,或对项目添加的远程版本库分支中的更改进行整合。 但无论是管理版本库,还是帮忙验证、审核收到的补丁,都需要同其他贡献者约定某种长期可持续的工作方式。 在特性分支中工作 如果你想向项目中整合一些新东西,最好将这些尝试局限在特性分支——一种通常用来尝
-
其他 - 如何实现分布式
关于最近很多人在询问,如何利用EasySwoole做分布式负载均衡,复杂的就不讲解了,就讲解如何实现最简单的负载均衡。 相关知识 DNS轮训 一个域名针对多个ip A记录的解析,DNS服务器将解析请求按照A记录的顺序,逐一分配到不同的IP上,这样就完成了简单的负载均衡。 DNS轮询的优点: 低成本:只是在DNS服务器上绑定几个A记录,域名注册商一般都免费提供解析服务。 部署简单:就是在网络拓扑进行
-
java如何生成分布式ID?
如何自定义生成固定长度的字符串ID,8-12个字符 格式:业务标记_xxxxxxxxxx 如:user_Nuxq23s24dxa1ScSx 要求:1ms生成100W个 或有什么现成的库可以使用,麻烦老大们贴下代码
-
 美团 - 分布式查询引擎
美团 - 分布式查询引擎一面 3.27 第一回遇到提前五分钟进来的面试官。。。 面试官介绍部门 问我知不知道 kkv? 列存储怎么做?列存和行存的区别,使用场景? 介绍了实习的工作 leveldb 读哪一层sst最耗时,为什么? 如果前台不停的读,后台在做compaction ,会发生什么? CMU 15445 问了分片buffer pool 的实现? 怎么实现 buffer pool 的无锁化? 如果现在 mmap 的
-
NameNode未在伪分布式模式下启动
我无法在hadoop fs-ls/命令上查看HDFS中的文件,我想这是因为name节点没有运行。我尝试了格式化namenode,并将core-site.xml中的端口更改为不同的值,但我的JPS没有列出namenode。 下面是这些文件:1)core-site.xml 3)mapred-site.xml JPS输出为: 21043作业跟踪器 20839数据阳极
-
分布式数据库模式的application.properties配置
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
分布分析
1. 简介 分布分析报告可以帮助您查看事件在不同区间的发生频次,从而判断用户的使用习惯和活跃情况。除了次数,您还能够查看其它事件指标的用户数量分布。 分布分析能够帮助您洞察这些问题: · 对比不同来源渠道的用户在站点的行为次数分布,如浏览页面1-3次,3-10次,10次以上,不同区间的用户数量有多少 · 上周推广活动客单价的人数分布情况 · 改版后,用户的每日启动次数是否增加 2. 使用说明 2.
-
第八章 HBASE - 1.HBASE的伪分布安装与分布式安装
一 伪分布式安装 1.下载解压给权限 可以从官方下载地址下载 HBase 最新版本,推荐 stable目录下的二进制版本。我下载的是 hbase-1.1.3-bin.tar.gz 。确保你下载的版本与你现存的 Hadoop 版本兼容(兼容列表)以及支持的JDK版本(从HBase 1.0.x 已经不支持 JDK 6 了)。 兼容列表: tar -zxvf hbase-1.1.3-bin.tar.gz
-
适用于Python的分布式锁管理器
问题内容: 我有一堆服务器,其中有多个实例,这些实例正在访问对每秒请求有严格限制的资源。 我需要一种机制来锁定正在运行的所有服务器和实例对此资源的访问。 我在github上找到了一个宁静的分布式锁管理器:https : //github.com/thefab/restful-distributed-lock- manager 不幸的是似乎有一个分钟。锁定时间为1秒,并且相对不可靠。在几次测试中,解
-
 Java使用Redisson分布式锁实现原理
Java使用Redisson分布式锁实现原理本文向大家介绍Java使用Redisson分布式锁实现原理,包括了Java使用Redisson分布式锁实现原理的使用技巧和注意事项,需要的朋友参考一下 1. 基本用法 针对上面这段代码,重点看一下Redisson是如何基于Redis实现分布式锁的 Redisson中提供的加锁的方法有很多,但大致类似,此处只看lock()方法 更多请参见https://github.com/redisson/red
-
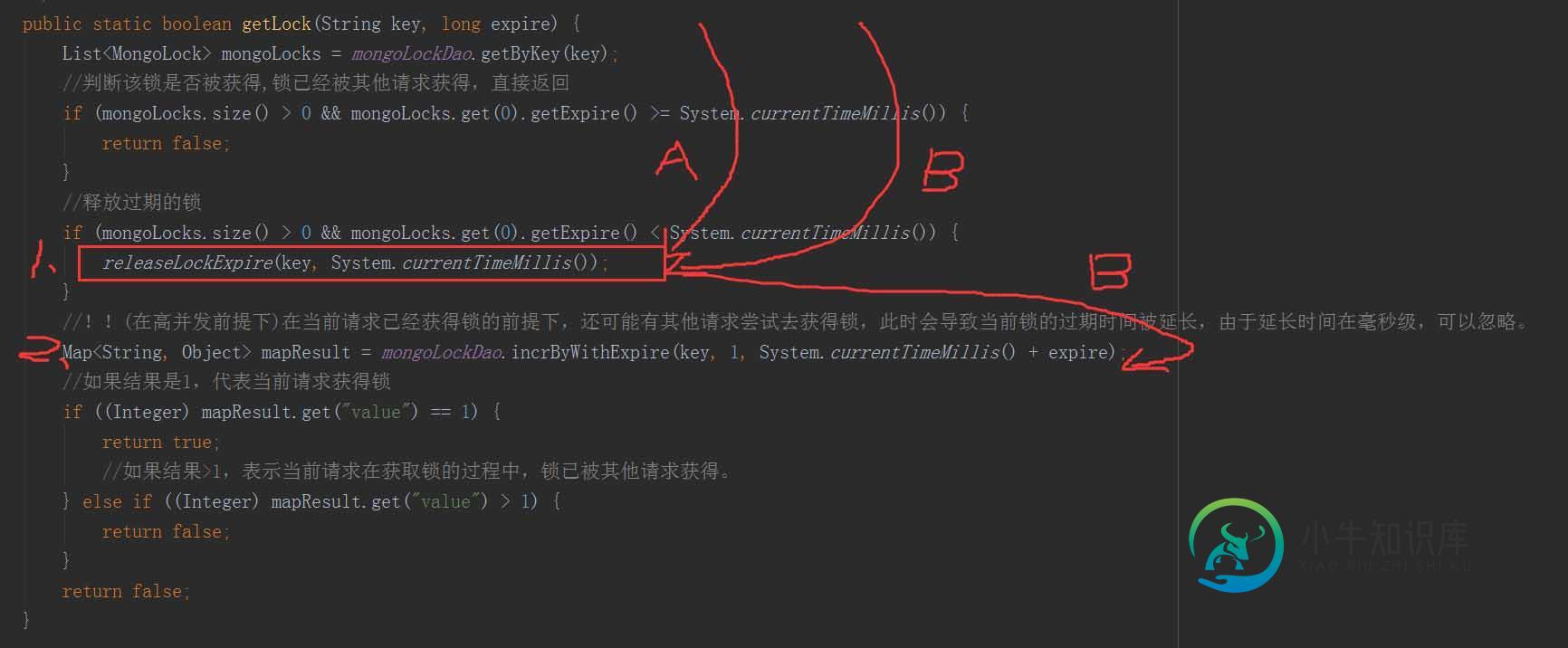 mongo分布式锁Java实现方法(推荐)
mongo分布式锁Java实现方法(推荐)本文向大家介绍mongo分布式锁Java实现方法(推荐),包括了mongo分布式锁Java实现方法(推荐)的使用技巧和注意事项,需要的朋友参考一下 一、分布式锁使用场景: 代码部署在多台服务器上,即分布式部署。 多个进程同步访问一个共享资源。 二、需要的技术: 数据库:mongo java:mongo操作插件类 MongoTemplate(maven引用),如下: 三、实现代码: 主实现逻辑及外部
-
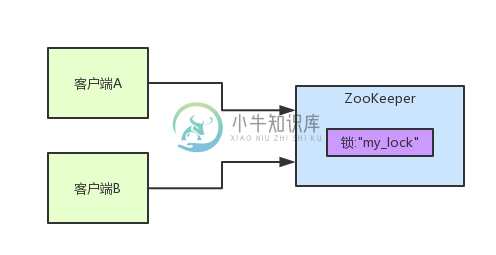 一文带你了解ZooKeeper的分布式锁
一文带你了解ZooKeeper的分布式锁主要内容:一、写在前面,二、ZooKeeper分布式锁机制,三、总结一、写在前面 之前写过一篇文章:《都2022年了,出去面试连分布式锁的源码你都不会画?》,给大家说了一下Redisson这个开源框架是如何实现Redis分布式锁原理的,这篇文章再给大家聊一下ZooKeeper实现分布式锁的原理。 同理,我是直接基于比较常用的Curator这个开源框架,聊一下这个框架对ZooKeeper(以下简称zk)分布式锁的实现。 一般除了大公司是自行封装分布式锁框架之外,建议
-
Kafka connect-分布式模式容错不起作用
我用3台EC2机器创建了kafka connect集群,并在每台机器上启动了3个连接器(debezium-postgres source ),从postgres source中读取一组不同的表。在其中一台机器上,我还启动了s3 sink连接器。因此,来自postgres的已更改数据正通过源连接器(3)移动到kafka broker,S3接收器连接器使用这些消息并将它们推送到S3桶。< br >群集
-
如何在分布式模式下部署kafka connect?
我正在使用kubernetes中的JDBC接收器连接器构建Kafka-连接应用程序。我尝试了独立模式,它正在工作。我想转移到分布式模式。我可以通过运行下面的yaml文件成功构建两个pod(kafka连接器): bin/connect-distributed.sh配置/worker.properties 并在每个 pod 内部创建了一个接收器连接器,任务.max=1,两个连接器侦听相同的主题。原来他
-
HMASTER无法在psedo分布式模式下运行
我已经在Ubuntu上安装了hadoop 1.2.0。所有的服务namenode,sec namenode,datanode,jobtracker,tasktracker运行良好。 然后我安装了hbase-0-94.8,我希望配置也可以。但是HMaster无法在端口9000上启动。它实际上开始,然后下降。 >2014-05-14 09:28:37,015 INFO org.apache.hadoo