《分布式锁》专题
-
带锁定的Redis分布式增量
问题内容: 我有一个生成计数器的要求,该计数器将发送到一些api调用。我的应用程序在多个节点上运行,因此我想如何生成唯一计数器。我尝试了以下代码 并通过Task Parallel libray运行测试。当我有边界值时,我看到的是设置了多次0条目 请让我知道我需要做的更正 更新:我的最终逻辑如下 问题答案: 实际上,您的代码在翻转边界附近并不安全,因为您正在执行“获取”,(等待时间和思考),“设置”
-
Redis分布式锁有什么缺陷?
Redis 分布式锁不能解决超时的问题,分布式锁有一个超时时间,程序的执行如果超出了锁的超时时间就会出现问题。 Redis容易产生的几个问题: 锁未被释放 B锁被A锁释放了 数据库事务超时 锁过期了,业务还没执行完 Redis主从复制的问题
-
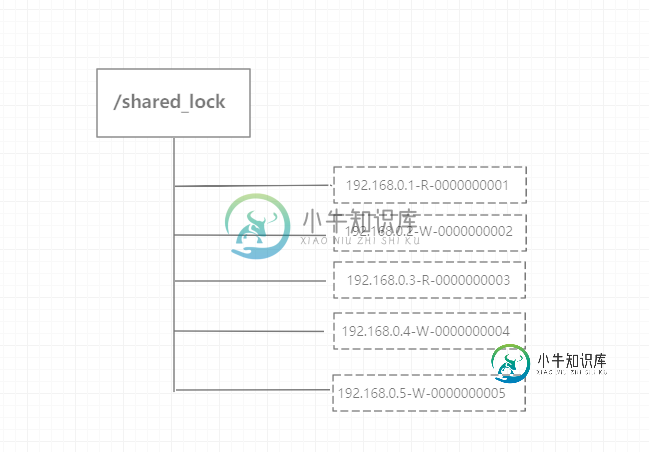 14.0 Zookeeper 分布式锁实现原理
14.0 Zookeeper 分布式锁实现原理主要内容:实例分布式锁是控制分布式系统之间同步访问共享资源的一种方式。 下面介绍 zookeeper 如何实现分布式锁,讲解排他锁和共享锁两类分布式锁。 排他锁 排他锁(Exclusive Locks),又被称为写锁或独占锁,如果事务T1对数据对象O1加上排他锁,那么整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能进行读或写。 定义锁: 实现方式: 利用 zookeeper 的同级节点的
-
Redis 分布式锁有什么缺陷?
本文向大家介绍Redis 分布式锁有什么缺陷?相关面试题,主要包含被问及Redis 分布式锁有什么缺陷?时的应答技巧和注意事项,需要的朋友参考一下 Redis 分布式锁不能解决超时的问题,分布式锁有一个超时时间,程序的执行如果超出了锁的超时时间就会出现问题。
-
 Redis分布式锁,没它真不行!
Redis分布式锁,没它真不行!主要内容:写在前面,Redisson实现Redis分布式锁的底层原理写在前面 现在面试,一般都会聊聊分布式系统这块的东西。通常面试官都会从服务框架(Spring Cloud、Dubbo)聊起,一路聊到分布式事务、分布式锁、ZooKeeper等知识。 所以咱们这篇文章就来聊聊分布式锁这块知识,具体的来看看Redis分布式锁的实现原理。 说实话,如果在公司里落地生产环境用分布式锁的时候,一定是会用开源类库的,比如Redis分布式锁,一般就是用Redisson框架就好了
-
Jmeter分布式负载测试中csv文件的自动分布式读取?
我的场景是在通过jmeter进行分布式负载测试时,我希望csv文件应该以自动分布式的方式读取。如果我在csv数据集配置文件中有100个用户条目,并且从服务器的数量是10。所以在正常情况下,我必须以如下方式排列csv文件条目 所以我想要相同的csv文件有所有100个用户的条目,应该放在所有的从属和jmeter自动读取条目从这些文件和分发它。
-
分布式部署 - Gateway Worker分离部署
什么是Gateway Worker分离部署 GatewayWorker有三种进程,Gateway进程负责网络IO,BusinessWorker进程负责业务处理,Register进程负责协调Gateway与BusinessWorker之间建立TCP长连接通讯。我们可以把Gateway BusinessWorker Register分开部署在不同的服务器上,当业务进程BusinessWorker出现瓶
-
第 Ⅱ 部分:安装 - 分布式安装
Open-Falcon是一个比较大的分布式系统,有十几个组件。按照功能,这十几个组件可以划分为 基础组件、作图链路组件和报警链路组件,其安装部署的架构如下图所示, 在单台机器上快速安装 请直接参考quick_install Docker化的Open-Falcon安装 参考: https://github.com/open-falcon/falcon-plus/blob/master/docker/
-
Hadoop:多用户的伪分布式模式
我很感激你事先的帮助。 我使用root用户凭据在伪分布式模式下设置了Hadoop。我想为多个用户(比如hadoop1、hadoop2等)提供访问权限,以便能够在这个集群上提交和运行MapReduce作业。我们怎么做? 到目前为止我做了什么? 我得到了下面的错误: 为了克服此错误,我授予组“hadoop”对文件夹hdfstmp的rwx权限。此文件夹上的权限类似于drwxrwxr-x。 使用hadoo
-
hadoop作为分布式模式时出错
我尝试使用hadoop作为分布式模式,并且我进行了设置,但是发生了一个错误。我将在下面描述安装过程: 0/etc/hosts 已安装的软件包 获取hadoop 0/etc/hadoop/core-site.xml 0/etc/hadoop/hdfs-site.xml 0/etc/hadoop/mapred-site.xml 主服务器是 节点服务器是 然后我尝试使用这个命令 结果如下: 0node1
-
Kafka-MongoDB Debezium连接器:分布式模式
我正在开发debezium mongodb源连接器。我可以通过提供kafka引导服务器地址作为远程机器(部署在Kubernetes中)和远程MongoDB URL在分布式模式下在本地机器中运行连接器吗? 我尝试了这一点,我看到连接器成功启动,没有错误,只有几个警告,但没有数据从MongoDB流动。 使用以下命令运行连接器 遵循以下教程:https://medium.com/tech-that-wo
-
如何使用Redis创建分布式锁?
问题内容: 在redis文档中,我发现可以通过SETNX实现基本锁: http://redis.io/commands/setnx C4发送SETNX lock.foo以获取锁 崩溃的客户端C3仍然保留它,因此Redis将以0答复C4。 C4发送GET lock.foo以检查锁是否过期。如果不是,它将hibernate一段时间并从头开始重试。 相反,如果由于lock.foo上的Unix时间早于当前
-
Redis分布式锁解决什么问题?
问题内容: 因此,我刚刚阅读了有关redlock的文章。据我了解,它需要3台独立的机器才能工作。独立表示它们是指所有计算机都是主计算机,并且它们之间没有复制,这意味着它们正在提供不同类型的数据。那么,为什么我需要锁定在充当主服务器的三个独立Redis实例中存在的密钥?我需要使用redlock的用例是什么? 问题答案: 那么,为什么我需要锁定在三个独立的Redis实例中充当主键的密钥? 这并不是说您
-
 详解MySQL/Redis/ZooKeeper实现分布式锁
详解MySQL/Redis/ZooKeeper实现分布式锁一个挺着啤酒肚,身穿格子衫,发际线严重后移的中年男子,手拿着保温杯,胳膊夹着MacBook向你走来,看样子是架构师级别。 面试开始, 直入正题。 面试官: 你有没有参与过秒杀系统的设计? 我: 没有,我平时都是开发后台管理系统、OA办公系统、内部管理系统,从来没有开发过秒杀系统。 面试官: 嗯...,小伙子很实诚。今天就先到这里吧,后面有消息会主动联系你。 后面还可能有消息吗?你们啥时候主动联系过
-
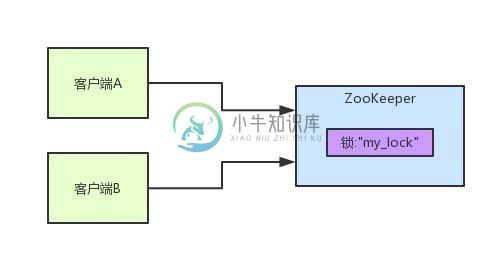 图文并茂:Zookeeper分布式锁原理
图文并茂:Zookeeper分布式锁原理主要内容:写在前面,ZooKeeper分布式锁机制写在前面 之前写过一篇文章(《Redis 分布式锁,没它真不行!》),给大家说了一下Redisson这个开源框架是如何实现Redis分布式锁原理的,这篇文章再给大家聊一下ZooKeeper实现分布式锁的原理。 同理,我是直接基于比较常用的Curator这个开源框架,聊一下这个框架对ZooKeeper(以下简称zk)分布式锁的实现。 一般除了大公司是自行封装分布式锁框架之外,建议大家用这些开源框架封