《分布式锁》专题
-
 JavaScript设计模式之观察者模式与发布订阅模式详解
JavaScript设计模式之观察者模式与发布订阅模式详解本文向大家介绍JavaScript设计模式之观察者模式与发布订阅模式详解,包括了JavaScript设计模式之观察者模式与发布订阅模式详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JavaScript设计模式之观察者模式与发布订阅模式。分享给大家供大家参考,具体如下: 学习了一段时间设计模式,当学到观察者模式和发布订阅模式的时候遇到了很大的问题,这两个模式有点类似,有点傻傻分不清楚,
-
正则表达式模式接受逗号或分号分隔的值
问题内容: 我需要一个正则表达式模式,该模式只接受输入字段的逗号分隔值。 例如:。它应该拒绝像这样的值: 我还需要接受分号分隔的值。有人可以为此建议一个正则表达式模式吗? 问题答案: 最简单的形式: 演示在这里。 我只需要限制字母。我怎样才能做到这一点 ? 使用正则表达式(包括示例Unicode字符范围): 演示在这里。 用法示例: Java演示。
-
微服务架构中的分布式事务,如何处理超时和失败提交
假设您有一个服务,它是大型微服务体系结构的一部分,在这个体系结构中,这些服务通过REST API或涉及某个代理的消息传递(RabbitMQ)相互通信。服务公开RESTendpoint,该endpoint需要与某个第三方服务进行通信(与不在我们体系结构中的服务进行通信)并在那里创建一些内容,当服务收到第三方的响应,表示那里一切正常时,它应该将该响应中的一些数据保存在自己的数据库中。 考虑到第三方不提
-
用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试
本文向大家介绍用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试,包括了用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试的使用技巧和注意事项,需要的朋友参考一下 MapReduce与HDFS简介 什么是Hadoop? Google为自己的业务需要提出了编程模型MapReduce和分布式
-
使用带有分布式源代码管理的飞行路线(即Git,汞合金等)
我是一个具有多个模块(30个左右的jar)的大型java项目的一部分,并且对使用flyway来管理数据库迁移感兴趣。 作为公司政策的一部分,与每个项目相关的迁移脚本存在于每个模块中,并且在迁移时被聚合以形成一个从发布到发布的大型sql脚本—— 由于 Git 的分布式特性,考虑用于命名飞行路线迁移脚本的顺序版本号是违反直觉的。让我进一步说点题外话... < li >用户将主< code>A分支到其特
-
面向用户的分布式数据库设计体系结构用例&身份验证
如果每个大学都采用独立的数据库,是否可以支持分布式数据库体系结构模式和面向微服务的标准?还是需要为所有用户保留一个DB? 我如何才能找出哪种方法适合于微服务/分布式数据库设计模式?
-
如何启用分布式/集群缓存时使用redis与Spring数据高速缓存
如何启用分布式/集群缓存时使用Redis与缓存。 尤其是通过
-
无法将参数传递给具有 Maven 和 Linux 的分布式 JMeter 设置的从站
在所有服务器上使用JMeter 2.13,Maven和Linux。不从gui或命令行运行任何测试,使用Maven! 有一个包含许多参数的测试计划,这些参数是在Jenkins从Maven执行传递到JMeter测试计划的。在Maven中使用“-J”来设置输入参数。在单个JMeter环境中工作正常。 如果我先手动启动从属服务器中的JMeter,然后启动 Jenkins 作业,则指定远程服务器中的测试计划
-
Ant-Jmeter分布式负载测试:主服务器不向从服务器发送参数
当我使用ant任务运行时(ant-Dtest=test-DThreads_CE=10-DRampUp_CE=10-DLoop_CE=1): 只有1个线程启动,我收到包含的请求的错误: > "非HTTP响应代码:java.net.SocketException-非HTTP响应消息:网络不可达:连接" 在调试时,我观察到我的build.xml没有参数到达从机。所以每个参数默认为“1” 但是,当相同的脚
-
分布式 - 如何 掌握 Hystrix的原理、实现和理解核心组件的源码?
没用过Hystrix,想知道怎么使用,以及如何掌握? 在分布式开发中Hystrix被经常听到,想知道怎么上手?
-
随机百分比分支的编码模式?
问题内容: 假设我们有一个代码块,我们要执行70%的时间,又要执行30%的时间。 很简单。但是,如果我们希望它可以轻松扩展为30%/ 60%/ 10%等呢?在这里,这将需要添加和更改所有if语句,这些if语句使用起来并不十分好,而且很慢并且容易引发错误。 到目前为止,我发现大型开关对于此用例非常有用,例如: 可以很容易地将其更改为: 但是这些也有它们的缺点,它们麻烦并且被划分为预定数量的划分。 我
-
php链式操作的实现方式分析
本文向大家介绍php链式操作的实现方式分析,包括了php链式操作的实现方式分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了php链式操作的实现方式。分享给大家供大家参考,具体如下: 类似$db->where("id=1")->limit("5")->order("id desc"),链式操作的实现方式 先讲下方法的常规调用; 调用 缺点:实现多个方法需要多行调用; 链式操作,在方法返回
-
 python如何生成各种随机分布图
python如何生成各种随机分布图本文向大家介绍python如何生成各种随机分布图,包括了python如何生成各种随机分布图的使用技巧和注意事项,需要的朋友参考一下 在学习生活中,我们经常性的发现有很多事物背后都有某种规律,而且,这种规律可能符合某种随机分布,比如:正态分布、对数正态分布、beta分布等等。 所以,了解某种分布对一些事物有更加深入的理解并能清楚的阐释事物的规律性。现在,用python产生一组随机数据,来演示这些分布
-
推荐的Python发布/订阅/分发模块?
问题内容: Pypubsub为您的Python应用程序提供了一种解耦其组件的简单方法:应用程序的某些部分可以发布消息(带有或不带有数据),其他部分可以订阅/接收它们。这允许消息“发件人”和消息“侦听器”彼此不知道: 一个不需要导入另一个 发件人不需要知道 “谁”得到消息, 监听者将如何处理数据, 甚至任何侦听器都将获取消息数据。 同样,听众也不必担心消息的来源。 这是用于实现模型-视图-控制器体系
-
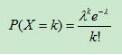 Python数据可视化:泊松分布详解
Python数据可视化:泊松分布详解本文向大家介绍Python数据可视化:泊松分布详解,包括了Python数据可视化:泊松分布详解的使用技巧和注意事项,需要的朋友参考一下 一个服从泊松分布的随机变量X,表示在具有比率参数(rate parameter)λ的一段固定时间间隔内,事件发生的次数。参数λ告诉你该事件发生的比率。随机变量X的平均值和方差都是λ。 代码实现: 以上这篇Python数据可视化:泊松分布详解就是小编分享给大家的全部