《分布式》专题
-
 利用Spring Cloud Config结合Bus实现分布式配置中心的步骤
利用Spring Cloud Config结合Bus实现分布式配置中心的步骤本文向大家介绍利用Spring Cloud Config结合Bus实现分布式配置中心的步骤,包括了利用Spring Cloud Config结合Bus实现分布式配置中心的步骤的使用技巧和注意事项,需要的朋友参考一下 概述 假设现在有个需求: 我们的应用部署在10台机器上,当我们调整完某个配置参数时,无需重启机器,10台机器自动能获取到最新的配置。 如何来实现呢?有很多种,比如: 1、将配置放置到一
-
具有多个组共享相同配置的分布式 Kafka 源连接器
我有两个Kafka连接器节点,分别是Node-A和Node-B。 我在每个节点中运行一个分布式工作器(指向同一个Kafka集群)。 组id和客户机id在两个分布式工作线程中是唯一的。 连接器任务是在两个节点上使用 http POST 请求成功创建的。连接器任务为同一主题生成消息。 注意:我知道分配的工人应该有相同的组id来分配任务。但我是针对一个具体的案例,作为一个实验来做上面所说的。 我使用来自
-
PHP一致性hash分布式算法封装类定义与用法示例
本文向大家介绍PHP一致性hash分布式算法封装类定义与用法示例,包括了PHP一致性hash分布式算法封装类定义与用法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP一致性hash分布式算法封装类定义与用法。分享给大家供大家参考,具体如下: 一、无虚拟节点实现 二、运行结果: save key1 in server: 192.168.1.4 save key2 in server
-
面向微服务体系结构的分布式数据库设计风格
另一种方式,我认为是水平分割当前结构。所以我的领域是基于一些教育大学。因此,一半的大学低于一分贝,剩下的将低于另一分贝。并根据两个地区部署服务(两个针对两套大学)。 目前,我决定继续采用最后提到的方法。我对这些类型的任务是新的,因为它涉及一些体系结构任务。我也是微服务和分布式数据库领域的初学者。有人能证实我的方法能解决我的问题吗?我可以继续我的第二种方法--根据域对象对数据库进行水平分区吗?
-
使用PostSharp记录具有公共guid的嵌套分布式函数调用
目前,多层系统的每个组件都使用PostSharp记录所有函数调用。 e、 g.对WCF服务的应用程序调用可能会提示对DataService(进程中)和AuditService(通过NServiceBus)的调用 这将导致向日志表写入四行,但稍后查看日志表时,无法确定调用logCaseAccess()是作为封闭的应用程序调用的一部分调用的。 如果这四行可以被识别为一个组,那将更加有用。 我可以看到应
-
在pyspark中以分布式方式高效生成大型DataFrame(无需pyspark.sql.行)
问题归结为以下几点:我想在pyspark中生成一个数据帧,使用现有的并行化输入集合和一个给定一个输入可以生成相对大批量行的函数。在下面的示例中,我想使用1000个执行器生成10^12行数据帧: (我真的不想研究给定种子的随机数分布——这只是我能够想出的一个例子,来说明大型数据帧不是从仓库加载的,而是由代码生成的情况) 上面的代码几乎完全符合我的要求。问题是,它以一种非常低效的方式来实现这一点——代
-
使用spring-cloud的微服务系统中服务间的分布式事务
得到了一个使用:< code>spring-boot、< code>spring-cloud、< code>postgresql作为微服务系统的项目。 有 2 个服务,比如 SA 和 SB,它们分别在 2 个 RDBMS 数据库上运行,比如 DA 和 DB。 现在,有一个包含2个子步骤的操作: Http客户端会向服务SA发出请求,将记录保存到中。 然后,SA向服务SB发送请求,将记录保存到中。 作
-
分布式(非关系型数据库)数据库中的一致性效应
每当我读到有关NoSQL分布式数据库的内容时,他们都会提到CAP定理,这意味着在分区系统中,您可以具有完全一致性,完全可用性或两者兼而有之,但不能完全两者兼而有之。 我不太清楚他们在谈论什么类型的一致性: 是数据新鲜度的一致性,其中一些客户端可能会获得比其他客户端更旧的数据吗? 或者是一致性,即事务可能仅部分完成,这可能会使数据处于不一致的状态? 第二种解释对我来说听起来很危险,不能真正接受。第一
-
如何在jmeter中生成分布式负载测试的复合html报告?
上下文:我正在主从比为1:2的分布式负载系统上运行JMeter负载测试,使用以下命令: jmeter -n -t “home/jmeterscripts/EventGridScript.jmx” -R slave1:1099,slave2:1099 -l “home/jmeterscripts/结果.csv” -e -o “home/jmeterscripts/HTMLReports” 结果是否会
-
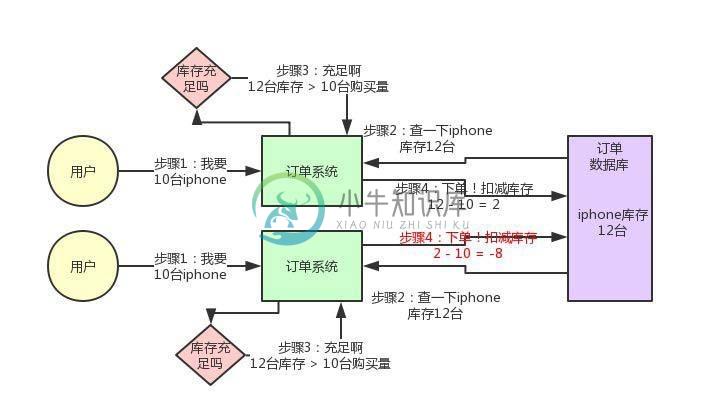 一文带你了解亿级流量下的分布式锁优化方案!
一文带你了解亿级流量下的分布式锁优化方案!主要内容:背景引入,库存超卖现象是怎么产生的?,用分布式锁如何解决库存超卖问题?,如何对分布式锁进行高并发优化?今天给大家聊一个有意思的话题:每秒上千订单场景下,如何对分布式锁的并发能力进行优化? 背景引入 首先,我们一起来看看这个问题的背景? 前段时间有个朋友在外面面试,然后有一天找我聊说:有一个国内不错的电商公司,面试官给他出了一个场景题: 假如下单时,用分布式锁来防止库存超卖,但是是每秒上千订单的高并发场景,如何对分布式锁进行高并发优化来应对这个场景? 他说他当时没答上来,因为没做过没什么
-
响应式布局
响应式布局 多屏的环境让我们不得不考虑网络内容在各个尺寸中的表现, 均可正常访问和极佳的用户体验。 响应式布局可以更具屏幕尺子的大小对内容和布局做出适当的调成, 从而提供更好的用户感受。也是因为响应式布局的出现, 开发者也无需对不同尺寸设备而特殊定制不同的页面, 这大大降低了开发成本和缩短了开发时间。 这样的方法也同样存在着缺点。 缺点是同样的资源被加载,但因为展示平台所限并不能全部显示。 Vie
-
9.1.2 流式布局
在移动终端兴起的时代,可以预见的是,未来还会涌现出更多大小不一的屏幕,人们需要一种灵活的、能够适应未知设备的方法,使得我们的设计在所有屏幕中都能完美显示,这就催生了流式布局。 使用流式布局时,尺寸不再使用像素,而是使用百分百进行设置。这种布局可以自适应用户的分辨率,并根据浏览器窗口尺寸自由伸缩,非常高效的利用空间。当浏览器窗口变大,元素的尺寸会变宽,当浏览器窗口变小,元素的尺寸也会跟着变小。页面周
-
样式和布局
MIP 页面上的样式和布局和普通的 HTML 页面十分类似,都是需要使用 CSS。不同的是,MIP 为了性能和易用性考虑,对 CSS 的使用做了一定的限制,与此同时,针对响应式设计,MIP 做出了一些扩展来更好地展示页面元素,如占位符和备用行为,媒体查询和元素查询,layout 属性等。 在本章节中,我们将学习 MIP 是如何利用上述提到的功能来更好地展示页面。 章节索引 组件布局 介绍组件支持的
-
样式和布局
传统方式的 CSS 如果您使用的是 @docusaurus/preset-classic,则可以创建自己的 CSS 文件(例如 /src/css/custom.css),然后将这些文件添加到预设(preset)配置中,以便将其导入到全局环境中。docusaurus.config.js module.exports = { // ... presets: [ [
-
2.5.1 分布式事务了解吗?你们如何解决分布式事务问题的?TCC 如果出现网络连不通怎么办?XA 的一致性如何保证?
面试题 分布式事务了解吗?你们是如何解决分布式事务问题的? 面试官心理分析 只要聊到你做了分布式系统,必问分布式事务,你对分布式事务一无所知的话,确实会很坑,你起码得知道有哪些方案,一般怎么来做,每个方案的优缺点是什么。 现在面试,分布式系统成了标配,而分布式系统带来的分布式事务也成了标配了。因为你做系统肯定要用事务吧,如果是分布式系统,肯定要用分布式事务吧。先不说你搞过没有,起码你得明白有哪几种