《分布式》专题
-
4.17 使用JTA的分布式事务
Spring Boot通过使用Atomikos或Bitronix嵌入式事务管理器支持跨多个XA资源的分布式JTA事务。 部署到合适的Java EE Application Server时,也支持JTA事务。 检测到JTA环境时,Spring的JtaTransactionManager用于管理事务。 自动配置的JMS,DataSource和JPA bean已升级为支持XA事务。 您可以使用标准的Sp
-
分布式通信包(已弃用)-torch.distributed.deprecated
警告 torch.distributed.deprecated 是 torch.distributed 的早期版本,当前已被弃用,并且很快将被删除。请参照使用 torch.distributed 的文档,这是PyTorch最新的分布式通信包。 torch.distributed提供类似MPI的接口,用于跨多机网络交换张量数据。它提供一些不同的后台并且支持不同的初始化方法。 当前的torch.dis
-
 分布式Id 雪花算法原理
分布式Id 雪花算法原理分布式ID常见生成策略 分布式ID生成策略常见的有如下几种: 数据库自增ID。 UUID生成。 Redis的原子自增方式。 数据库水平拆分,设置初始值和相同的自增步长。 批量申请自增ID。 雪花算法。 百度UidGenerator算法(基于雪花算法实现自定义时间戳)。 美团Leaf算法(依赖于数据库,ZK)。 其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 id。在分布
-
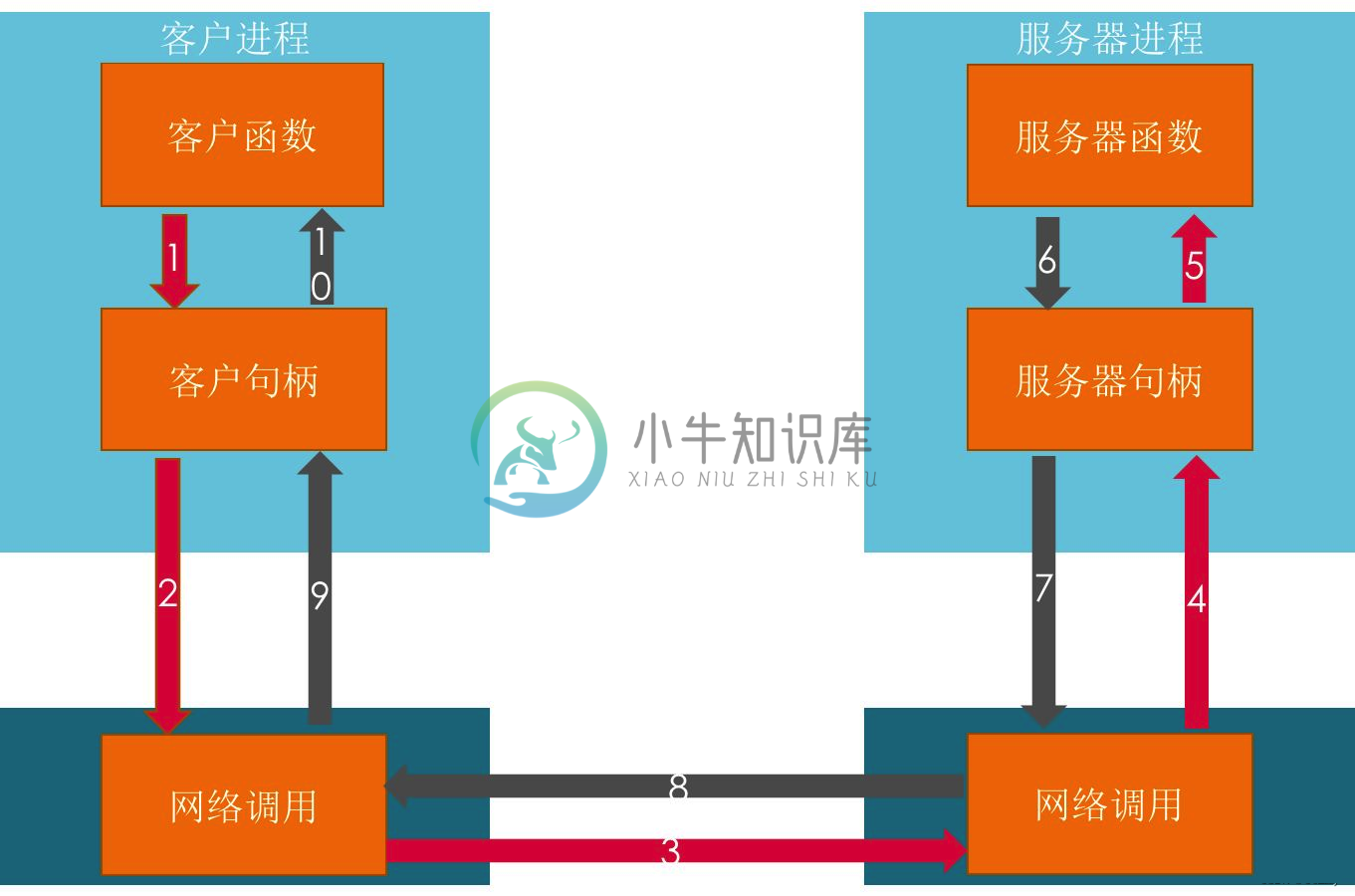 设计一个分布式RPC框架
设计一个分布式RPC框架主要内容:1.RPC流水线工程,2.RPC 技术选型,3.如何设计 RPC1.RPC流水线工程 ① Client以本地调用的方式调用服务 ② Client Stub接收到调用后,把服务调用相关信息组装成需要网络传输的消息体,并找到服务地址(host:port),对消息进行编码后交给Connector进行发送 ③ Connector通过网络通道发送消息给Acceptor ④ Acceptor接收到消息后交给Server Stub ⑤ Server Stub对消息进行解码,
-
 2022/10/29 华锐分布式面试
2022/10/29 华锐分布式面试上午一面技术面,面试官应该是周六没在公司上班但是负责技术面试,都是问的一些很基础的理论知识。不过有几个点我当时不太情况。 1、B+树叶子节点的数据结构 2、双向链表如何判断环,除了用快慢指针之外还有其他的么 下午二面hr面试,聊天进行。
-
微服务 - 分布式事务与acid?
最近在学微服务的分布式事务,不太明白为什么在微服务这种分布式系统中,原有的单体acid会出现问题 希望大佬们可以讲一下原理和思想
-
cassandra stress tool中插入分布下的选择分布比率是什么?
选择分布比率:每个分区应插入的行的比率,占分区的可能总行数的比例(由聚类分布列定义)。默认固定(1)/1 有人能解释一下这是什么意思吗?当它处于插入分配之下时,为什么它被称为选择分配比率? http://www.datastax.com/dev/blog/improved-cassandra-2-1-stress-tool-benchmark-any-schema
-
随机数,分布不均匀
问题内容: 我试图识别/创建一个函数(在Java中),该函数给我一个非均匀的分布式数字序列。如果我有一个函数说它将给我一个从到的随机数。 该函数最适合任何给定的函数,下面仅是我想要的示例。 但是,如果我们说函数将返回来自分布式的s nonuni。 我想例如说 约占所有案件的20%。 大约是所有情况的50%。 约占所有案件的20%。 大约是所有情况的10。 总之somting,给我一个数字,如正态分
-
WordPress类别发布AJAX分页
问题内容: 我真的很难找到一种方法来为我的Wordpress帖子创建使用ajax的分页。我找到的解决方案不起作用。 为了在此提供更多信息,下面是一个链接,该链接的底部具有用于分页的项目符号。单击这些后,我希望网站的效果加载新帖子而不触发页面刷新。 http://maxlynn.co.uk/natural- interaction/category/all/ 我的问题是,对于这种效果,是否有任何好的
-
1.3.2.16 地域分布(按国家)
地域分布(按国家) 关键参数 报告 method metrics(指标, 数据单位) 其他参数 地域分布 visit/world/a (按国家) pv_count (浏览量(PV)) pv_ratio (浏览量占比,%) visit_count (访问次数) visitor_count (访客数(UV)) new_visitor_count (新访客数) new_visitor_ratio (新访
-
动态变化的AnyLogic分布
我有一些方程式,我想根据它进行计算并更新这些值。我找不到任何功能在任何逻辑与此有关。有什么办法实现这一点吗?
-
使用argparse分析布尔值
我想使用argparse解析写为“--foo true”或“--foo false”的布尔命令行参数。例如: 但是,下面的测试代码并没有做我想做的事情: 遗憾的是,的计算结果为。即使我将更改为时也是如此,这是令人惊讶的,因为的计算结果为。 如何使argparse将、及其小写变体解析为?
-
随机化SearchCV采样分布
根据RandomizedSearchCV文件(重点是mine): param_distributions:字典或字典列表 使用参数名称 (str) 作为键的字典,以及要尝试的分布或参数列表。分布必须提供 rvs 方法进行采样(例如来自 scipy.stats.分布的方法)。如果给出了一个列表,则对其进行统一采样。如果给出了字典列表,则首先对字典进行统一采样,然后如上所述使用该字典对参数进行采样。
-
观察的分布(Distribution of Observations)
在我们在前一章中讨论的分类散点图中,该方法在它可以提供的关于每个类别中的值分布的信息中受到限制。 现在,进一步说,让我们看看什么可以促进我们与类别进行比较。 方块图 Boxplot是一种通过四分位数可视化数据分布的便捷方式。 箱形图通常具有从箱子延伸的垂直线,其被称为晶须。 这些晶须表明在上下四分位数之外的可变性,因此Box Plots也被称为box-and-whisker图和box-and-wh
-
概率论07 联合分布
我之前一直专注于单一的随机变量及其概率分布。我们自然的会想将以前的结论推广到多个随机变量。联合分布(joint distribution)描述了多个随机变量的概率分布,是对单一随机变量的自然拓展。联合分布的多个随机变量都定义在同一个样本空间中。 对于联合分布来说,最核心的依然是概率测度这一概念。 离散随机变量的联合分布 我们先从离散的情况出发,了解多个随机变量并存的含义。 之前说,一个随机变量是从