《分布式》专题
-
Hadoop:多用户的伪分布式模式
我很感激你事先的帮助。 我使用root用户凭据在伪分布式模式下设置了Hadoop。我想为多个用户(比如hadoop1、hadoop2等)提供访问权限,以便能够在这个集群上提交和运行MapReduce作业。我们怎么做? 到目前为止我做了什么? 我得到了下面的错误: 为了克服此错误,我授予组“hadoop”对文件夹hdfstmp的rwx权限。此文件夹上的权限类似于drwxrwxr-x。 使用hadoo
-
hadoop作为分布式模式时出错
我尝试使用hadoop作为分布式模式,并且我进行了设置,但是发生了一个错误。我将在下面描述安装过程: 0/etc/hosts 已安装的软件包 获取hadoop 0/etc/hadoop/core-site.xml 0/etc/hadoop/hdfs-site.xml 0/etc/hadoop/mapred-site.xml 主服务器是 节点服务器是 然后我尝试使用这个命令 结果如下: 0node1
-
连接到分布式代理的Eclipse paho
以便当到第一个地址的连接失败时,尝试到下一个地址的连接。 谁能在这里指点一下吗?非常感谢。
-
分布式邮箱Akka actor系统设计
我想创建一个基于AKKA的分布式电子邮件邮箱系统。当我的应用程序启动时,我想创建所有收件箱参与者,并在他们上启动调度器,以接收邮件的时间间隔为10秒。但是有一个问题是如何创建这些收件箱角色?是否可以在集群上创建actor或获得对它的引用(如果它存在的话)?Actor名称可以是数据库中的邮箱UUID,群集中只能存在一个具有特定UUID的Actor。 最重要的问题是如何在集群中创建以uuid为名称的a
-
分布式缓存文件检索问题
因此,对于第一次迭代,我将样例质心文件放在分布式缓存中,使用 在下一次迭代中,我将获取again_input目录,该目录与第一次迭代的输出相同,其中存储了新计算的质心 然而,映射器再次获取它在第一次迭代中获取的质心文件。 下面是在mapper类中提取质心文件的代码: 疑问1:分布式缓存是否会在作业完成后清除所有文件,还是保留这些文件?例如,centroid.txt在迭代1后被清除。 疑点2:我访问
-
Kafka-MongoDB Debezium连接器:分布式模式
我正在开发debezium mongodb源连接器。我可以通过提供kafka引导服务器地址作为远程机器(部署在Kubernetes中)和远程MongoDB URL在分布式模式下在本地机器中运行连接器吗? 我尝试了这一点,我看到连接器成功启动,没有错误,只有几个警告,但没有数据从MongoDB流动。 使用以下命令运行连接器 遵循以下教程:https://medium.com/tech-that-wo
-
通过SSH推送Docker图像(分布式)
我没有掌握整个Docker Hub/Registry的原理。我知道我可以运行私有注册表,但为此我必须建立实际运行服务器的基础结构。 我偷偷地看了看Docker的内部工作(嗯,至少是文件系统),看起来Docker图像层只是一堆tarball,或多或少带有一些复杂的文件命名。我天真地认为,开发一个简单的Python脚本来执行分布式推/拉操作并不是不可能的,但我当然没有尝试过,所以这就是我提出这个问题的
-
 详解MySQL/Redis/ZooKeeper实现分布式锁
详解MySQL/Redis/ZooKeeper实现分布式锁一个挺着啤酒肚,身穿格子衫,发际线严重后移的中年男子,手拿着保温杯,胳膊夹着MacBook向你走来,看样子是架构师级别。 面试开始, 直入正题。 面试官: 你有没有参与过秒杀系统的设计? 我: 没有,我平时都是开发后台管理系统、OA办公系统、内部管理系统,从来没有开发过秒杀系统。 面试官: 嗯...,小伙子很实诚。今天就先到这里吧,后面有消息会主动联系你。 后面还可能有消息吗?你们啥时候主动联系过
-
 (实习)蔚来安卓分布式,HR面?
(实习)蔚来安卓分布式,HR面?承接上文,蔚来二面今天通知过了,明天hr面。 二面内容: 自我介绍 做过什么项目 有没有实习经历 我在做开发的时候有没有遇到什么问题 反问,我问了蔚来车机交互的CAP侧重点,还有Android Framework的含金量 ???当时面完,感觉已经寄了,因为等于啥也没问,而且和一面都有重复的。但是最后,我说了一个MVVM架构里不使用协程,自己定义一个布尔的LiveData,然后在Activity里观
-
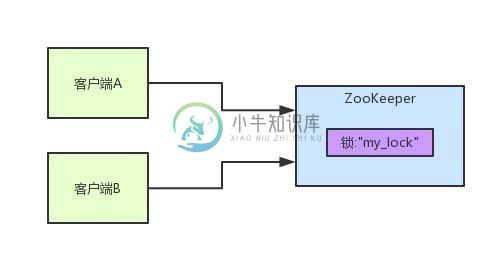 图文并茂:Zookeeper分布式锁原理
图文并茂:Zookeeper分布式锁原理主要内容:写在前面,ZooKeeper分布式锁机制写在前面 之前写过一篇文章(《Redis 分布式锁,没它真不行!》),给大家说了一下Redisson这个开源框架是如何实现Redis分布式锁原理的,这篇文章再给大家聊一下ZooKeeper实现分布式锁的原理。 同理,我是直接基于比较常用的Curator这个开源框架,聊一下这个框架对ZooKeeper(以下简称zk)分布式锁的实现。 一般除了大公司是自行封装分布式锁框架之外,建议大家用这些开源框架封
-
分布式服务层 - ASPNET Core 集成OData
5.5 ABP分布式服务 - ASPNET Core 集成OData 5.5.1 简介 开放数据协议(Open Data Protocol,缩写OData)是一种描述如何创建和访问Restful服务。你可以在Abp中使用OData,只需要通过Nuget来安装Abp.AspNetCore.OData. 5.5.2 安装 1. 使用Nuget安装 首先应该使用Nuget安装Abp.AspNetCore
-
Seata(Fescar)分布式事务 整合 Spring Cloud
针对Fescar 相信很多开发者已经对他并不陌生,当然Fescar 已经成为了过去时,为什么说它是过去时,因为Fescar 已经华丽的变身为Seata。如果还不知道Seata 的朋友,请登录下面网址查看。 SEATA GITHUB:[https://github.com/seata/seata] 对于阿里各位同学的前仆后继,给我们广大开发者带来很多开源软件,在这里对他们表示真挚的感谢与问候。 今天
-
SpringBoot+Dubbo+MybatisPlus 整合 seata 分布式事务
项目地址 前言 事务:事务是由一组操作构成的可靠的独立的工作单元,事务具备ACID的特性,即原子性、一致性、隔离性和持久性。 分布式事务:当一个操作牵涉到多个服务,多台数据库协力完成时(比如分表分库后,业务拆分),多个服务中,本地的Transaction已经无法应对这个情况了,为了保证数据一致性,就需要用到分布式事务。 Seata :是一款开源的分布式事务解决方案,致力于在微服务架构下提供
-
Metrics,日志和跟踪 - 分布式跟踪
本章介绍如何使用Zipkin或Jaeger收集启用了Istio的应用程序的调用链信息。 完成本章后,你可以理解有关应用程序的所有假设以及如何使其参与跟踪,无论您使用何种语言/框架/平台构建应用程序。 BookInfo示例用来作为此任务的示例应用程序。 环境准备 参照安装指南的说明安装Istio。 如果您在安装过程中未启动Zipkin或Jaeger插件,则可以运行以下命令启动: 启动Zipkin:
-
1.2.1 es 的分布式架构原理能说一下么(es 是如何实现分布式的啊)?
面试题 es 的分布式架构原理能说一下么(es 是如何实现分布式的啊)? 面试官心理分析 在搜索这块,lucene 是最流行的搜索库。几年前业内一般都问,你了解 lucene 吗?你知道倒排索引的原理吗?现在早已经 out 了,因为现在很多项目都是直接用基于 lucene 的分布式搜索引擎—— ElasticSearch,简称为 es。 而现在分布式搜索基本已经成为大部分互联网行业的 Java 系