《HPC高性能计算工程师》专题
-
 华为海思-芯片与器件设计工程师-一面面经
华为海思-芯片与器件设计工程师-一面面经一面:约45分钟 面试人数:2人 1.自我介绍 2.介绍一下自己的项目(由于项目经历和数字IC涉及较少,因此询问不多) 3.再度复核了一些笔试中出现的题目,例如FIFO等 4.芯片设计流程;建立保持时间的概念;高速设计的概念;异步逻辑的概念;项目中用的FPGA是什么类型;了不了解锁相环;有没有用触发器做过电路设计。 5.笔试:输入一个起始值,一个目标值,当计数到到目标值的时候,给出一个提示信号 以
-
 美团基础研发 大模型算法工程师实习面经
美团基础研发 大模型算法工程师实习面经一面 自我介绍 项目+论文 为啥项目中使用Ptuning? 说一下Ptuning的原理 如何关注训练过程中的指标? 训练步数如何确定? RLHF的整个流程详细 llama factory代码看过吗? DPO了解吗? 算法题 二分,medium, 旋转数组的最小数字 二面 二面面试官问了很多开放性问题,就是丢给你一个一个问题/实际的步骤,问你怎么解决,怎么考虑,而不是问某某东西的原理 自我介绍 项目
-
 阿里菜鸟CV算法工程师自动驾驶一面凉经
阿里菜鸟CV算法工程师自动驾驶一面凉经9.9面试的,上来没自我介绍环节,直接简历项目开始过,比赛,论文,实习,中间穿插八股:BN和LN区别,transformer encoder组成,BERT等等,应该是都答上来了。 之后手撕,很简单求根号,没用二分,用梯度下降写出来了,被老哥表扬(大四机器学习课考过,做题家基因动了)。 最后说岗位匹配的问题,因为之前没做过自动驾驶,我就拼命说对这个方向感兴趣,自己这两天看过哪些论文(真的是为了这个岗
-
 埃科光电机器视觉算法工程师-技术面面经
埃科光电机器视觉算法工程师-技术面面经lz背景985本日硕机械,课题方向和图像相关性不大,有段工业视觉检测相关的实习背景. 前几天刚面了埃科光电的图像算法处理岗,时长35分钟,面试官是个小伙子,语气很和善,问题还是比较硬核的. 1)自我介绍 2)机械专业为什么不投递结构相关岗位? 3)简述一下视觉相关的实习经历和用到的算法. A:饮料瓶和药瓶的模版匹配 4)模版匹配的目的是什么?常用算法有哪些? 5)(4的回答有提到)LoG是什么?它
-
 科大讯飞 AI算法工程师3D数字人方向 凉经
科大讯飞 AI算法工程师3D数字人方向 凉经岗位:飞星计划-AI算法工程师3D数字人方向 一面 (7/20) - 20min 纯讨论项目 二面 (8/10)- 1h30min 项目中的量纲问题怎么解决 python的相关知识: with args kargs roi pooling batch normalization transformer 深度可分卷积 8.17 感谢信 总结:面试体验并不好,两面面试官都没有开摄像头,也没有自我介绍,
-
 三星西安研究院-图像处理算法开发工程师
三星西安研究院-图像处理算法开发工程师三个面试官,技术面 首先英文自我介绍 看项目里提到的模型和算法,让简单说一下 这个模型(squeezenet)和另一个模型(shufflenet)的区别 数据集是怎么做的,有什么标准 深度可分离卷积和普通卷积的区别 说一下对有参考和无参考质量评价的理解 说一下视频和图像质量评价的区别 暗光增强了解吗,做过什么? 说一下相关的算法,这个算法有什么问题,你有什么改进 有做过轻量化的算法改进和部署吗 反
-
 字节跳动 暑期实习一面 多模态算法工程师
字节跳动 暑期实习一面 多模态算法工程师1.自我介绍 2.介绍第一篇论文和第二篇论文(面试官很认真在听,问了很多细节问题)30min 3.写代码题 给定一个数n和一个int数组A,选取A中元素组成一个最大的且小于n的数,可以重复选取 4.反问组里工作内容 #字节# #字节跳动#暑期实习#
-
 万集科技苏州研究院算法工程师一面感受
万集科技苏州研究院算法工程师一面感受我是同学介绍了解到万集科技苏州研究院的,7月9号投的简历,7月14号HR就通知我面试,面试时间是下午5点。面试官人非常好,主要问我做了哪些项目,然后问了一些3D点云中常见的算法,同时问了一些在做项目过程遇到的一些困难,整体面试体验非常好。然后我问了HR大哥有没有通过一面,大哥和我说通过一面了。目前在等待二面,希望可以顺利通过二面,拿到offer进入万集科技苏州研究院。
-
 经纬恒润算法工程师面试经历,感觉没戏了
经纬恒润算法工程师面试经历,感觉没戏了8.15 一面 约30min 面试官很准时 首先是自我介绍两分钟,我简单说了说自己的专业,说了说研究项目,提了下编程语言和参与的项目。 然后是项目介绍。大概说了15min吧。 再然后就是面试官根据项目内容提问,可能是因为我这个方向有点偏,面试官问的问题都很基础。 之后问了我对卷积的理解。 最后面试官简单介绍了这边是干什么的,询问期望薪资以及工作地点。 反问环节我没问(真不知道问啥) 面试官态度很好
-
 Linux面试题(调试篇)网络性能工具有哪些?
Linux面试题(调试篇)网络性能工具有哪些?沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇章一起了解下网络性能工具。 一、网络性能指标 二、netstat 三、route 四、iptables 一、网络性能指标 从网络性能指标出发,你更容易把性能工具同系统工作原理关联起来,对性能问题有宏观的认识和把握。这样,当你想查看某个性能指标时,就能清楚知道,可以用哪些工具。 二、netstat Netstat是一个用于检查各种网络相关信息
-
如何使用Python的timeit计时代码段以测试性能?
问题内容: 我有一个Python脚本,该脚本可以正常工作,但是我需要编写执行时间。我已经用谷歌搜索了,但是我似乎无法使它正常工作。 我的Python脚本如下所示: 我需要的是执行查询并将其写入文件所需的时间。目的是使用不同的索引和调整机制来测试数据库的更新语句。 问题答案: 您可以在要计时的块之前或之后使用或。 此方法不完全精确(它不会平均运行几次),但是很简单。 (在Windows和Linux中
-
为什么我的反向传播算法的性能会停滞?
我正在学习如何编写神经网络,目前我正在研究一种具有一个输入层、一个隐藏层和一个输出层的反向传播算法。算法正在运行,当我抛出一些测试数据时 在我的算法中,使用3个隐藏单元的默认值和10e-4的默认学习率, 我得到了很好的结果: 每次平方误差之和都会像我预期的那样下降一个十进制。然而,当我使用这样的测试数据时 没有什么真正的改变。我检查了我的隐藏单位、梯度和权重矩阵,它们都不同,梯度确实在缩小,就像我
-
Bellman-Ford算法的正确性,我们还能做得更好吗?
我了解到Bellman-Ford算法的运行时间为O(| E |*| V |),其中E是边的数量,V是顶点的数量。假设图没有任何负加权圈。 我的第一个问题是,我们如何证明在(| V |-1)迭代中(每次迭代检查E中的每条边),它更新到每个可能节点的最短路径,给定一个特定的起始节点?有没有可能我们已经迭代了(|V |-1)次,但仍然没有得到到每个节点的最短路径? 假设算法正确,我们真的能做得更好吗?我
-
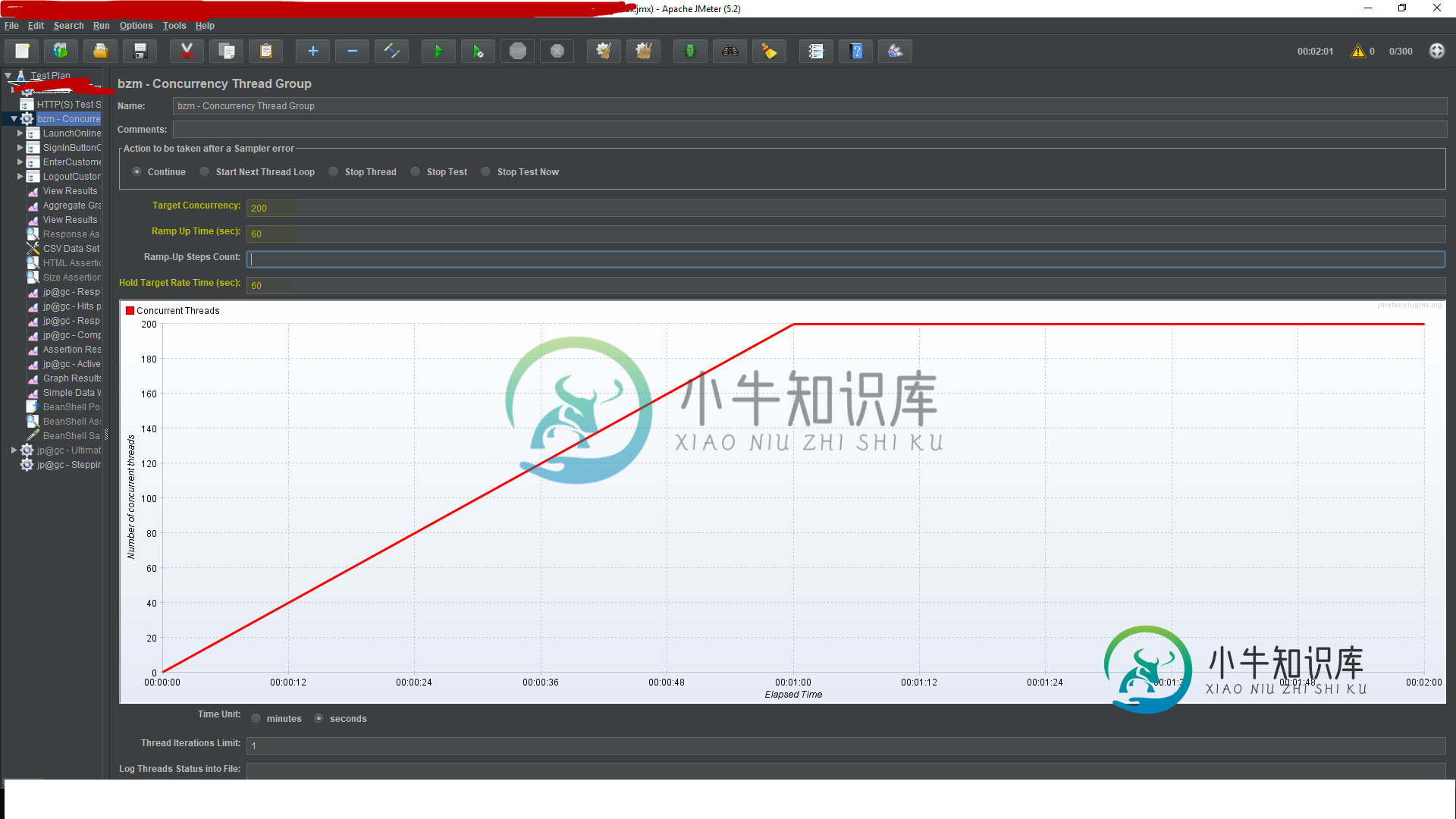 并发线程和最终线程组及性能基准标记
并发线程和最终线程组及性能基准标记在理解并发线程和最终线程组的概念时,我对运行并发线程或最终线程组时的汇总/聚合报告结果的理解感到困惑,例如,如果我有200个用户,上升时间为60秒,那么在成功完成执行后,我并没有看到所有的采样请求都是200个样本,而只有少数采样请求有200个样本。当我使用普通线程组时,每次采样请求完成后,我总是得到相同的线程数。 对于更多用户的实际负载测试,您能否建议我应该选择哪一个线程组。 您是否可以提供一些有
-
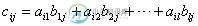 C语言科学计算入门之矩阵乘法的相关计算
C语言科学计算入门之矩阵乘法的相关计算本文向大家介绍C语言科学计算入门之矩阵乘法的相关计算,包括了C语言科学计算入门之矩阵乘法的相关计算的使用技巧和注意事项,需要的朋友参考一下 1.矩阵相乘 矩阵相乘应满足的条件: (1) 矩阵A的列数必须等于矩阵B的行数,矩阵A与矩阵B才能相乘; (2) 矩阵C的行数等于矩阵A的行数,矩阵C的列数等于矩阵B的列数; (3) 矩阵C中第i行第j列的元素等于矩阵A的第i行元素与矩阵B的第j列元素对应乘积