《HPC高性能计算工程师》专题
-
Mysql使用通配符提高搜索性能(%%)
问题内容: 以下是我用于通过电子邮件搜索人的查询 在“电子邮件”上添加索引会加快查询速度吗? 问题答案: 不可以,因为当您使用通配符时,MySQL将无法使用该索引。如果您将LIKE更改为’f%’,那么它将能够使用索引。
-
15.11 用Cython写高性能的数组操作
问题 你要写高性能的操作来自NumPy之类的数组计算函数。 你已经知道了Cython这样的工具会让它变得简单,但是并不确定该怎样去做。 解决方案 作为一个例子,下面的代码演示了一个Cython函数,用来修整一个简单的一维双精度浮点数数组中元素的值。 # sample.pyx (Cython) cimport cython @cython.boundscheck(False) @cython.w
-
提高MySQL查询性能-数学重查询
问题内容: 有人愿意帮助我吗?在具有10000行的MEMORY表上,以下查询大约需要18秒。如果我没有“ where”约束,则只需不到一分钟的时间。我已经打开查询缓存以及将其作为准备好的语句来尝试。有什么我可以做的吗?索引还是什么? 问题答案: 我认为这将为您提供所需的信息,而不管您关注的滚动日期范围…我已经通过创建带有两个标识列的自己的“发票”表进行了测试。使用@mySQL变量实际上非常简单,可
-
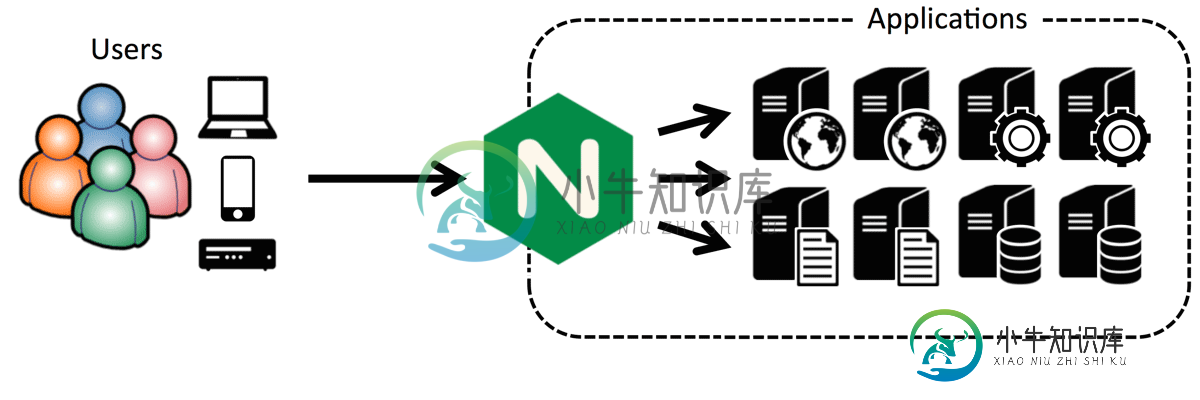 提高Node.js性能的应用技巧分享
提高Node.js性能的应用技巧分享本文向大家介绍提高Node.js性能的应用技巧分享,包括了提高Node.js性能的应用技巧分享的使用技巧和注意事项,需要的朋友参考一下 一、实现一个反向代理服务器 相比大多数应用服务器,Node.js 可以很轻松的处理大量的网络流量,但这并不是 Node.js 的设计初衷。 如果你有一个高流量的站点,提高性能的第一步是在你的 Node.js 前面放一个反向代理服务器。这可以保护你的 Node.js
-
ASP.NET和MSSQL高性能分页实例代码
本文向大家介绍ASP.NET和MSSQL高性能分页实例代码,包括了ASP.NET和MSSQL高性能分页实例代码的使用技巧和注意事项,需要的朋友参考一下 首先是存储过程,只取出我需要的那段数据,如果页数超过数据总数,自动返回最后一页的纪录: 然后是分页控件(... 为省略的生成HTML代码方法): 调用方法:
-
 Android高级开发之性能优化典范
Android高级开发之性能优化典范本文向大家介绍Android高级开发之性能优化典范,包括了Android高级开发之性能优化典范的使用技巧和注意事项,需要的朋友参考一下 本章介绍android高级开发中,对于性能方面的处理。主要包括电量,视图,内存三个性能方面的知识点。 1.视图性能 (1)Overdraw简介 Overdraw就是过度绘制,是指在一帧的时间内(16.67ms)像素被绘制了多次,理论上一个像素每次只绘制一次
-
提高Oracle中跨DBLINK插入CLOB的性能
在尝试将CLOB从一个数据库复制到另一个数据库时,我发现Oracle(11g)的性能很差。我尝试了几件事,但都没能改善这一点。 CLOB用于收集报告数据。这可能是相当大的一个记录到记录的基础上。我在远程数据库(通过WAN)上调用一个过程来构建数据,然后将结果复制回公司总部的数据库进行比较。一般格式为: 为了提高性能,我将远程站点的结果累积到表的远程副本中。在程序运行结束时,我尝试将数据复制回来。此
-
需要帮助提高Hazelcast查询性能吗
我有大约20万张唱片要储存。我已经实现了Java客户端来从hazelcast地图中搜索记录。我没有在预期时间内得到搜索结果。 一旦我做Hazelcast喜欢或在查询,它需要最少400到500毫秒。 是否可以更改服务器端和客户端配置以提高吞吐量? 我用键值将JavaBean信息存储在Map中。我还在一个字段上创建了索引。还实现了身份序列化机制。 服务器端配置(使用XML文件设置服务器): 客户端代码
-
帮助反射的高性能对象缓存
-
Tornado 高性能的秘密:ioloop 对象分析
网上都说nginx和lighthttpd是高性能web服务器,而tornado也是著名的高抗负载应用,它们间有什么相似处呢?上节提到的ioloop对象是如何循环的呢?往下看。 首先关于TCP服务器的开发上节已经提过,很明显那个三段式的示例是个效率很低的(因为只有一个连接被端开新连接才能被接受)。要想开发高性能的服务器,就得在这accept上下功夫。 首先,新连接的到来一般是经典的三次握手,只有当服
-
使用性能探针监视特定功能期间的性能统计信息
问题内容: 我正在尝试使用linux perf工具监视特定功能期间的性能统计信息。 我正在按照https://perf.wiki.kernel.org/index.php/Jolsa_Features_Togle_Event#Example_- _using_u.28ret.29probes上 给出的说明进行操作 我试图获得一个简单的C程序的指令计数。(如下所示) 1)我的简单C代码 2)编译和添
-
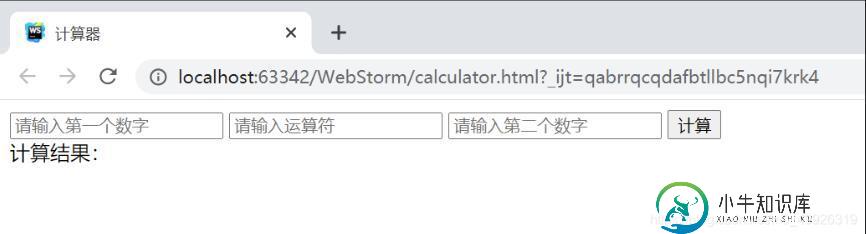 JavaScript实现简易计算器小功能
JavaScript实现简易计算器小功能本文向大家介绍JavaScript实现简易计算器小功能,包括了JavaScript实现简易计算器小功能的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了JavaScript实现简易计算器的具体代码,供大家参考,具体内容如下 运行效果: 测试结果: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
请实现一个计算器的功能
本文向大家介绍请实现一个计算器的功能相关面试题,主要包含被问及请实现一个计算器的功能时的应答技巧和注意事项,需要的朋友参考一下 一种是 a+b 直接运行结果的,前次算术的结果为下一个算术的 a,直到清零或按等于。 一种是在按清零或等于之前可以尽情输入,最后再进行计算,先括号再乘除再加减。 如果还要带上 sin 或 sqrt 之类的,应该也问题不大。
-
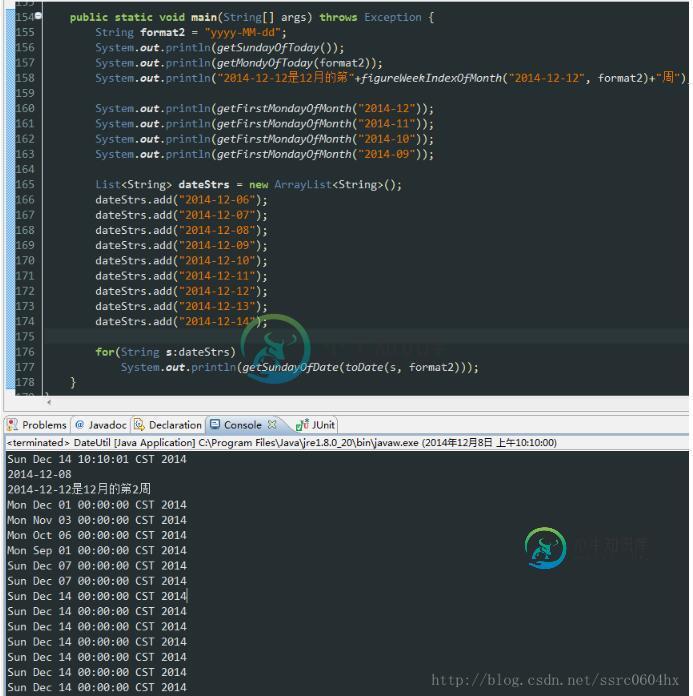 java实现简单日期计算功能
java实现简单日期计算功能本文向大家介绍java实现简单日期计算功能,包括了java实现简单日期计算功能的使用技巧和注意事项,需要的朋友参考一下 本文讲的java日期计算比较偏,用到的地方很少(比如获取今天所在周的周一或者周日,获取今天是本月的第几周...),这些方法是以前做项目遗留下来的,现在整理一下,跟大家分享。 工具类主要有一下方法: public static Date getFirstMondayOfMonth(
-
更高效的多线程可能吗?
我有一个并发哈希映射,我需要在其中更新循环中的值。虽然,并发映射本身是线程安全的,但添加操作不是原子的,因此我需要添加同步块。如果我在这里错了,请纠正我。 问题是是否可以使用锁等更有效地同步此代码?我正在从阻塞队列中获取值。 这是代码: