《高德》专题
-
获取类外部JPanel的宽度和高度
因此,我创建了一个简单的模拟,其中方块是随机产生的,随机向量和窗口边缘的反弹。 我希望它能考虑到正在调整的窗口大小。因此,如果我将窗口的尺寸从600x600改为1200x600,则新边框的方块将会弹出,而不是600x600。 我尝试执行getWidth()getHeight(),但它将返回0。因此,我将它放在pain()(因为它在window resize中被调用)方法中,并将返回值保存为局部变量
-
如何在ProtoBuf中高效地建模HashMap/Dictionary
我有一个由.NET代码序列化的protobuf文件,我想把它用到Java中。在.NET代码中,有字典数据类型,并且proto模式类似于 正如协议缓冲区中的stackoverflow post字典中所述。 我可以使用protoc将原始文件编译成Java类罚款。我可以成功地将protobuf文件反序列化为Java对象。唯一的问题是,它在Java中转换为一个配对对象列表,而不是HashMap。当然,我仍
-
如何在类中设置更高的超时
如果数据不是很大,这是可行的。(例如,最大5 MB) 但如果数据很大,则在10秒后出现超时错误。 是否存在修改该类中默认超时的方法?
-
在DBMS中高效地存储昵称和psswrd
你会选择以下两个选项中的哪一个?为什么? 备选方案1: 备选方案2: 您不知道经理存储每个客户以前的所有用户名和密码是否重要。您只知道每个客户可以随时更改他的密码和他的昵称。不管安全方面,您会遵循哪种方法?
-
内存消耗高于wiredtigercachesizeg中设置的值
你好,专家们 我有一个mongodb服务器在我的2GB ec2实例上运行,使用以下命令 mongod-WiredTigerCacheSizeGb=0.5 下面是我的内存使用情况: 根据我的理解,使用的虚拟地址空间是MongoDB占用的总内存。如果有人能告诉我为什么它会超过0.5(500MB)的限制 内存消耗高于wiredtigercachesizeg中的设置值
-
高级计算器。实现多个操作数
需要一种方法来完成我的'高级'计算器。我一直在用循环头脑Storm,但我困惑自己。任何关于如何实现操作数到数字的想法,而不只是嵌套一堆if语句和硬编码通过所有这些。 公共类计算器{ } }
-
ElasticSearch:如何根据字段值提高分数?
我试图通过根据场值提升_score来摆脱弹性搜索中的排序。这是我的场景: 我的文档中有一个字段:应用日期。这是自EPOC以来经过的时间。我希望具有更大应用日期(最近)的记录具有更高的分数。 如果两个文档的分数相同,我想在另一个字符串类型的字段上对它们进行排序。说“状态”是另一个可以有值的字段(可用、进行中、关闭)。所以,具有相同应用程序日期的文档应该根据状态_score。可用应该有更多的分数,进行
-
极光复制品滞后远高于报道
我们的应用程序使用Amazon RDS Aurora的reader和writer实例。AWS仪表板显示副本延迟持续约为20ms。然而,我们在阅读器上看到的旧结果是在主机上提交后90ms以上,在某些情况下至少高达170ms。 当执行CRUD操作时,我们的应用程序提交数据,然后向客户端发出HTTP重定向以加载新数据。重定向时的网络周转记录在客户端上,通常至少为90ms。我们正在记录应用服务器上的提交时
-
Eureka服务器:如何实现高可用性
-
 HTML5画布调整(缩放)图像高质量?
HTML5画布调整(缩放)图像高质量?我使用html5画布元素在浏览器中调整图像大小。原来质量很低。我发现:当缩放 时禁用插值,但这无助于提高质量。 下面是我的css和js代码,以及用Photoshop缩放和在画布API中缩放的图像。 当在浏览器中缩放图像时,我必须做什么来获得最佳质量? JS: 使用Photoshop调整图像大小: 在画布上调整了图像大小: 下面是我使用2步缩小尺寸的结果: 下面是我使用三步缩小尺寸的结果: 下面是如
-
高输入发送率的Hyperledger Fabric SimulateProposite错误
null 8 GB RAM DDR4 Ubuntu 19.04内核5.0.0-35-泛型 Docker版本19.03.4 docker-compose版本1.21.0 Peerer和orderer的Docker容器在1.4.3版本中使用Fabric映像,但我最近尝试了,结果是一样的。 我使用Hyperledger Caliper以高发送率对提案进行子化处理,其中一些提案被对等方接受(在执行过程中数
-
Cytoscape JS-初始化后修改容器高度
我用如下所示的内容初始化Cytoscape:
-
JDBC对JMeter客户机的CPU要求很高
我用web服务器上的数据库实现了一个JDBC测试计划(我自己构建了一个web服务器)。当我从JMeter客户机开始一个简单的请求时(例如:link),那么JMeter的CPU将在很长一段时间内(约5分钟,但我将测试计划设置为6s:(.在服务器端,CPU占用很短的时间--5-7秒(我想这次是为了查询数据库)。我试图将JMeter.bat中的堆更改为1024M,但没有成功。 你能帮我解决这个问题吗?
-
 如何使用Parse动态单元格高度?
如何使用Parse动态单元格高度?我获取图像的方法是: 行高度设置为: 我也希望有图像被完美填充,很像instagram。我不希望图像的顶部和底部有酒吧。
-
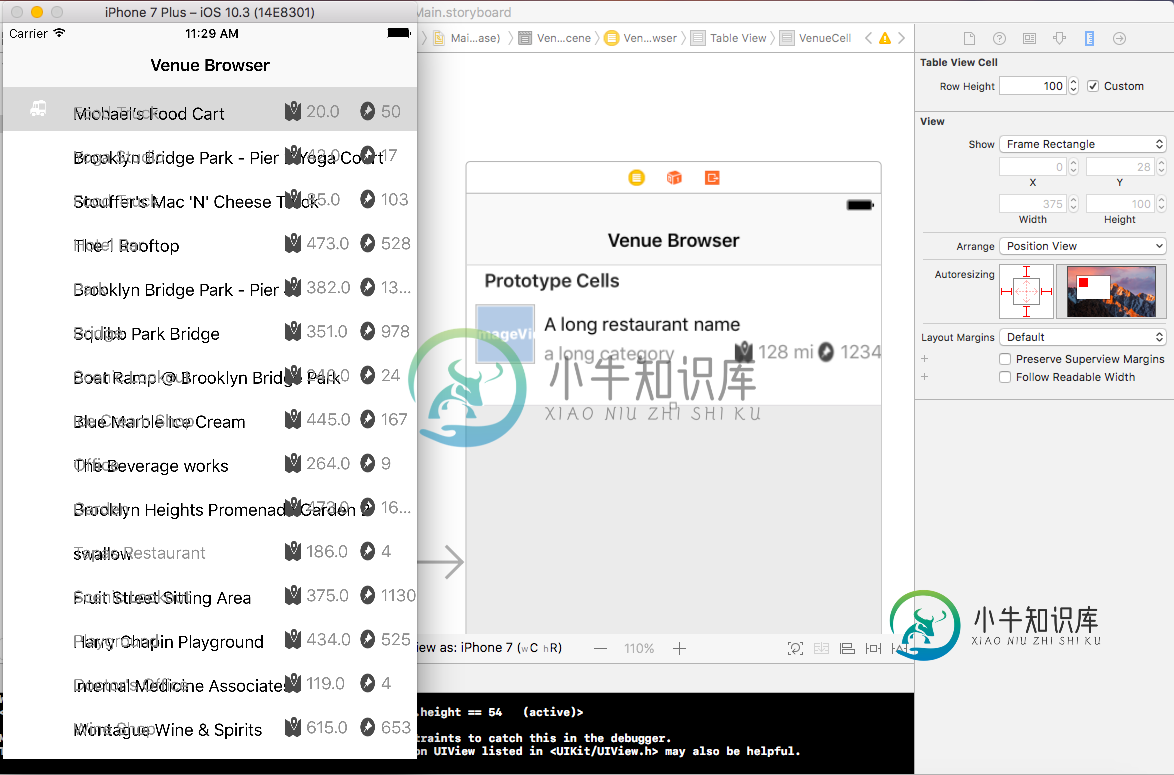 表视图单元格行高不起作用
表视图单元格行高不起作用我已经尝试在表视图单元格中硬编码行高。运行程序后,它看起来只有一行。我怀疑这是因为表视图的行的高度。 你能告诉我这里出了什么问题吗?