《昆仑万维》专题
-
java - 是否有高效读取1000万条Excel数据的Java解决方案?
Java怎么读取很大数据量的 Excel (1000万条数据),希望一行一行读取数据。 目前使用POI进行了文件读取,但是耗费时间很长,大约用了1分钟。大家有没有更快的解决方案
-
如何在Redis中批量删除数十万个带有特殊字符的键
问题内容: 我们有数十万个Redis键的列表,其中包含各种特殊字符,我们希望将其批量删除。 但是,对于以下情况,我似乎找不到答案: 我们有大量的钥匙(数十万个) 键具有各种特殊字符,例如双引号(“),反斜杠(),各种奇怪的Unicode字符等。 我们正在使用Windows Redis-Cli客户端 奖励:理想情况下,我们可以在MULTI / EXEC事务中发出此命令,因此我们也可以自动删除SET和
-
 ASP.NET MVC5+EF6+EasyUI 后台管理系统(81)-数据筛选(万能查询)实例
ASP.NET MVC5+EF6+EasyUI 后台管理系统(81)-数据筛选(万能查询)实例本文向大家介绍ASP.NET MVC5+EF6+EasyUI 后台管理系统(81)-数据筛选(万能查询)实例,包括了ASP.NET MVC5+EF6+EasyUI 后台管理系统(81)-数据筛选(万能查询)实例的使用技巧和注意事项,需要的朋友参考一下 前言 听标题的名字似乎是一个非常牛X复杂的功能,但是实际上它确实是非常复杂的,我们本节将演示如何实现对数据,进行组合查询(数据筛选) 我们都知道Ex
-
与具有几百万行的表上的``=''相比,SQL Server`` <>''运算符非常慢
问题内容: 我有两张表。表单有〜77000行。日志大约有270万行。 以下查询在不到一秒钟的时间内返回“ 30198”: 到目前为止,此查询已运行了约15分钟,但尚未完成: 为什么“不相等”查询 这么 慢? 问题答案: 因为将连接操作从每个表减少到一个匹配行(假定这些docid是唯一的)。 这样想吧-您跳了5个男孩和5个女孩的舞蹈: 您用第一个字母将它们配对。所以 一对配对 但是,如果您通过“首字
-
重新启动Spark Structured Streaming Job会消耗数百万条Kafka消息并死亡
我们有一个运行在Spark2.3.3上的Spark流应用程序 基本上,它开启了一条Kafka流: 我们尝试: > spark.streaming.backpressure.enabled=true以及spark.streaming.backpressure.initialrate=2000和spark.streaming.kafka.maxratePerpartition=1000和spark.s
-
 Python中的pandas.read_csv在Google Drive文件中有1000万行的大型csv文件上
Python中的pandas.read_csv在Google Drive文件中有1000万行的大型csv文件上我从Google Bigquery中提取了一个2列1000万行的。csv文件。 我已经在本地下载了一个大小为170MB的.csv文件,然后将文件上传到Google Drive,我想使用pandas.read_csv()函数将其读入我的Jupyter笔记本中的pandas DataFrame。 这是我使用的代码,有我想读的特定文件ID。
-
如何使用数据流在GCS上自动编辑超过10万个文件?
我在Google云存储上有超过10万个包含JSON对象的文件,我想创建一个镜像来维护文件系统结构,但从文件内容中删除一些字段。 我试图在谷歌云数据流上使用Apache Beam,但它拆分了所有文件,我不能再维护结构了。我正在使用。 我的结构类似于<code>reports/YYYY/MM/DD/ 如何使数据流不拆分文件并使用相同的目录和文件结构输出它们? 或者,是否有更好的系统对大量文件进行此类编
-
如何使用Java从DB2数据库中高效地检索200万条记录?
-
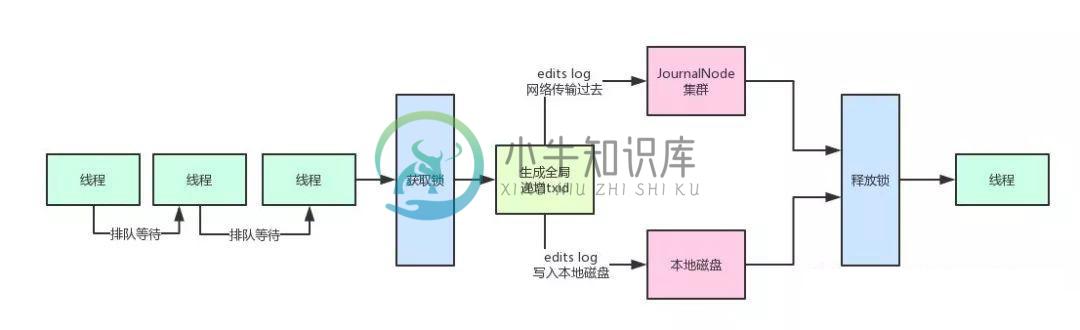 放几十亿数据的系统还能抗每秒上万并发,牛不牛?
放几十亿数据的系统还能抗每秒上万并发,牛不牛?主要内容:一、写在前面,二、问题源起,三、HDFS优雅的解决方案,(1)分段加锁机制 + 内存双缓冲机制,(2)多线程并发吞吐量的百倍优化,(3)缓冲数据批量刷磁盘 + 网络的优化,四、总结一、写在前面 上篇文章我们已经初步给大家解释了Hadoop HDFS的整体架构原理,相信大家都有了一定的认识和了解。 如果没看过上篇文章的同学可以看一下:《兄弟们给我10分钟,带你了解一下大数据技术的入门原理和架构设计!》这篇文章。 本文我们来看看,如果大量客户端对NameNode发起高并发(比如每秒上千次)
-
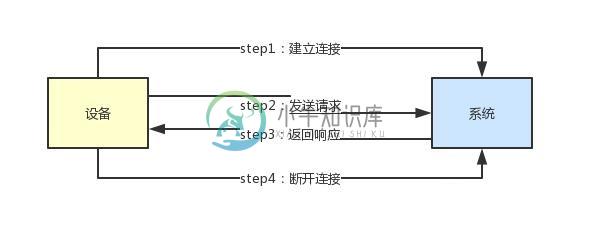 面试官:如何设计一个能支撑百万连接的系统架构!
面试官:如何设计一个能支撑百万连接的系统架构!主要内容:1、到底什么是连接?,2、为什么每次发送请求都要建立连接?,3、长连接模式下需要耗费大量线程资源,4、Kafka遇到的问题:应对大量客户端连接,5、Kafka的架构实践:Reactor多路复用,6、优化后的架构是如何支撑大量连接的?这篇文章,给大家聊聊:如果你设计一个系统需要支撑百万用户连接,应该如何来设计其高并发请求处理架构? 1、到底什么是连接? 假如说现在你有一个系统,他需要连接很多很多的硬件设备,这些硬件设备都要跟你的系统来通信。 那么,怎么跟你的系统通信呢? 首先,他一定会跟
-
求助,.NET反编译有两万多个错误,如何得到正确代码?
公司多年前交付的系统如今需要修复几个漏洞,但是源代码已经丢失,只能获取到IIS上的运行文件。我使用dotpeek进行反编译,得到的代码有两万五千多个错误。代码是.NET mvc的。 将dll反编译后得到的代码有大量反编译工具生成的类似<>o__3.<>p__0的成员变量引用,希望有高手能快速得到正确的可运行的代码。
-
前端表格展示十万级数量的数据,有没有好的方案?
前端表格展示十万级数量的数据,有没有好的方案 就现有的UI库组件,页面会很卡
-
6000万个条目,请从特定月份选择条目。如何优化数据库?
问题内容: 我有一个拥有6000万个条目的数据库。 每个条目包含: ID 数据源ID 一些数据 约会时间 我需要从特定月份中选择条目。每个月约有200万个条目。 from Entries where time between “2010-04-01 00:00:00” and “2010-05-01 00:00:00” (查询大约需要1.5分钟) 我还想从给定的DataSourceID中选择特定月
-
在具有〜225万行的单个表上进行选择查询的优化技术?
问题内容: 我有一个在InnoDB引擎上运行的MySQL表,该表具有大约2,250,000行,其表结构如下: 第一列保存一个从0到2.25M的简单增量值,而&分别保存一个点的一组以十进制度表示的纬度和经度坐标。 这是一个只读表。不会添加其他行,并且唯一需要针对它运行的查询如下: …冒号后面的值是PHP PDO占位符。本质上,此查询的目标是获取表中当前位于Google Maps窗口视口中的所有坐标点
-
如何使用C#将Oracle中的400万条记录更快地插入Elasticsearch表中?
问题内容: 我有以下用C#编写的代码,但是据此,我需要4-5天的时间才能将数据从Oracle数据库迁移到Elasticsearch。我将以100批为单位插入记录。是否还有其他方法可以使400万条记录的迁移速度更快(如果可能的话,可能不到一天)? 问题答案: 该功能将对性能产生负面影响,并且您正在运行数千次。您已经在使用-它不会一次将所有四百万行都拉到您的计算机上,它基本上是一次流一次或几行。 这必