《昆仑万维》专题
-
上千万或上亿的数据,统计其出现次数最多的前N个数据?
本文向大家介绍上千万或上亿的数据,统计其出现次数最多的前N个数据?相关面试题,主要包含被问及上千万或上亿的数据,统计其出现次数最多的前N个数据?时的应答技巧和注意事项,需要的朋友参考一下 做法相同,先hash到小文件,然后hashmap计数比较
-
 使用Go基于WebSocket构建千万级视频直播弹幕系统的代码详解
使用Go基于WebSocket构建千万级视频直播弹幕系统的代码详解本文向大家介绍使用Go基于WebSocket构建千万级视频直播弹幕系统的代码详解,包括了使用Go基于WebSocket构建千万级视频直播弹幕系统的代码详解的使用技巧和注意事项,需要的朋友参考一下 (1)业务复杂度介绍 开门见山,假设一个直播间同时500W人在线,那么1秒钟1000条弹幕,那么弹幕系统的推送频率就是: 500W * 1000条/秒=50亿条/秒 ,想想B站2019跨年晚会那次弹幕系统
-
如何过滤2个包含数百万个相同id项目的巨大列表[重复]
这是我的2个清单上有超过百万的项目。两者都具有相同ID的相同项。ID在字符串中。我只需要一个不一样的ID的项目。我是这样做的。但我确信一定有更好的解决办法,而且具有高度的持久性:- 我尝试使用流,但我做不到。我想用流API应该更好。请建议我有什么改进之处。
-
 【万字面经分享】双非无顶会如何突出重围斩获大厂算法offer
【万字面经分享】双非无顶会如何突出重围斩获大厂算法offerHello 大家好,我是棒棒鸡,秋招已上岸某头部科技公司算法工程师。 24 届毕业的同学们马上也要开始投简历找实习了,不少同学觉得自己现在没有顶会不敢投算法岗,这里我就从去年自己找实习的经历来跟大家分享一下我的一些看法以及一些面经,希望能帮到大家少走弯路,早日拿到自己心仪的 offer。 那先简单介绍一下我的背景: 学历:某双非本(自动化,绩点中上),保研至某双非院校(计科) 本科两届 RoboM
-
 前端 - 类似于阿里云“通义万相”这种ps的魔棒工具怎么实现?
前端 - 类似于阿里云“通义万相”这种ps的魔棒工具怎么实现?网址:https://wanxiang.aliyun.com/app/virtual-model 如图,当前vue项目,求详细实现方式
-
寻找热门查询,300万个查询字符串中统计最热门的10个查询?
本文向大家介绍寻找热门查询,300万个查询字符串中统计最热门的10个查询?相关面试题,主要包含被问及寻找热门查询,300万个查询字符串中统计最热门的10个查询?时的应答技巧和注意事项,需要的朋友参考一下 利用hash映射,将数据映射到小文件中,取1000为例,然后在各个小文件中进行hashmap统计各个串的出现频数,对应进行快排序或者堆排序,找出每个文件中最大频数的,最后将每个文件中最多的取出再进
-
如何批量调整数百万个图像的大小以适合最大宽度和高度?
问题内容: 情况 我正在寻找一种方法来批量调整大小约为1500万个不同文件类型的图像,以适应特定的边框分辨率(在这种情况下,图像不能大于1024 * 1024),而不会扭曲图像,因此保留正确的宽高比。所有文件当前都位于我具有sudo访问权限的Linux服务器上,因此,如果我需要安装任何东西,我很好。 我尝试过的事情 在尝试使用Windows下的某些工具(Adobe Photoshop和其他工具)后
-
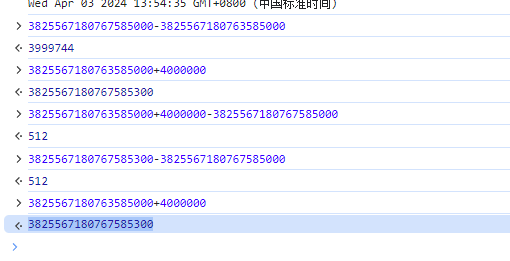 javascript - js 字符串转整数 然后在+百万的数 为什么计算结果会出错?
javascript - js 字符串转整数 然后在+百万的数 为什么计算结果会出错?3825567180763585000 + 100万 200万 300万的时候计算结果都是正常的 为什么 +400万的时候 计算结果就出错了3825567180767585300 怎么保证计算正确性 谢谢
-
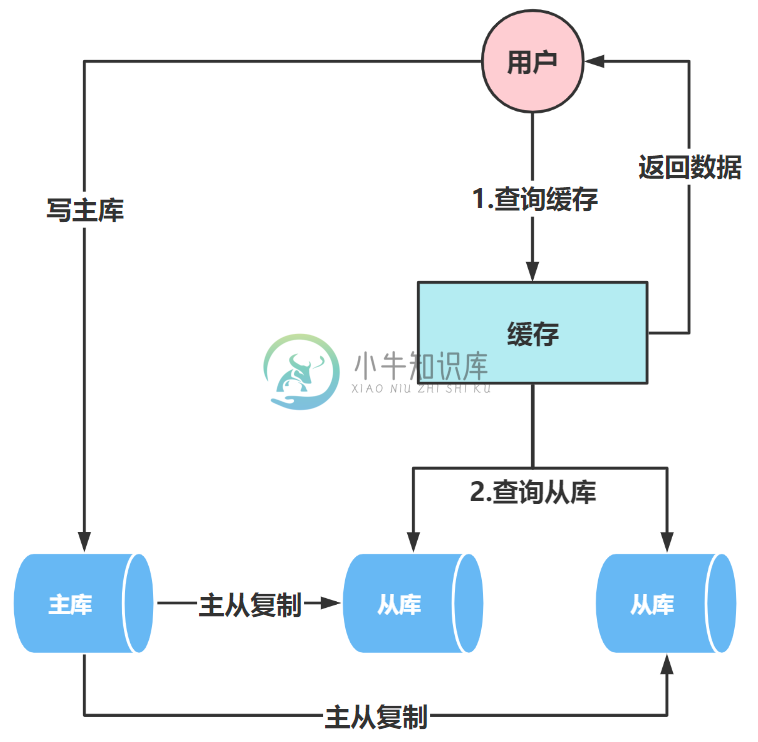 SQL优化实战:如何通过读写分离对千万级数据量查询进行优化?
SQL优化实战:如何通过读写分离对千万级数据量查询进行优化?主要内容:前 言,主从复制的原理是什么?,主从复制的有几种模式?,主从延迟问题和常规解决方案,读写分离实战前 言 订单缓存方案上线之后,我们以为又开启了岁月安好的日子,但是,在一周后的某一天,DBA直接跑来了,DBA直接说:“leader让我直接找你,是这样的,上次加了缓存优化后,效果确实不错,但是我发现订单查询sql在今天的12:00至12:05之间有大量的慢sql,查询时间超过了2.5s。” 这个时候,我们立马开启了排查问题模式,首先,check了一下上次加的缓存,发现缓存正常,然后接着根据
-
高效的Java收集,用于分析CSV文件的输入,该文件包含数百万条记录
假设我有一个csv文件,其中包含以下格式的证券交易信息:时间戳、名称、价格、数量、账户、买入/卖出。该文件可能有数百万条记录,代表当天的交易活动。文件没有排序,我需要选择保存这些数据的最佳Java集合,以便高效地提供分析。 分析例如: 1)卖出最多的股票2)交易最多的账户3)在一个时间范围内购买最多的股票。 基本上,我需要根据不同的字段对这个列表进行多次排序。 所以经过一点搜索,我发现基于树的集合
-
具有8000万条记录的表并添加索引需要超过18个小时(或永远)!怎么办?
问题内容: 简要回顾发生的事情。我正在处理7100万条记录(与其他人处理的数十亿条记录相比,数量并不多)。在另一个线程上,有人建议我的集群的当前设置不适合我的需要。我的表结构是: 然后我添加了7100万条记录,然后执行了以下操作: 已经14个小时了,操作仍然没有完成。在Googling上,我发现有一种解决此问题的著名方法- 分区。我知道我现在需要基于ipaddress对表进行分区,但是我可以在不重
-
我该如何对一百万个数字进行排序,并且仅在Python中打印前十个数字?
问题内容: 我有一个包含一百万个数字的文件。我需要知道如何有效地对其进行排序,以免使计算机停滞不前,并且仅打印前十名。 我知道这是选择排序,我不确定什么是最好的排序。 问题答案: 如果只需要前10个值,则浪费大量时间对每个数字进行排序。 只需浏览数字列表,并跟踪到目前为止看到的前10个最大值。在浏览列表时更新前十名,并在到达末尾时将其打印出来。 这意味着您只需要对文件进行一次遍历(即theta(n
-
给定一个由一百万个数字组成的字符串,返回所有重复的3位数字
几个月前,我参加了纽约一家对冲基金公司的面试,不幸的是,我没有得到数据/软件工程师的实习机会。(他们还要求解决方案使用Python。) 我在第一个面试问题上搞砸了... 000-->999 现在我在考虑,我认为不可能想出一个常数时间的算法。是吗?
-
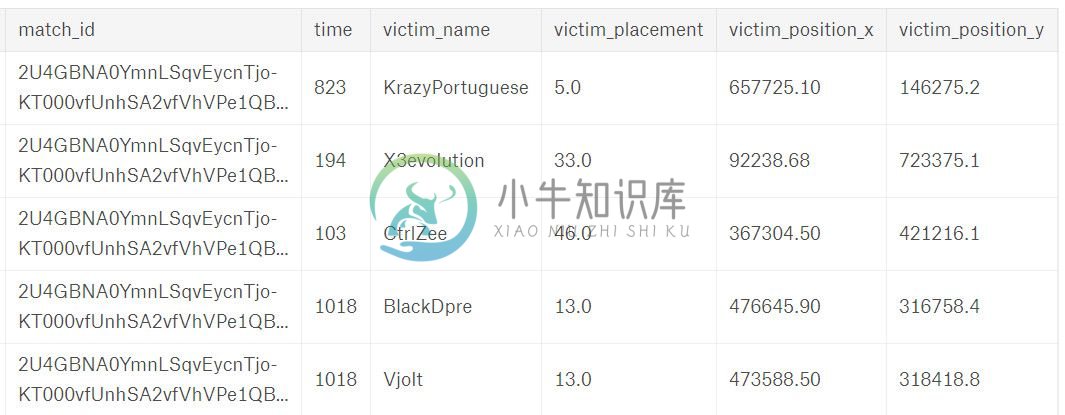 用Python可视化分析绝地求生上万场游戏数据,教你做最强吃鸡攻略啦~
用Python可视化分析绝地求生上万场游戏数据,教你做最强吃鸡攻略啦~导语大吉大利,今晚吃鸡~ 今天跟朋友玩了几把吃鸡,经历了各种死法,还被嘲笑说论女生吃鸡的100种死法,比如被拳头抡死、跳伞落到房顶边缘摔死 、把吃鸡玩成飞车被车技秀死、被队友用燃烧瓶烧死的。这种游戏对我来说就是一个让我明白原来还有这种死法的游戏。但是玩归玩,还是得假装一下我沉迷学习,所以今天就用吃鸡比赛的真实数据来看看如何提高你吃鸡的概率。那么我们就用 Python 和 R 做数据分析来回答以下的灵魂发问?想领取更多完整源码跟Python学习资料可点击这行字体首先来看下数据:.
-
MMO如何处理真人游戏的每一刻为成千上万的玩家计算和发送数据包?
问题内容: 我正在开发游戏,正在考虑进入网络。我从事编程工作已有大约5年的时间,最近2年从事游戏开发。我只在自己的时间里真正地在线学习和学习书籍。我正计划为Amazon AWS EC2创建一个Java服务器,但是我只是想知道MMO如何在每个刻度上处理多个玩家。 仅仅是服务器的强大功能吗?我不是在寻找代码或任何东西,只是在一般情况下服务器是如何工作的。 服务器是否只是对所有播放器以及成千上万个对象进