《昆仑万维》专题
-
搜索成千上万文档(pdf和/或xml)的最佳做法
问题内容: 回顾停滞的项目,并在现代化成千上万的“旧”文档并通过网络提供文档方面寻求建议。 文档以各种格式存在,有些已经过时:(。 doc , PageMaker ,硬拷贝(OCR), PDF 等)。有资金可用于将文档迁移为“现代”格式,许多硬拷贝已被OCR转换为PDF-我们原本以为PDF是最终格式,但我们愿意接受建议(XML?) 。 一旦所有文档都采用通用格式,我们便希望 通过Web界面 提供和
-
SQL对数百万行重复删除查询以提高性能
问题内容: 这是一次冒险。我从上一个问题中的循环重复查询开始,但是每个循环将遍历所有 1700万条记录 , 这意味着将花费数周的时间 (使用MSSQL 2005,运行服务器需要4:30分钟)。我从这个站点和这个帖子中闪现了信息。 并已经到达下面的查询。问题是,对于任何类型的性能,这是否是对1700万条记录运行的正确查询类型?如果不是,那是什么? SQL查询: 问题答案: 看到QueryPlan会有
-
创建数百万个小型临时对象的最佳实践
创建(和发布)数百万个小对象的“最佳实践”是什么? 我正在用Java编写一个国际象棋程序,搜索算法为每一个可能的移动生成一个“移动”对象,一次标称搜索每秒可以轻松生成超过一百万个移动对象。JVM GC已经能够处理我的开发系统上的负载,但我有兴趣探索以下替代方法: 最小化垃圾收集的开销,以及 降低低端系统的峰值内存占用 绝大多数对象的寿命都很短,但生成的移动中约有1%是持久化的,并作为持久化值返回,
-
如何优化大多数出现的值(亿万行)的检索
问题内容: 我正在尝试从包含数亿行的SQLite表中检索一些最常出现的值。 到目前为止,查询可能如下所示: 该字段上有一个索引。 但是,使用ORDER BY子句,查询会花费很多时间,我从未见过它的结尾。 可以采取什么措施来大幅度改善对如此大量数据的此类查询? 我试图添加一个HAVING子句(例如:HAVING count> 100000)以减少要排序的行数,但是没有成功。 请注意,我不太在意插入所
-
如何在JdbcTemboard中使用获取大小来处理2000万行?
我有一个包含2000万行的表,由于,我无法使用单个查询选择所有行。我读到了属性,看起来它可能有助于解决我的问题,因为它是常见的建议 但我对如何应用它有疑问。 我有以下代码: 看起来jdbc驱动程序会为每个请求选择1000。但是我应该怎么做才能处理所有2000万行呢? 我应该调用jdbcTemplate吗。查询几次?
-
编写超过5000万从Pyspark df到PostgresSQL,最有效的方法
从Spark数据框到Postgres表格插入数百万条记录的最有效方法是什么?我在过去通过使用批量复制和批量大小选项也成功地从火花到MSSQL做到了这一点。 有没有类似的东西可以在这里为博士后? 添加我尝试过的代码以及运行流程所需的时间: 所以我做了上面的方法,1000万记录,并有5个并行连接,如中指定的,还尝试了200k的批量大小。 整个过程的总时间为0:14:05.760926(14分5秒)。
-
如何用apache spark处理数百万个较小的s3文件
注意:计数是对处理文件需要多长时间的更多调试。这项工作几乎花了一整天的时间,超过10个实例,但仍然失败,错误发布在列表的底部。然后我找到了这个链接,它基本上说这不是最佳的:https://forums.databricks.com/questions/480/how-do-i-ingest-a-large-number-of-files-from-s3-my.html 然后,我决定尝试另一个我目前
-
 申万宏源产品经理国际业务部面试复盘
申万宏源产品经理国际业务部面试复盘一面 群面 一小时 三个候选人 三个面试官 ——基础问题 第一部分 个人英文自我介绍 一分钟 第二部分 自我评价(优缺点)及理想工作状态 第三部分 你了解到的产品经理完整的工作流程,详细说一下 ——业务问题 第一部分 如何理解国际业务 第二部分 如何理解前台如销售岗位与中台如产品设计岗位 第三部分 中台部门如何与前台部门合作推广一个产品 第四部分 所在实习券商公司有什么比较优势和不足 第五部分
-
 【留学生找工实录】万兴科技产品一面面经
【留学生找工实录】万兴科技产品一面面经牛客网真的是灵到爆炸,来记录一下春招第一场面试,希望能继续保持面试好运拿到offer!! 一面 - 实习经历介绍 - 项目中充当的角色 - 为什么当时要做这个项目,做这个事情,背景的目的,最终产生的价值 - 复盘的话过程中什么地方可以做到更好 - 和设计开发吵架的时候怎么看待 - 产品经理需要的能力 - 对mentor的期望 - 新接手了一个产品,怎么快速接手业务、上手 #产品##求offer##
-
 北京万集科技 面经 (一面+二面)已oc 开奖了
北京万集科技 面经 (一面+二面)已oc 开奖了9.20收到电话 月薪16k 一年13薪,年终双薪,相当于14薪。有公寓(4人)月租金600 每个月300的食堂补贴 8.26一面 测试工程师 一共两个面试官 首先是自我介绍。然后面试官着重问项目,项目原理和算法,抠得很细,还问了代码是多少行之类的问题; 接着就是问关于测试的知识点,但我研究生不是这方向的所以答得不好 之后就是面试官讲了讲他们部门的构成 感觉凉了一半。。。因为后期面试官也没什么要
-
 万集科技(提前批)-- 算法工程师(苏州研究院)
万集科技(提前批)-- 算法工程师(苏州研究院)7.13 一面 专业问答环节 自我介绍 项目1介绍 数据标注中遇到的问题 团队分工以及具体职责 模型推理速度 基线的选择 训练设备以及部署设备 算法性能提升情况 项目2介绍 项目3介绍 聊天环节 薪资考虑 工作地考虑 读研期间工作时间安排 7.19 HR面 自我介绍 家庭情况 为什么选择XX大学 读研期间科研的整个过程 对象问题 职业规划 为什么选择苏州 为什么选择我们,不考虑一些大厂吗 对未来工
-
用三千万影视剧字幕语料库生成词向量
对语料库切词 因为word2vec的输入需要是切好词的文本文件,但我们的影视剧字幕语料库是回车换行分隔的完整句子,所以我们先对其做切词,有关中文切词的方法请见《教你成为全栈工程师(Full Stack Developer) 三十四-基于python的高效中文文本切词》,为了对影视剧字幕语料库切词,我们来创建word_segment.py文件,内容如下: # coding:utf-8 import
-
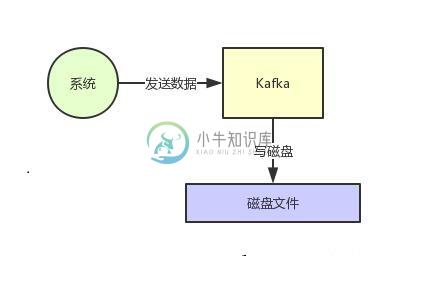 RocketMQ每秒要写入几十万并发,是怎么实现的?
RocketMQ每秒要写入几十万并发,是怎么实现的?主要内容:1、页缓存技术 + 磁盘顺序写,2、零拷贝技术,3、最后的总结这篇文章来聊一下Kafka的一些架构设计原理,这也是互联网公司面试时非常高频的技术考点。 Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。 那么Kafka到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来一点一点说一下。 1、页缓存技术 + 磁盘顺序写 首先Kafka每次接收到数据都会往磁
-
mysql - MYSQL 统计二十九万条数据要13.96秒正常吗?
二十九万条数据要13秒多,是不是有点久?这个语句也没办法优化了吧?
-
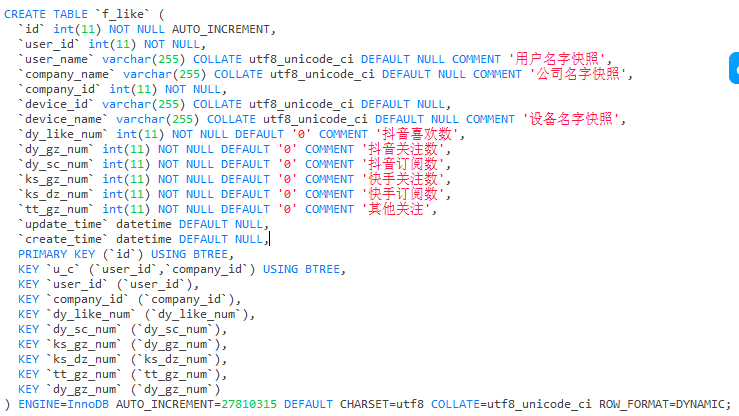 mysql sum多个字段千万级数据如何查询优化?
mysql sum多个字段千万级数据如何查询优化?统计数据表中多个sum千万级数据超时。由于业务需要实时 所以做不来快照表 我加了索引似乎也不管用 后来为了不联表 我直接把快照写入进去了