《感知算法实习》专题
-
Python 实现王者荣耀中的敏感词过滤示例
本文向大家介绍Python 实现王者荣耀中的敏感词过滤示例,包括了Python 实现王者荣耀中的敏感词过滤示例的使用技巧和注意事项,需要的朋友参考一下 王者荣耀的火爆就不用说了,但是一局中总会有那么几个挂机的,总能看到有些人在骂人,我们发现,当你输入一些常见的辱骂性词汇时,系统会自动将该词变成“*”,作为python初学者,就想用python来实现这一功能。 步骤很简单所以就用交互式演示 首先我们
-
 字节前端实习三面(不知何时约hr)
字节前端实习三面(不知何时约hr)之前过了一面和二面,基本都是计算机网络拷打和算法,难度适中,结果三面被拷打了。 主要是拷打了项目,让自己介绍项目然后面试官会抓住自己说到的一些内容进行拷打,比如我提到了小程序和spa和mpa的路由,然后面试官让我实现一个路由功能(原生js); 然后还有对自己的博客进行了全方位拷打,或许自认为博客的广度还可以,但是面试官看重的是某项技术实现的深度,比如xss防护我是怎么做的,有没有了解库的原理,如果
-
如何计算算法的时间复杂度?
我已经通过谷歌和堆栈溢出搜索,但我没有找到一个关于如何计算时间复杂度的清晰而直接的解释。 说代码像下面这样简单: 说一个像下面这样的循环: 这将只执行一次。 时间实际上被计算为而不是声明。
-
通过指针算法计算数组长度
我想知道实际上是如何工作的。我认为这是一种计算数组长度的简单方法,并希望在使用它之前适当地理解它。我对指针算术不是很有经验,但根据我的理解,给出了数组第一个元素的地址。将按地址转到数组的末尾。但是不应该给出这个地址的值吗。而是打印出地址。我真的很感激你帮我把指针的东西弄清楚。 下面是我正在研究的一个简单示例:
-
图的直径计算算法的正确性
null 我相信这个答案是正确的,但我无法证明。有人能证明它为什么起作用或提供一个反例吗?
-
 百度3D计算机视觉算法一面
百度3D计算机视觉算法一面9.11 时长正好60min 首先百度是给我最魔幻体验的公司了,因为一开始自己投了另一个也叫计算机视觉的岗,两天就共享中了,结果前几天自己变更了职位给自己捞进来面试了,自己最近疯狂被简历挂收到面试已经属于正反馈了,就冲这一点我这网盘大会员得永久续费了 然后第二点,自己今天的外出任务出了点意外导致不能按原定时间来,本来没报希望问了下HR,结果HR真给我沟通延迟了一小时!呜呜呜度子这恩情你让我怎么还啊
-
在BouncyCastle上实现带有数字签名算法的椭圆曲线(ECDSA)实现
问题内容: 我正在尝试实现ECDSA(椭圆曲线数字签名算法),但是在Java中找不到使用Bouncy Castle的示例。我创建了密钥,但是我真的不知道我应该使用哪种功能来创建签名并进行验证。 问题答案: owlstead是正确的。要详细说明,您可以执行以下操作: 并验证:
-
用Java实现小球碰壁反弹的简单实例(算法十分简单)
本文向大家介绍用Java实现小球碰壁反弹的简单实例(算法十分简单),包括了用Java实现小球碰壁反弹的简单实例(算法十分简单)的使用技巧和注意事项,需要的朋友参考一下 核心代码如下: 根据x和y递增的值,来决定角度。 以上这篇用Java实现小球碰壁反弹的简单实例(算法十分简单)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
凭据和从GCP实例访问敏感大查询数据的最佳实践?
-
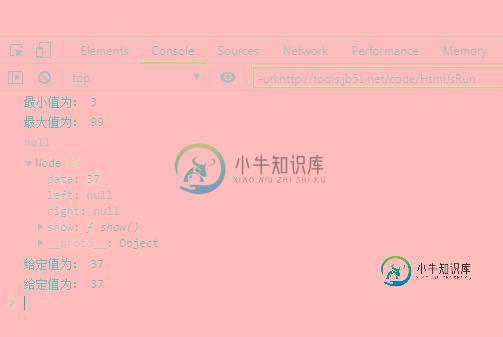 JavaScript数据结构与算法之二叉树实现查找最小值、最大值、给定值算法示例
JavaScript数据结构与算法之二叉树实现查找最小值、最大值、给定值算法示例本文向大家介绍JavaScript数据结构与算法之二叉树实现查找最小值、最大值、给定值算法示例,包括了JavaScript数据结构与算法之二叉树实现查找最小值、最大值、给定值算法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JavaScript数据结构与算法之二叉树实现查找最小值、最大值、给定值算法。分享给大家供大家参考,具体如下: 运行结果: 感兴趣的朋友可以使用在线HTML/CS
-
 Android8.1原生系统网络感叹号消除的方法
Android8.1原生系统网络感叹号消除的方法本文向大家介绍Android8.1原生系统网络感叹号消除的方法,包括了Android8.1原生系统网络感叹号消除的方法的使用技巧和注意事项,需要的朋友参考一下 原生系统Android8.1上,WiFi上出现感叹号,此时WiFi可正常访问。 原因 这是Android 5.0引入的网络评估机制:就是当你连上网络后,会给目标产生204响应的服务器发送给一个请求,如果服务器返回的是状态码为204的响应,那
-
javascript感应鼠标图片透明度显示的方法
本文向大家介绍javascript感应鼠标图片透明度显示的方法,包括了javascript感应鼠标图片透明度显示的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了javascript感应鼠标图片透明度显示的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的javascript程序设计有所帮助。
-
Android M权限:对shouldShowRequestPermissionRationale()函数的用法感到困惑
我正在查看关于Android M中新权限模型的官方文档,其中谈到了函数,如果应用程序先前请求了此权限,而用户拒绝了该请求,则该函数返回。如果用户过去拒绝了权限请求并选择了“不再询问”选项,则此方法返回。 但我们如何区分以下两种情况呢? 情况1:应用程序没有权限,而且用户之前没有被请求获得该权限。在本例中,shouldShowRequestPermissionRationale()将返回false,
-
第三章 算法与数据结构 - 3.1 排序算法汇总
插入排序 1.直接插入排序 思想:每次将一个待排序的数据按照其关键字的大小插入到前面已经排序好的数据中的适当位置,直到全部数据排序完成。 时间复杂度:O(n^2) O(n) O(n^2) (最坏 最好 平均) 空间复杂度:O(1) 稳定性: 稳定 每次都是在前面已排好序的序列中找到适当的位置,只有小的数字会往前插入,所以原来相同的两个数字在排序后相对位置不变。 代码: /** * 插入排序 *
-
字符串的模式匹配详解--BF算法与KMP算法
本文向大家介绍字符串的模式匹配详解--BF算法与KMP算法,包括了字符串的模式匹配详解--BF算法与KMP算法的使用技巧和注意事项,需要的朋友参考一下 一.BF算法 BF算法是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串P的第一个字符进行匹配,若相等,则继续比较S的第二个字符和P的第二个字符;若不相等,则比较S的第二个字符和P的第一个字符,依次比较下去,直到得出最后