《自动驾驶计算机视觉算法实习》专题
-
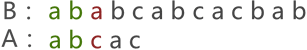 BF算法(串模式匹配算法)
BF算法(串模式匹配算法)主要内容:BF算法原理,BF算法实现,BF算法时间复杂度,总结串的模式匹配算法,通俗地理解,是一种用来判断两个串之间是否具有"主串与子串"关系的算法。 主串与子串:如果串 A(如 "shujujiegou")中包含有串 B(如 "ju"),则称串 A 为主串,串 B 为子串。主串与子串之间的关系可简单理解为一个串 "包含" 另一个串的关系。 实现串的模式匹配的算法主要有以下两种: 普通的模式匹配算法; 快速模式匹配算法; 本节,先来学习 普通模式匹配(BF)
-
算法题 - 一致性哈希算法
一致性哈希算法 tencent2012笔试题附加题 问题描述: 例如手机朋友网有n个服务器,为了方便用户的访问会在服务器上缓存数据,因此用户每次访问的时候最好能保持同一台服务器。 已有的做法是根据ServerIPIndex[QQNUM%n]得到请求的服务器,这种方法很方便将用户分到不同的服务器上去。但是如果一台服务器死掉了,那么n就变为了n-1,那么ServerIPIndex[QQNUM%n]与S
-
数据结构与算法 - KMP算法
KMP算法解决的问题是字符匹配,这个算法把字符匹配的时间复杂度缩小到O(m+n),而空间复杂度也只有O(m),n是target的长度,m是pattern的长度。 部分匹配表(Next数组):表的作用是 让算法无需多次匹配S中的任何字符。能够实现线性时间搜索的关键是 在不错过任何潜在匹配的情况下,我们”预搜索”这个模式串本身并将其译成一个包含所有可能失配的位置对应可以绕过最多无效字符的列表。 Nex
-
计算CET和UTC之间的差异以自动处理夏令时
我正在尝试以更自动的方式处理代码中的夏令时(DST)。我想计算当前UTC时间和CET时间之间的差是一小时还是两小时。我有两个变量,以UTC和CET显示当前日期时间。因为,时间是一样的,所以我将它们的差异设置为0,而不是2。下面是我的代码。任何建议都会有帮助。
-
如何在使用火花数据帧写入时自动计算 numRepartition
当我尝试将数据帧写入Hive Parket分区表时 它将在HDFS中创建大量块,每个块只有少量数据。 我了解它是如何进行的,因为每个 spark 子任务将创建一个块,然后将数据写入其中。 我也理解,块数会提高Hadoop的性能,但达到阈值后也会降低性能。 如果我想自动设置数字分区,有人有一个好主意吗?
-
4 视觉效果
嗯,圆和椭圆还不错,但如果是带圆角的矩形呢? 我们现在能做到那样了么? 史蒂芬·乔布斯 我们在第三章『图层几何学』中讨论了图层的frame,第二章『寄宿图』则讨论了图层的寄宿图。但是图层不仅仅可以是图片或是颜色的容器;还有一系列内建的特性使得创造美丽优雅的令人深刻的界面元素成为可能。在这一章,我们将会探索一些能够通过使用CALayer属性实现的视觉效果。
-
 北森云计算 2024实习-后端工程师
北森云计算 2024实习-后端工程师视频面40分钟 自我介绍 两个栈实现队列(麻了,现场想了好久才想到,之前看过搞完了) 哈希冲突说一下,解决方法(开放地址法,拉链法),拉链法的缺点 什么叫父类引用指向子类引用,好处(就是问多态,没背熟) HashMap里面解决链表长度过长查询速度变慢的方法(背),链表和红黑树的查询时间复杂度 Java中的异常是怎么处理的(try catch, throw) 列举一些你知道的异常 finally代码
-
 OPPO算法岗24届暑期实习
OPPO算法岗24届暑期实习一面技术面 30分钟全在聊paper 二面综合面 20分钟,都是在问我自己课题方向比较宽泛的东西,不是特别深入地抠细节 过了2天了还是没有消息,官网依然显示综合复试已完成 #OPPO信息集散地#
-
 美柚推荐算法实习面试
美柚推荐算法实习面试乱序 1、有了解fm吗。不太熟悉,核心思想是将wij分解为vil和vlj。 2、transformer的注意力机制。x复制3份,交由三个权重矩阵得到qkv,softmax(qk^T)/(根号dk)*v。之后就是一些具体在干嘛的,我说的用这个做的机器翻译,当时是纯手打完transformer成所以比较熟悉,记忆比较深刻,但是面试官好像没继续深入问下去。 3、说一下mmoe。这是一个多任务的双塔模型,
-
 同花顺 AIGC算法实习 一面
同花顺 AIGC算法实习 一面共40分钟 1.自我介绍 2.拷打第一个项目,先让我详细介绍,然后开始提问,主要提问了强化学习里面奖励函数、ppo算法、KL散度相关的; 3.拷打第二个项目,先让我详细介绍,然后问我向量数据库怎么构建的、数据预处理相关的、向量数据库数据量、lora微调的数据量、对比解码减少幻觉的原理、比赛相关的; 4.反问,问了做什么业务和部门氛围 面试官人很好,这次没算法题,整体感觉还是挺好的,八股还是没有单独
-
 美团暑期实习算法面经
美团暑期实习算法面经3.11投递简历 算法岗 3.16笔试 A了3道,其余两道过了70%+20%左右 3.26 一面 投的是CV算法,但是被机器学习/数据挖掘算法岗捞了,以为大概率白给了,前一天恶补了机器学习和概率论的相关知识点,没想到压根没问 时长1h(部分问题有些遗忘) 介绍项目(20min+) 项目中针对模型的设计改进,如何保证,或者说引导模型学习到你期望的能力 介绍Transformer中的位置编码 使用正弦
-
 vivo 搜推广算法实习一面
vivo 搜推广算法实习一面 -
 美团 ai评测算法实习生
美团 ai评测算法实习生8.9 50min 自我介绍 讲一个简历上的项目 项目模型怎么选择的 为什么 数据怎么增强的 了解大模型吗 使用的大模型优点和缺点 了解nlp模型吗 一个概率题 抛骰子直到抛到6为止 求期望 一道编程 nums target 返回加起来等于target的下标集合 问时空复杂度 场景题:怎么判断大模型生成的内容是否对社会有害 面试官小姐姐好温柔 大一之后没做过概率题了完全不会写 编程写出来了但是复杂
-
 小米推荐算法实习一面
小米推荐算法实习一面自我介绍 介绍项目 BERT了解吗,具体讲一下 BERT采用哪种noramlization方式 transfomer为什么要除以dk 推荐算法了解多少,具体讲一下推荐算法框架及流程 手撕代码 查找最小k个数 你有什么要问我的吗
-
 24届 蔚来算法实习面经
24届 蔚来算法实习面经菜的找实习找不到,而且其实也没时间去,上学就得做导师项目。本来打算收手了,打算开学直接投暑期,在Boss上被hr要简历了,然后直接排了面试,这君要臣面臣不得不面啊…但是其实根本不抱任何希望,就当是去体验一下流程,攒个面经。 然后就开始疯狂准备八股。把简历里的yolo,1-5恶补了一下,cpp的八股也是,还有简历里的本科毕设里用的算法(surf啥的)都挖坟出来背。 面试官人很好,氛围很轻松,不那么紧