《视觉算法》专题
-
 滴滴秋储实习视觉算法岗一二面经。
滴滴秋储实习视觉算法岗一二面经。#算法# #视觉算法# #实习# 一面 时间八十分钟。 主要流程: 自我介绍 介绍项目,围绕项目展开提问和交流 长尾分布场景题。 手撕iou,nms,三数乘积。 关于多模态,大模型见解。 反问 二面 时间四十分钟 自我介绍 论文介绍以及项目介绍以及提问 手撕前序遍历递归非递归 优缺点 反问 ps:两位面试官都很nice!
-
 小红书 计算机视觉&多模态 笔试
小红书 计算机视觉&多模态 笔试20道选择(单选+不定项)+ 3道编程 虽然知道没有什么时候是完全准备好的,但是面对不熟悉的知识点还是很down,要继续复习呀! 还是说一下三道编程题吧: 1. 密码:输入是加密后的由小写字母构成的字符串,要求输出加密之前的字符串,加密规律也很简单,就是ascall码+3对应的字符,注意x,y,z加密后分别是a,b,c,解码时对应特殊考虑(只有这题ac了) 2. K排序:输入一个序列arr和每次能
-
 腾讯优图计算机视觉实习二面
腾讯优图计算机视觉实习二面更新:已经进入hr面 ———————————————- 二面面试官经验也很丰富,对技术的考查不多 上来先确认 工作地点和部门 上海腾讯优图实验室 1. 两分钟自我介绍 2. 对简历上哪个工作认为最好 3. 打开ppt简短介绍一下 4. 那个工作的前置工作是哪个(MasaCtrl) 5. 生成评价指标(clip i2i t2i lpips fid等) 6. 怎么判断生成异常歧义的指标(我想不出来没接
-
 地平线计算机视觉面经(已拒绝)
地平线计算机视觉面经(已拒绝)个人背景见之前小红书面经 3.28 一面(40min) 自我介绍 介绍一下多模态项目 介绍一下CVPR论文(面试官竟然看过我的论文,震惊) 这个论文创新点,你认为对车道线检测带来什么样的见解 你对多模态理解是什么 你了解BEV嘛 你知道有哪些车道线检测的范式,2D和3D的 你知道特斯来的自动驾驶最新技术嘛 实习时候复现模型的困难有哪些 还有部分对论文的问答 反问:部门工作,实习生工作。 手撕一道题
-
视觉效果(Visual Effects)
我们可以使用Effects的概念为flex应用程序添加行为。 例如,当文本框获得焦点时,我们可以使其文本变得更大胆,并使其大小稍大。 每个效果都从Effect类继承属性,而Effect类又从EventDispatcher和其他顶级类继承属性。 S.No 效果和描述 1 Flex Effect Class Effect类是一个抽象基类,它定义了所有Flex效果的基本功能。 此类定义所有效果的基础工厂
-
 奥比中光视觉
奥比中光视觉1.实习,项目 2.数据不平衡,focal loss 3.BN层作用 4.如何降低婴儿误检率 5.语义分割了解吗 6.Mobilenet系列发展等
-
 思谋面经 24算法实习生(智能视觉方向)
思谋面经 24算法实习生(智能视觉方向)一面 60min: 问项目、问了一个我研究方向的八股、问了损失函数等DL基础知识 手撕了一道题:根据IOU划分簇,没考虑到连通簇的情况,面试官提醒了一下,写出来了 一面面试官应该是视觉算法工程师,一线程序员,没什么架子,并且了解的面很广 二面 50min: 问项目,问了许多项目,很细节,问多久可到岗,实习到多久 二面第二天问了HR,反馈是通过了,并约了下周HR面 期待第二个Offer
-
 OPPO 视觉算法开发工程师面经 (二面已挂)
OPPO 视觉算法开发工程师面经 (二面已挂)OPPO 计算机视觉算法开发工程师(camera方向) 一面(8.9): 着重介绍一下就是说这个项目里面你这段实习经历里面他有什么需要解决的一个任务,然后遇到了些什么难点,你是怎么解决这些问题的? 怎么提升模型服务CPU和GPU的利用率的? 神经网络是否会出现预测错误的情况,如何改善? 问了一个项目中的损失函数的目的是什么 介绍一下知识蒸馏,不同的蒸馏方法的优劣势 手撕:二叉树按层输出节点(层序遍
-
 美团3.22 计算机视觉转正实习一面
美团3.22 计算机视觉转正实习一面小硕一枚,有幸笔试做两道被美团捞简历,成为第一个暑期给面试的公司 流程: 1.面试官介绍部门做什么的,视觉智能的,现在在做中文的文字可控生成 2.我自我介绍,介绍一下简历上一个印象深刻的项目 3.掰扯一些论文的做法,(他不懂) 然后问我如何端到端训练风格迁移,用扩散模型 4.乱扯了在快手做的事情 5.如果让我做可控文本生成,我会怎么做,发散问题(不会,实在不懂) 6.缩小范围,字体风格迁移要怎么做
-
 美图面试凉经:计算机视觉工程师
美图面试凉经:计算机视觉工程师问是否是面试实习岗(否 针对简历中的项目进行提问,重点是深度学习模型相关,模型结构 询问项目的细节 最后给俩道中等难度算法题,一道二叉树,一道链表 都没做出来,持续尴尬,面试40多分钟就结束了 刷题去了
-
 滴滴-视觉算法工程师-地图-24提前批-一面
滴滴-视觉算法工程师-地图-24提前批-一面大概为了照顾双非本同学的提前批参与感,滴滴给了面试机会 一面40分钟: 计算iou,大概是笔试中比较舒服的哪一种,并不是为了考察思维能力这些,大概就是经典题目慢慢优化,在优化中判断你的工程能力之类的。 项目:讲讲实习中做了什么,一问一答,大概就是这样。 表现比上次好一些,这次至少把实习做的东西将清楚了。不过感觉一直没有聊到面试官擅长的领域,挂的概率80%#提前批面试##如何判断面试是否凉了#
-
Eclipse中的视觉摆动
问题内容: 有什么方法可以使用可视化编辑器在Eclipse中制作swing应用程序?我正在使用Ganymede。 问题答案: 我使用Jigloo相当不错。可以为Swing和SWT生成GUI。免费用于非商业用途,以商业用途每位开发人员$ 85美元,相当便宜。适用于3.4(Ganymede)。
-
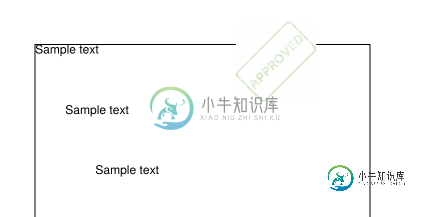 pdfbox 1.8.8的视觉签名
pdfbox 1.8.8的视觉签名我正在尝试制作带有视觉签名和pdfbox的PDF。我有两条流,pdfbox似乎只能处理文件。没有三个临时文件,我没能成功。我可以从这里看到API已经改变了,但它仍然处理文件。 除了文件疯狂,我在签名上没有看到任何文字。结果是这样的: 当我用itext库做类似的事情时,情况就是这样 为什么视觉签名表示中缺少名称、位置和原因?我该怎么解决?
-
 腾讯 WXG视觉设计
腾讯 WXG视觉设计一面(30min+) 电话面试,应该是部门负责人面试。上来介绍自己是微信事业群负责视频号部门的。 1.开始自我介绍 2.针对我在京东实习的项目和一些部门架构做了一些粗略提问 3.接着就是让自己选一个最喜欢的项目进行细化介绍 4.最后问我是否有动效和剪辑方面的经验,表示如果有可以加分,没有不影响,可以进入之后慢慢培养(当时觉得面试官这句话好暖人,居然不嫌弃)。 5.最后我询问了下面试官如果自己进入该
-
视觉问答(VQA)综述
相关论文 [2016].Visual Question Answering 本文从数据集、评价方法、算法等方面讨论了 VQA 的现状及存在的问题,以及 VQA 的未来发展方向;特别讨论了现有数据集在训练和评价方面的局限性。 VQA 的难点 目前大多数关于图像的任务并不需要完全理解图像包含的信息。比如图像分类、物体检测、动作识别等。而解决 VQA 问题需要完全理解图像。 VQA 的问题可以使任意的,