《视觉算法》专题
-
AnyLogic排序算法
在AnyLogic中,我们可以执行max和min来找出两个值之间的最大值或最小值。然而,我如何执行(例如)5个值的排序,其中每个值存储在一个变量中(用于基于代理的建模)? 事先非常感谢。如果你认为更多的细节应该提供,也请让我知道。
-
javascript变更算法
我正在用javascript解决“进行更改”的问题: 问题: 给定一定数量的货币,一组硬币面额,计算使用可用面额的硬币制造货币的方法的数量。 例子: 对于金额=4(4),面额=[1,2,3](1,2,2和3),您的程序将输出4-使用这些面额制作4的方法的数量: 1,1,1,1 1¢, 1¢, 2¢ 1¢, 3¢ 2¢, 2¢ 我找到了一个解决方案: 问题: 有人能给我解释一下发生了什么事吗?我试图
-
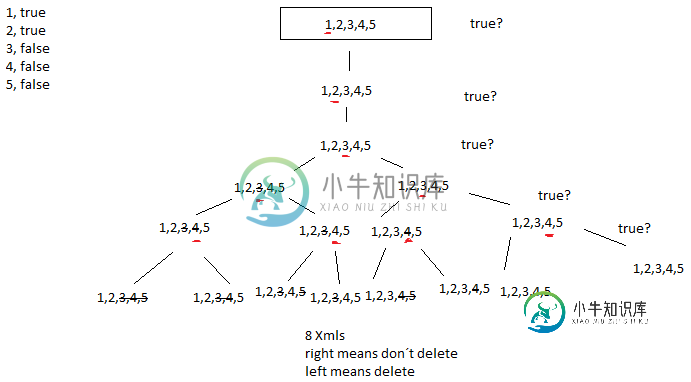 树结构算法
树结构算法我的程序有问题。例如,我有5个字段。这些字段的值为或<代码>错误字段可以删除。所以我想找到这些领域的所有可能组合。 我的想法是:例如,我有一个包含这些字段的XML 字段1,正确 字段2,正确 字段3,错误 字段4,错误 第五场,错 结果应该是: 8种组合。 表示删除,表示不删除。 我无法实现复制功能。所以我只有4个Xmls结果: 有人能帮我吗? 首先,我感谢你的第一次支持。 字段矩阵类看起来像:
-
DNA分裂算法
在第二种聚合物的情况下,它将是'b'而不是'a'。当然,如果选择了最终的聚合物,则翻转的定义如下 A[127]=2*A[126]+A[127] 需要注意的是,由于翻转,位置将改变为2、0或-2。 不管怎么说,现在我的问题是,平衡距离比应该的要高得多。理想情况下,我被告知它应该是0,或者最大可能是2和4。比这更大的可能性是微乎其微的。但我的代码经常给出22、30等值。谁能告诉我怎么了?请随时要求进一
-
Python贪婪算法
有人有线索为什么它对案件2不起作用吗?非常感谢你的帮助。编辑:案例2的预期结果是6130美元。我好像得到了6090美元。
-
无法计算getTotalFlightTime()
Itinerary类存储有关具有以下成员的旅程的信息: •一个名为flights的私有ArrayList数据字段,其中包含按DepartureTime递增顺序排列的旅程航班。(提示:您不需要进行排序。) •使用ArrayList类型的指定航班创建旅程的构造函数。 •名为getTotalFlightTime()的方法,以分钟为单位返回旅程的总飞行时间。(提示:为每个飞行对象调用getFlightTi
-
Java通用算法
我正在尝试创建一些Java类,这些类可以使用浮点数或双倍数(出于模拟目的,我需要同时支持这两种类型)。这些类需要做一些基本的算术运算,还需要使用三角函数(sin、cos、atan2)。 我尝试了一种通用的方法。因为Java不允许在泛型和
-
硬算法实现
我无法实现SJF(最短作业优先)算法。 SJF就是这样工作的 如果进程到达0时间,它将工作到下一个进程到达,算法必须检查到达1的到达(进程/进程)是否比当前剩余时间短 示例:P0执行了1,还有2要完成,现在我们有P0,P1,P2,P3,P4 in 1算法将执行最短的一个P3,之后是P0,然后是P4,然后是P1,依此类推。问题是我必须保存所有进程的开始和结束时间执行,以及等待时间。 这是我的最新算法
-
 TPLINK 算法面经
TPLINK 算法面经提前批刚开就投了,一面07.01,二面7.20,三面07.29,座谈会08.17,08.25 sp call 通知是SSP -------------------------------------------------------------------------------------------------------------------------------- 具体的面试内容记得
-
 京东算法OA
京东算法OA两部分 第一部分机器学习八股+简单代码判断 不算太难 第二部分coding,前两题顺利AC,第三题判断括号数量期望用的O(2^n)的强行暴力的递归法,时间复杂度超了只通过25%。
-
加解密算法
加解密算法 算法类型 特点 优势 缺陷 代表算法 对称加密 加解密密钥相同或可推算 计算效率高,加密强度高 需提前共享密钥;易泄露 DES、3DES、AES、IDEA 非对称加密 加解密密钥不相关 无需提前共享密钥 计算效率低,仍存在中间人攻击可能 RSA、ElGamal、椭圆曲线系列算法 算法体系 现代加密算法的典型组件包括:加解密算法、加密密钥、解密密钥。其中,加解密算法自身是固定不变的,一般
-
PrefixSpan算法原理
首先我们看看项集数据和序列数据有什么不同,如下图所示。 左边的数据集就是项集数据,在Apriori和FP Tree算法中我们也已经看到过了,每个项集数据由若干项组成,这些项没有时间上的先后关系。而右边的序列数据则不一样,它是由若干数据项集组成的序列。比如第一个序列<a(abc)(ac)d(cf)>,它由a,abc,ac,d,cf共5个项集数据组成,并且这些项有时间上的先后关系。对于多于一个项的项集
-
Apriori算法原理
什么样的数据才是频繁项集呢?也许你会说,这还不简单,肉眼一扫,一起出现次数多的数据集就是频繁项集吗!的确,这也没有说错,但是有两个问题,第一是当数据量非常大的时候,我们没法直接肉眼发现频繁项集,这催生了关联规则挖掘的算法,比如Apriori, PrefixSpan, CBA。第二是我们缺乏一个频繁项集的标准。比如10条记录,里面A和B同时出现了三次,那么我们能不能说A和B一起构成频繁项集呢?因此我
-
SMO算法原理
1. 回顾SVM优化目标函数 我们首先回顾下我们的优化目标函数: $$ min(alpha);; frac{1}{2}sumlimits_{i=1,j=1}{m}alpha_ialpha_jy_iy_jK(x_i,x_j) - sumlimits_{i=1}{m}alpha_i $$ $$ s.t. ; sumlimits_{i=1}^{m}alpha_iy_i = 0 $$ $$ 0 leq a
-
Raft 算法解读
Raft 新特性 Strong Leader 更强的领导形式 例如日志条目只会从领导者发送到其他服务器, 这很大程度上简化了对日志复制的管理 Leader Election 使用随机定时器来选举领导者 用最简单的方式减少了选举冲突的可能性 Membership Change 新的联合一致性 (joint consensus) 方法 复制状态机 1. 复制状态机通过日志实现 每台机器一份日志 每个日