
树结构算法

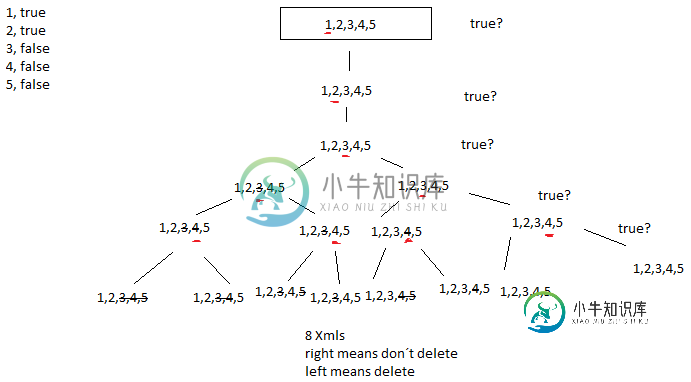
我的程序有问题。例如,我有5个字段。这些字段的值为true或false<代码>错误字段可以删除。所以我想找到这些领域的所有可能组合。
我的想法是:例如,我有一个包含这些字段的XML
- 字段1,正确
- 字段2,正确
- 字段3,错误
- 字段4,错误
- 第五场,错
结果应该是:
{Field1, Field2, Field3, Field4, Field5}
{Field1, Field2, , Field4, Field5}
{Field1, Field2, , , Field5}
{Field1, Field2, , , }
{Field1, Field2, Field3, , Field5}
{Field1, Field2, Field3, , }
{Field1, Field2, Field3, Field4, }
{Field1, Field2, , Field4, }
8种组合。
public List<List<Fieldmatrix>> permut(List<Fieldmatrix> matrix, int j) {
while (felderLaenge != j) {
if (!matrix.get(j).isTrue()) {
tmpL = iterateLeft(matrix, j);
tmpR = iterateRight(matrix, j);
} else {
tmpL = iterateRight(matrix, j);
}
j++;
return permut(tmpL, j);
}
return sammlung;
}
iterateLeft表示删除,iterateRight表示不删除。
我无法实现复制功能。所以我只有4个Xmls结果:{1,2,3,4,5},{1,2,4,5},{1,2,3,5},{1,2,3,4}
有人能帮我吗?
首先,我感谢你的第一次支持。
字段矩阵类看起来像:
public class Fieldmatrix {
private String feld;
private boolean pflicht;
public Fieldmatrix(String feld, boolean pflicht){
this.feld = feld;
this.pflicht = pflicht;
}
public String getFeld() {
return feld;
}
public void setFeld(String feld) {
this.feld = feld;
}
public boolean isPflicht() {
return pflicht;
}
public void setPflicht(boolean pflicht) {
this.pflicht = pflicht;
}
}
我怎样才能改变这部分"prefix with Field.add(?)"你用String来处理它,这是可行的,因为List也是String的类型。但是我使用List。
iterateRight()仅在控制台上打印。ieterateLeft()删除当前字段并使用控制台打印。
共有1个答案

存在多个问题:
- 如果当前树节点有两个子节点,则必须同时进入这两个节点,而不仅仅是左侧节点
- 最后,您返回了
sammlung(engl.collection),但从未添加任何元素(至少不在呈现的代码中) - 结合递归的
while循环似乎有些奇怪。但是我不能在不看iterateLeft和iterateRight的情况下谈论这一点
实现该函数的快速方法如下。为了简单起见,Fieldmate类被String替换。
public static List<List<String>> combine(List<String> fields) {
return combine(fields, 0, new ArrayList<>());
}
public static List<List<String>> combine(List<String> fields,
int start, List<String> prefix) {
List<List<String>> combinations = new ArrayList<>();
if (start >= fields.size()) {
combinations.add(prefix);
return combinations;
}
String field = fields.get(start);
if (field.contains("false")) {
combinations.addAll(combine(fields, start + 1, prefix));
}
List<String> prefixWithField = new ArrayList<>(prefix);
prefixWithField.add(field);
combinations.addAll(combine(fields, start + 1, prefixWithField));
return combinations;
}
这种实现效率不高。许多中间结果被一次又一次地复制。
List<String> fields = new ArrayList<>();
fields.add("1:true");
fields.add("2:true");
fields.add("3:false");
fields.add("4:false");
fields.add("5:false");
combine(fields).forEach(c -> System.out.println(c));
印刷品
[1:true, 2:true] [1:true, 2:true, 5:false] [1:true, 2:true, 4:false] [1:true, 2:true, 4:false, 5:false] [1:true, 2:true, 3:false] [1:true, 2:true, 3:false, 5:false] [1:true, 2:true, 3:false, 4:false] [1:true, 2:true, 3:false, 4:false, 5:false]
-
二叉树 二叉树:二叉树是有限个结点的集合,这个集合或者是空集,或者是由一个根结点和两株互不相交的二叉树组成,其中一株叫根的做左子树,另一棵叫做根的右子树。 二叉树的性质: 性质1:在二叉树中第 i 层的结点数最多为2^(i-1)(i ≥ 1) 性质2:高度为k的二叉树其结点总数最多为2^k-1( k ≥ 1) 性质3:对任意的非空二叉树 T ,如果叶结点的个数为 n0,而其度为 2 的结点数为 n
-
二叉树 L、D、R分别表示遍历左子树、访问根结点和遍历右子树 先序遍历:DLR 中序遍历:LDR 后序遍历:LRD 仅有前序和后序遍历,不能确定一个二叉树,必须有中序遍历的结果 二叉树的性质 性质1:在二叉树中第 i 层的结点数最多为2^(i-1)(i ≥ 1) 性质2:高度为k的二叉树其结点总数最多为2^k-1( k ≥ 1) 性质3:对任意的非空二叉树 T ,如果叶结点的个数为 n0,而其度为
-
树是一种非线性的数据结构,以分层的方式存储数据,它对于存储需要快速查找的数据非常有用。 树是一种一对多的数据结构。树又有很多子集,比如:二叉树、二叉搜索树、2-3树、红黑树等等。 现实例子就是公司的组织架构,总裁为树的最顶端叫根节点,各部门按照领导人区分为子树。 在计算机科学中,HTML结构就是典型的树结构 树的节点可以有0个或多个子节点。当一棵树(的所有节点)最多只能有两个子节点时,这样的树被称
-
主要内容:一个 XML 文档实例,XML 文档形成一种树结构,实例:,XML 文档实例XML 文档形成了一种树结构,它从"根部"开始,然后扩展到"枝叶"。 一个 XML 文档实例 XML 文档使用简单的具有自我描述性的语法: <?xml version="1.0" encoding="UTF-8"?> <note> <to>Tove</to> <from>Jani</from> <heading>Reminder</heading> <body>Don't forget me th
-
连通图:在无向图G中,若从顶点i到顶点j有路径,则称顶点i和顶点j是连通的。若图G中任意两个顶点都连通,则称G为连通图。 生成树:一个连通图的生成树是该连通图的一个极小连通子图,它含有全部顶点,但只有构成一个数的(n-1)条边。 最小生成树:对于一个带权连通无向图G中的不同生成树,各树的边上的 权值之和最小。构造最小生成树的准则有三条: 必须只使用该图中的边来构造最小生成树。 必须使用且仅使用(n
-
主要内容:树的结点,子树和空树,结点的度和层次,有序树和无序树,森林,树的表示方法,总结之前介绍的所有的 数据结构都是 线性存储结构。本章所介绍的树结构是一种非线性存储结构,存储的是具有“一对多”关系的数据元素的集合。 (A)