《强化学习》专题
-
强化学习:随机策略梯度,AC家族(AC,A2C,A3C)
前面那些值函数的方法,当值函数最优时,可以获得最优策略。最优策略是状态 s 下,最大行为值函数对应的动作。当动作空间很大的时候,或者是动作为连续集的时候,基于值函数的方法便无法有效求解了。因为基于值函数的方法在策略改进时,需要针对每个状态行为对求取行为值函数,以便求解 arg\,\underset{a\in A}{max}\,Q(s,a)。这种情况下,把每一个状态行为对严格独立出来,求取某个状态下应该执行的行为是不切实际的。
-
强化学习:蒙特卡罗,时序差分,多步时序差分
蒙特卡罗方法也称为统计模拟方法(或称统计实验法),是一种基于概率与统计的数值计算方法。该计算方法的主要核心是通过对建立的数学模型进行大量随机试验,利用概率论求得原始问题的近似解,与它对应的是确定性算法。
-
强化学习(实践):多臂老虎机,动态规划,时序差分
在多臂老虎机(Multi-Armed Bandit,MAB)问题中,有一个拥有 K 根拉杆的老虎机,每一个拉杆都对应一个关于奖励的概率分布 R。我们每次拉下其中一根拉杆,就可以获得一个从该拉杆对应的奖励概率分布中获得一个奖励 r。我们的目标是: 在各个拉杆奖励的概率分布未知的情况下,从头开始尝试,并在操作 T 次拉杆后,获得尽可能多的累积奖励。由于奖励的分布是未知的,我们就需要在“探索拉杆的获奖概率”和“根据经验选择获奖最多的拉杆”中进行权衡。
-
TensorBoard:可视化学习
TensorBoard 涉及到的运算,通常是在训练庞大的深度神经网络中出现的复杂而又难以理解的运算。 为了更方便 TensorFlow 程序的理解、调试与优化,我们发布了一套叫做 TensorBoard 的可视化工具。你可以用 TensorBoard 来展现你的 TensorFlow 图像,绘制图像生成的定量指标图以及附加数据。 当 TensorBoard 设置完成后,它应该是这样子的: 数据序列
-
 Flappy.Bird开发者,怎么利用DNQ方法强化学习你的游戏AI
Flappy.Bird开发者,怎么利用DNQ方法强化学习你的游戏AI本文向大家介绍Flappy.Bird开发者,怎么利用DNQ方法强化学习你的游戏AI相关面试题,主要包含被问及Flappy.Bird开发者,怎么利用DNQ方法强化学习你的游戏AI时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 强化学习是机器学习里面的一个分支。它强调如何基于环境而行动,以取得最大化的预期收益。其灵感来源于心理学中的行为主义理论,既有机体如何在环境给予的奖励或者惩罚的刺激下,逐
-
解析化学式
问题内容: 我正在尝试为应用程序编写一种方法,该方法采用化学式(例如“ CH3COOH”)并返回充满其符号的某种集合。 CH3COOH将返回[C,H,H,H,C,O,O,H] 我已经有一些可以工作的东西了,但是它非常复杂,并且使用了很多带有嵌套if-else结构和循环的代码。 有没有一种方法可以通过将某种正则表达式与String.split一起使用,或者以其他出色的简单代码来实现? 问题答案: 假
-
11.4 计算化学
11.4 计算化学 化学在传统上一直被认为是一门实验科学,但随着计算机技术的应用,化学家成为大规 模使用计算机的用户,化学科学的研究内容、方法乃至学科的结构和性质随之发生了深刻变 化。计算化学(computational chemistry)是化学和计算机科学等学科相结合而形成的交叉学 科,其研究内容是如何利用计算机来解决化学问题。计算化学这个术语早在 1970 年就出现 了,并且在上世纪 70
-
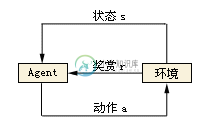
强化学习:基本概念,马尔可夫,贝尔曼方程,动态规划
在机器学习范畴内,根据反馈的不同,学习技术可以分为监督学习、非监督学习和强化学习三大类。强化学习是处于完全监督和完全缺乏预定义标签之间,又称为增强学习、加强学习和激励学习,是一种从环境状态到行为映射的学习,目的是使动作从环境中获得的累计回报(奖励)值最大。强化学习主要是智能体(Agent)与环境(Environment)的交互过程。强化学习有一个很大的优势,它可能是超越人类的。监督学习中,比如分类问题,最好的结果就是人类的标注水平,这是一个上界。
-
3.3 TensorBoard:可视化学习
TensorBoard 涉及到的运算,通常是在训练庞大的深度神经网络中出现的复杂而又难以理解的运算。 为了更方便 TensorFlow 程序的理解、调试与优化,我们发布了一套叫做 TensorBoard 的可视化工具。你可以用 TensorBoard 来展现你的 TensorFlow 图像,绘制图像生成的定量指标图以及附加数据。 当 TensorBoard 设置完成后,它应该是这样子的: 数据序列
-
优化与深度学习
本节将讨论优化与深度学习的关系,以及优化在深度学习中的挑战。在一个深度学习问题中,我们通常会预先定义一个损失函数。有了损失函数以后,我们就可以使用优化算法试图将其最小化。在优化中,这样的损失函数通常被称作优化问题的目标函数(objective function)。依据惯例,优化算法通常只考虑最小化目标函数。其实,任何最大化问题都可以很容易地转化为最小化问题,只需令目标函数的相反数为新的目标函数即可
-
Q表如何根据机器学习中的强化学习来帮助确定“代理”的下一步动作?
本文向大家介绍Q表如何根据机器学习中的强化学习来帮助确定“代理”的下一步动作?,包括了Q表如何根据机器学习中的强化学习来帮助确定“代理”的下一步动作?的使用技巧和注意事项,需要的朋友参考一下 我们先前借助Q值和Q表了解了Q学习的工作原理。Q学习是一种强化学习算法,其中包含一个“代理”,它采取达到最佳解决方案所需的行动。这可以通过作为神经网络存在的Q表来实现。它有助于采取正确的步骤,使报酬最大化,从
-
XML注入强化问题
我的项目中有下面的代码 加强在上述代码中显示xml注入。如何解决这种xml注入?
-
强制BigDecimals使用科学计数法
问题内容: 我有这种方法: 例如,如果value = 1且scale = 2,则输出为“结果:0.00”。我以为会是1.00E-5。因此,我的疑问是:如果BigDecimal的大小大于某个值(在我的示例中为2),我该如何强制将BigDecimal格式化为科学计数形式? 问题答案: 您可以将搭配使用:
-
Gnome化学工具包
这是一个化学相关的图形化工具,包括一个二维的化学公式编辑器以及化学计算器等。
-
我应该使用强化学习将哪些内容保存到文件/数据库中?
我正在尝试进入机器学习领域,并决定自己尝试一些东西。我写了一个小的井字游戏。到目前为止,计算机使用随机移动与自己对弈。 现在,我想通过编写一个代理来应用强化学习,该代理将根据它对董事会当前状态的知识进行探索或利用。 我不明白的部分是这样的:代理用什么来为当前状态训练自己?假设一个RNG机器人玩家这样做: [..][..][..] […][x][o] [..][..][..] 现在代理必须决定最好的