《强化学习》专题
-
 动手学深度学习 v2
动手学深度学习 v2本书将全面介绍深度学习从模型构造到模型训练的方方面面,以及它们在计算机视觉和自然语言处理中的应用。Github 地址:https://github.com/d2l-ai/d2l-zh
-
强烈
最有力的色彩组合是充满刺激的快感和支配的 欲念,但总离不开红色;不管颜色是怎么组合,红 色绝对是少不了的。红色是最终力量来源——强烈、大胆、极端。 力量的色彩组合象征人类最激烈的感情:爱、恨、 情、仇,表现情感的充分发泄。 在广告和展示的时候,有力色彩组合是用来传 达活力、醒目等强烈的讯息,并且总能吸引众人的 目光。 补色色彩组合 原色色彩组合 单色色彩组合 55 7 52 4 68 36 4 7
-
强调
1. 使用 * * 或 _ _ 包括的文本会被转换为 <em></em> ,通常表现为斜体: 这是用来 *演示* 的 _文本_ 这是用来 演示 的 文本 2. 使用 ** ** 或 __ __ 包括的文本会被转换为 <strong></strong>,通常表现为加粗: 这是用来 **演示** 的 __文本__ 这是用来 演示 的 文本 3. 用来包括文本的 * 或 _ 内侧不能有空白,否则 *
-
强调
Markdown 使用星号(*)和底线(_)作为标记强调字词的符号,被 * 或 _ 包围的字词会被转成用 <em> 标签包围,用两个 * 或 _ 包起来的话,则会被转成 <strong>,例如: *single asterisks* _single underscores_ **double asterisks** __double underscores__ 会转成: <em>single as
-
强制JsonConvert.SerializeXmlNode将节点值序列化为Integer或Boolean
问题内容: 来自class 的函数在序列化过程中始终将XML的最后一个子节点的值作为字符串类型输出,有时您可能需要将它们序列化为Integer或Boolean。 样例代码: 输出: 所需的输出: 有没有一种方法可以强制将XML节点序列化为Integer或Boolean? 谢谢。 注意:当XML已被序列化为JSON字符串时,请避免发布解决方法,因为这些解决方法是我们愿意避免的。 问题答案: 当前的J
-
从csv文件中使用PowerCLI强化VM-HOST Set-AdvancedSetting
我希望自动配置第一台主机,以便使用PowerCLI创建主机配置文件。我在ESXI6.5中构建了第一个主机,并从该主机创建了第一个主机配置文件。但是为了创建第一个主机配置文件,我逐行编辑主机配置文件,这花了很长时间。我们有超过60个衍射集群,这意味着我将不得不创建一个主机配置文件每个集群。 我不知道该怎么设置...
-
 Vue学习笔记进阶篇之函数化组件解析
Vue学习笔记进阶篇之函数化组件解析本文向大家介绍Vue学习笔记进阶篇之函数化组件解析,包括了Vue学习笔记进阶篇之函数化组件解析的使用技巧和注意事项,需要的朋友参考一下 这两天学习了Vue.js 感觉函数化组件这个地方知识点挺多的,而且很重要,所以,今天添加一点小笔记 介绍 之前创建的锚点标题组件是比较简单,没有管理或者监听任何传递给他的状态,也没有生命周期方法。它只是一个接收参数的函数。 在这个例子中,我们标记组件为 funct
-
 机器学习和深度学习
机器学习和深度学习主要内容:机器学习,深度学习,机器学习与深度学习的区别,机器学习和深度学习的应用人工智能是近几年来最流行的趋势之一。机器学习和深度学习构成了人工智能。下面显示的维恩图解释了机器学习和深度学习的关系 - 机器学习 机器学习是让计算机按照设计和编程的算法行事的科学艺术。许多研究人员认为机器学习是实现人类AI的最佳方式。机器学习包括以下类型的模式 - 监督学习模式 无监督学习模式 深度学习 深度学习是机器学习的一个子领域,其中有关算法的灵感来自大脑的结构和功能,称为人工神经网络。
-
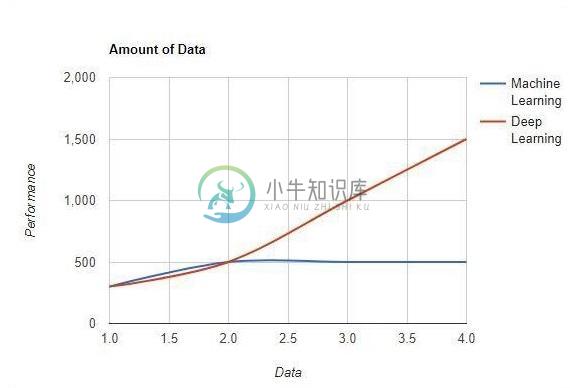
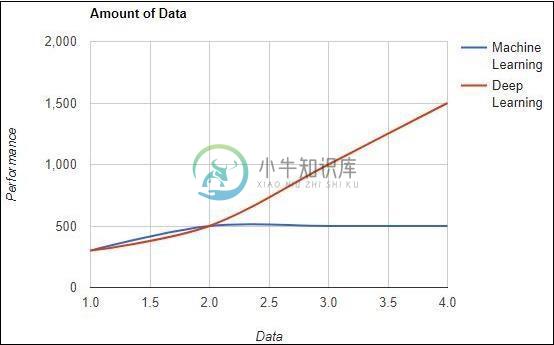 机器学习与深度学习
机器学习与深度学习主要内容:数据量,硬件依赖,特色工程在本章中,我们将讨论机器和深度学习概念之间的主要区别。 数据量 机器学习使用不同数量的数据,主要用于少量数据。另一方面,如果数据量迅速增加,深度学习可以有效地工作。下图描绘了机器学习和深度学习在数据量方面的工作 - 硬件依赖 与传统的机器学习算法相反,深度学习算法设计为在很大程度上依赖于高端机器。深度学习算法执行大量矩阵乘法运算,这需要巨大的硬件支持。 特色工程 特征工程是将领域知识放入指定特征的
-
通过化学OpenCMIS更新户外内容类型
我正试图通过OpenCMIS更新alfresco中文件的内容类型。 CMIS工作台在类型窗口中显示该类型,仅禁用开关“策略可控”。其本地名称为,queryname为,基类型为。 在groovy控制台中,我尝试了以下操作:
-
2.7. 数学优化:找到函数的最优解
数学优化 处理寻找一个函数的最小值(最大值或零)的问题。在这种情况下,这个函数被称为成本函数,或目标函数,或能量。 这里,我们感兴趣的是使用scipy.optimize来进行黑盒优化: 我们不依赖于我们优化的函数的算术表达式。注意这个表达式通常可以用于高效的、非黑盒优化。 先决条件 Numpy, Scipy matplotlib 也可以看一下: 参考 数学优化是非常 ... 数学的。如果你需要性能
-
Uboot 学习
api: 存放uboot提供的接口函数 arch: 存放跟芯片相关的文件 board: 开发板配置文件 common: uboot命令行下支持的命令 disk: 磁盘支持 doc: 文件目录 drivers:设备驱动程序 examples例程 fs: 支持的文件系统,cramfs fat fdos jffs2 registerfs inc
-
Makefile 学习
CROSS_COMPILE=/opt/4.5.1/bin/arm-linux- CC=$(CROSS_COMPILE)gcc AS=$(CROSS_COMPILE)as LD=$(CROSS_COMPILE)ld CFLAGS=-g -Wall LIBS=-lpthread all:main main:main.o gsm_gprs.o socket.o telosb
-
哪些机器学习算法不需要做归一化处理?
本文向大家介绍哪些机器学习算法不需要做归一化处理?相关面试题,主要包含被问及哪些机器学习算法不需要做归一化处理?时的应答技巧和注意事项,需要的朋友参考一下 概率模型不需要归一化,因为他们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、RF。而像Adaboost、GBDT、SVM、LR、KNN、KMeans之类的最优化问题就需要归一化
-
在机器学习中,为何要经常对数据归一化?
本文向大家介绍在机器学习中,为何要经常对数据归一化?相关面试题,主要包含被问及在机器学习中,为何要经常对数据归一化?时的应答技巧和注意事项,需要的朋友参考一下 归一化可以: 归一化后加快了梯度下降求最优解的速度(两个特征量纲不同,差距较大时,等高线较尖,根据梯度下降可能走之字形,而归一化后比较圆走直线) 归一化有可能提高精度 (一些分类器需要计算样本之间的距离,如果一个特征值域范围非常大,那么距离