《算法引流:》专题
-
什么是K-means聚类算法
主要内容:聚类和分类的区别,找相似,簇是什么,理解K的含义,如何量化“相似”,总结机器学习算法主要分为两大类:有监督学习和无监督学习,它们在算法思想上存在本质的区别。 有监督学习,主要对有标签的数据集(即有“参考答案”)去构建机器学习模型,但在实际的生产环境中,其实大量数据是处于没有被标注的状态,这时因为“贴标签”的工作需要耗费大量的人力,如果数据量巨大,或者调研难度大的话,生产出一份有标签的数据集是非常困难的。再者就算是使用人工来标注,标注的速度也会比数据生产的速度慢的多。因
-
 决策树算法if-else原理
决策树算法if-else原理主要内容:if-else原理,决策树算法关键在本节我们将介绍“机器学习”中的“明星”算法“决策树算法”。决策树算法在“决策”领域有着广泛的应用,比如个人决策、公司管理决策等。其实更准确的来讲,决策树算法算是一类算法,这类算法逻辑模型以“树形结构”呈现,因此它比较容易理解,并不是很复杂,我们可以清楚的掌握分类过程中的每一个细节。 if-else原理 想要认识“决策树算法”我们不妨从最简单的“if - else原理”出发来一探究竟。作为程序员,
-
朴素贝叶斯算法应用
主要内容:简单应用案例,sklearn实现朴素贝叶斯通过两节知识的学习,相信你对朴素贝叶斯算法有了初步的掌握,本节将实际应用朴素贝叶斯算法,从实战中体会算法的精妙之处。 首先看下面一个简单应用案例: 简单应用案例 假设一个学校有 45% 的男生和 55% 的女生,学校规定不能穿奇装异服,男生的裤子只能穿长筒裤,而女生可以穿裙子或者长筒裤,已知该学校穿长筒裤的女生和穿裙子的女生数量相等,所有男生都必须穿长筒裤,请问如果你从远处看到一个穿裤子的学生,那
-
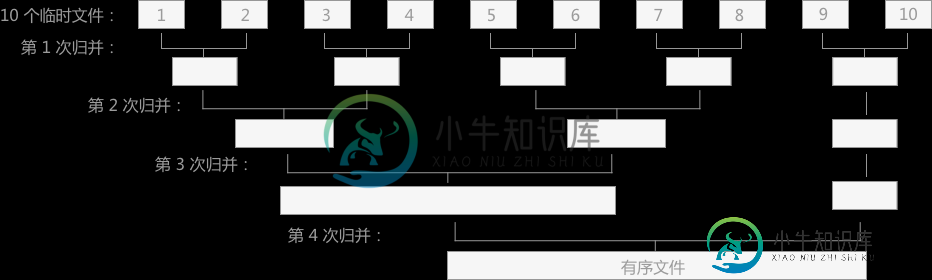 什么是外部排序算法
什么是外部排序算法上一章介绍了很多排序算法, 插入排序、选择排序、 归并排序等等,这些算法都属于 内部排序算法,即排序的整个过程只是在内存中完成。而当待排序的文件比内存的可使用容量还大时,文件无法一次性放到内存中进行排序,需要借助于外部存储器(例如硬盘、U盘、光盘),这时就需要用到本章介绍的 外部排序算法来解决。 外部排序算法由两个阶段构成: 按照内存大小,将大文件分成若干长度为 l 的子文件(l 应小于内存的可使
-
无限递归调用minimax算法
我最近实现了一个4X4井字游戏的代码,这是使用极大极小算法。然而,我的极大极小函数无限次地递归调用自己。 初始板 (4X4) 井字 - 轮到电脑的代码- 在上面的代码中是船上的空位置,返回“X”(如果玩家X获胜),返回“O”(如果玩家O获胜) checkGameOver函数-
-
Java MySQL结果集算法[重复]
我正在使用以下代码在ArrayList中保存彼此喜欢的匹配人员的id。 我的数据库是finder。喜欢和它的小报: 我的问题是,正如我所说的,我想在ArrayList中保存匹配的人。例如,用户15和17喜欢11,用户11也喜欢15和17,所以当用户11登录到程序中时,我想显示这个用户15和17是您的匹配。我试图设置算法,但我得到了“结果集关闭后不允许操作”。我的错误在哪里? 功能是
-
你了解vue的diff算法吗?
本文向大家介绍你了解vue的diff算法吗?相关面试题,主要包含被问及你了解vue的diff算法吗?时的应答技巧和注意事项,需要的朋友参考一下 说实话没有阅读过源码 大概说一下自己的猜测: 如一个list中某一个数据发生变更时, vue中会对整个list进行遍历, 判断使用到的某些属性是否发生变更, 从而更新发生变更的item 所以key属性才会显得很重要, 它会告诉你, 我那个item发生变更,
-
 思特威算法测试面经
思特威算法测试面经一面: 聊项目,大概有10分钟 聊实习,大概有10多分钟 讲下知道的图像处理算法 黑盒白盒测试 场景题:怎样设计一个去噪算法的测试 场景题:发现一个算法的问题,怎样处理 追问,如果开发不承认问题怎么办,回答之后面试官解释说这是经常发生的情况,然后俩人都笑了 两个python八股:浅拷贝深拷贝、单引号双引号和三引号的区别(这个不会呜呜) 反问 全程45分钟左右,希望有二面捏,许愿二面 更新二面: 聊
-
1.6.为什么要学习算法
计算机科学家经常通过经验学习。我们通过看别人解决问题和自己解决问题来学习。接触不同的问题解决技术,看不同的算法设计有助于我们承担下一个具有挑战性的问题。通过思考许多不同的算法,我们可以开始开发模式识别,以便下一次出现类似的问题时,我们能够更好地解决它。 算法通常彼此完全不同。考虑前面看到的 sqrt 的例子。完全可能的是,存在许多不同的方式来实现细节以计算平方根函数。一种算法可以使用比另一种更少的
-
图算法实现 - 三角计数
import scala.reflect.ClassTag import org.apache.spark.graphx._ /** * Compute the number of triangles passing through each vertex. * * The algorithm is relatively straightforward and can be computed
-
图算法实现 - 连通组件
import scala.reflect.ClassTag import org.apache.spark.graphx._ /** Connected components algorithm. */ object ConnectedComponents { /** * Compute the connected component membership of each vertex
-
 java实现折半排序算法
java实现折半排序算法本文向大家介绍java实现折半排序算法,包括了java实现折半排序算法的使用技巧和注意事项,需要的朋友参考一下 折半插入排序(binary insertion sort)是对插入排序算法的一种改进,由于排序算法过程中,就是不断的依次将元素插入前面已排好序的序列中。由于前半部分为已排好序的数列,这样我们不用按顺序依次寻找插入点,可以采用折半查找的方法来加快寻找插入点的速度。 折半排序算法示意图: 以
-
 java实现快速排序算法
java实现快速排序算法本文向大家介绍java实现快速排序算法,包括了java实现快速排序算法的使用技巧和注意事项,需要的朋友参考一下 1、算法概念。 快速排序(Quicksort)是对冒泡排序的一种改进。由C. A. R. Hoare在1962年提出。 2、算法思想。 通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序
-
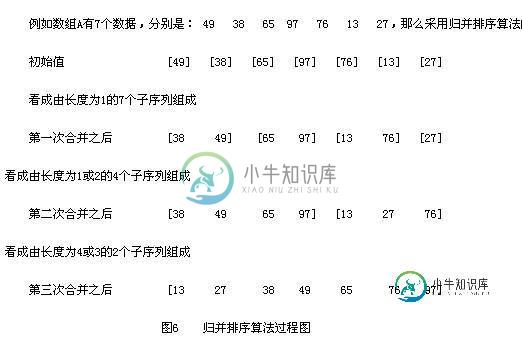 java实现归并排序算法
java实现归并排序算法本文向大家介绍java实现归并排序算法,包括了java实现归并排序算法的使用技巧和注意事项,需要的朋友参考一下 归并排序算法思想: 分而治之(divide - conquer);每个递归过程涉及三个步骤 第一, 分解: 把待排序的 n 个元素的序列分解成两个子序列, 每个子序列包括 n/2 个元素. 第二, 治理: 对每个子序列分别调用归并排序MergeSort, 进行递归操作 第三, 合并: 合
-
 java实现希尔排序算法
java实现希尔排序算法本文向大家介绍java实现希尔排序算法,包括了java实现希尔排序算法的使用技巧和注意事项,需要的朋友参考一下 希尔排序算法的基本思想是:先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在