《算法引流:》专题
-
LRU 算法
一、前言 上一章《Memcached源码分析 - Memcached源码分析之增删改查操作(5) 》中,我们讲到了SET命令的操作。当客户端向Memcached服务端SET一条缓存数据的时候,会将生成的Item地址挂到LRU的链表结构上。这一章节,我们主要讲一下Memcached是如何使用LRU算法的。 LRU:是Least Recently Used 近期最少使用算法。 二、Memcached的
-
1.-算法
名称 原理 复杂度 插入排序 对于元素索引i(i>=1),从头开始,若能找到比 a[i] 大对元素 a[j],则记录 a[i] 的值,将索引 j~i-1 的元素向后移动一位,使用 a[i] 替换 a[j]。优化思路:针对数组可以采用二分查找找到当前元素的插入位置,链表不需要位移操作。 O(n^2/2) 选择排序 从当前元素开始遍历,记录最小值的索引,根据索引交换当前值的最小值,选择排序每次选出最小
-
私钥算法与最终实体证书中的公钥算法不匹配(在索引0处)
我试图将私钥和it证书链存储在密钥库中,我得到以下错误:私钥算法与最终实体证书中的公钥算法不匹配(在索引0处) 这就是我生成密钥对的方式: 这是我用来生成X509证书的方法: 用于存储密钥对的代码是: 生成的错误为:
-
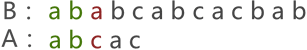 BF算法(串模式匹配算法)
BF算法(串模式匹配算法)主要内容:BF算法原理,BF算法实现,BF算法时间复杂度,总结串的模式匹配算法,通俗地理解,是一种用来判断两个串之间是否具有"主串与子串"关系的算法。 主串与子串:如果串 A(如 "shujujiegou")中包含有串 B(如 "ju"),则称串 A 为主串,串 B 为子串。主串与子串之间的关系可简单理解为一个串 "包含" 另一个串的关系。 实现串的模式匹配的算法主要有以下两种: 普通的模式匹配算法; 快速模式匹配算法; 本节,先来学习 普通模式匹配(BF)
-
算法题 - 一致性哈希算法
一致性哈希算法 tencent2012笔试题附加题 问题描述: 例如手机朋友网有n个服务器,为了方便用户的访问会在服务器上缓存数据,因此用户每次访问的时候最好能保持同一台服务器。 已有的做法是根据ServerIPIndex[QQNUM%n]得到请求的服务器,这种方法很方便将用户分到不同的服务器上去。但是如果一台服务器死掉了,那么n就变为了n-1,那么ServerIPIndex[QQNUM%n]与S
-
数据结构与算法 - KMP算法
KMP算法解决的问题是字符匹配,这个算法把字符匹配的时间复杂度缩小到O(m+n),而空间复杂度也只有O(m),n是target的长度,m是pattern的长度。 部分匹配表(Next数组):表的作用是 让算法无需多次匹配S中的任何字符。能够实现线性时间搜索的关键是 在不错过任何潜在匹配的情况下,我们”预搜索”这个模式串本身并将其译成一个包含所有可能失配的位置对应可以绕过最多无效字符的列表。 Nex
-
k-means算法流程
本文向大家介绍k-means算法流程相关面试题,主要包含被问及k-means算法流程时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 从数据集中随机选择k个聚类样本作为初始的聚类中心,然后计算数据集中每个样本到这k个聚类中心的距离,并将此样本分到距离最小的聚类中心所对应的类中。将所有样本归类后,对于每个类别重新计算每个类别的聚类中心即每个类中所有样本的质心,重复以上操作直到聚类中心不变为止。
-
数据结构与算法 - 递归算法
从前有座山 山里有座庙 庙里有个老和尚和小和尚 老和尚对小和尚说: 从前有座山 返回1 从前有座山,山里有个庙,庙里有个和尚讲故事……这是一个古老的童谣,每个人都知道下面一句说了什么,但还要不厌其烦的说下去。犹如我们的人性,陷入一种循环,不可逃脱,无法自拔。 所以在我们现实生活中,很多时候也有所谓的重复性,而这种重复性用计算机解决的话,就能够省很多事情。 如果用一部电影来类比的话,那《盗梦空间》就
-
数据结构与算法 - 排序算法
常见排序算法 稳定排序: 冒泡排序 — O(n²) 插入排序 — O(n²) 桶排序 — O(n); 需要 O(k) 额外空间 归并排序 — O(nlogn); 需要 O(n) 额外空间 二叉排序树排序 — O(n log n) 期望时间; O(n²)最坏时间; 需要 O(n) 额外空间 基数排序 — O(n·k); 需要 O(n) 额外空间 不稳定排序 选择排序 — O(n²) 希尔排序 — O
-
数据结构与算法 - 查找算法
ASL 由于查找算法的主要运算是关键字的比较,所以通常把查找过程中对关键字的平均比较次数(平均查找长度)作为衡量一个查找算法效率的标准。ASL= ∑(n,i=1) Pi*Ci,其中n为元素个数,Pi是查找第i个元素的概率,一般为Pi=1/n,Ci是找到第i个元素所需比较的次数。 顺序查找 原理是让关键字与队列中的数从最后一个开始逐个比较,直到找出与给定关键字相同的数为止,它的缺点是效率低下。时间复
-
K-Means 聚类算法 kmeans 聚类算法
算法介绍 K-Means又名为K均值算法,他是一个聚类算法,这里的K就是聚簇中心的个数,代表数据中存在多少数据簇。K-Means在聚类算法中算是非常简单的一个算法了。有点类似于KNN算法,都用到了距离矢量度量,用欧式距离作为小分类的标准。 算法步骤 (1)、设定数字k,从n个初始数据中随机的设置k个点为聚类中心点。 (2)、针对n个点的每个数据点,遍历计算到k个聚类中心点的距离,最后按照离哪个中心
-
SVM 支持向量机算法 Svm 算法
参考资料:http://www.cppblog.com/sunrise/archive/2012/08/06/186474.html http://blog.csdn.net/sunanger_wang/article/details/7887218 我的数据挖掘算法代码:https://github.com/linyiqun/DataMiningAlg
-
纯函数语言如何处理基于索引的算法?
我一直在努力学习函数式编程,但我仍然难以像函数式程序员那样思考。其中一个问题是如何实现索引密集型操作,这些操作强烈依赖于循环/执行顺序。 例如,考虑下面的java代码 这里,在prefixList函数中,nums列表首先被克隆,但随后对其执行迭代操作,其中索引i上的值依赖于索引i-1(即需要执行顺序)。然后返回这个值。 这在函数式语言(Haskell、Lisp等)中是什么样子的?我一直在学习单子,
-
利用汉明距离算法建立模糊连接索引
我是新来的Java和地图减少,我试图写一个地图减少程序,读取程序中称为“字典”的列表单词,并使用汉明距离算法生成列表中距离为1的所有单词。我能够生成输出,但问题是它似乎非常低效,因为我需要将整个列表加载到ArrayList中,并且对于每个单词,我在Map方法中调用汉明距,所以我阅读整个列表两次,并运行汉明距离算法n*n次,其中n是列表中的字数。 请给我一些有效的方法。 这是代码。到目前为止,它还没
-
算法题 - 倒排索引关键词不重复Hash编码
作者:July、yansha。编程艺术室出品。 出处:结构之法算法之道 本章要介绍这样一个问题,对倒排索引中的关键词进行编码。那么,这个问题将分为两个个步骤: 首先,要提取倒排索引内词典文件中的关键词; 对提取出来的关键词进行编码。本章采取hash编码的方式。既然要用hash编码,那么最重要的就是要解决hash冲突的问题,下文会详细介绍。 有一点必须提醒读者的是,倒排索引包含词典和倒排记录表两个部