《吉利》专题
-
利用移动设备的触摸输入实现虚拟物体的交互--增强现实
null null
-
如何在Android中利用Reverfit 2实现应用程序逻辑与网络层的分离
在Android系统中使用Reverfit2的模式是什么? 事先谢谢你
-
java带供款的复利公式
我目前正在尝试开发一个复利计算器,其中包括每月供款。我已经成功地使用以下代码在没有每月供款的情况下计算复利,但无法计算出添加每月供款时的公式。 当试图通过贡献获得计算值时,我改变了这样做的方式。请参阅下面的代码,了解我是如何实现这一点的。 我想这应该符合我的要求。每月将本金增加供款金额,如果该月等于应加利息的月份,则计算利息*利率,并将其加至本金。 当使用上面的值时,我期望得到355242.18美
-
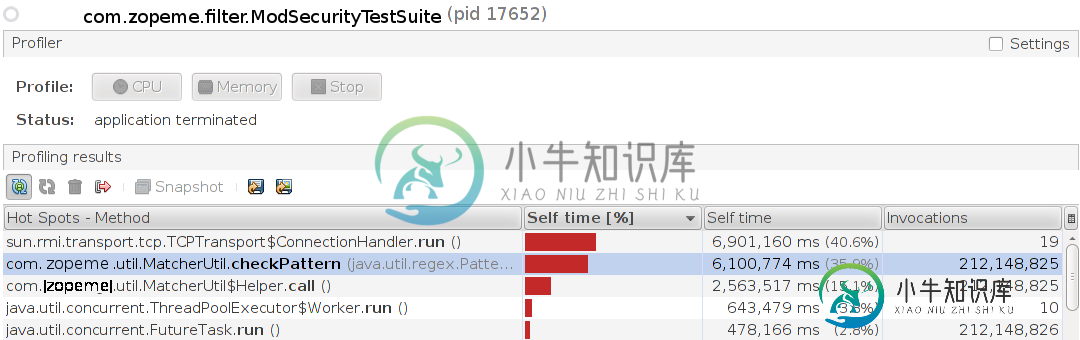 Java:Matcher.find使用高cpu利用率
Java:Matcher.find使用高cpu利用率我正在使用mod安全规则https://github.com/SpiderLabs/owasp-modsecurity-crs清理用户输入数据。在将用户输入与mod security rule正则表达式匹配时,我面临着cpu激增和延迟。总的来说,它包含500个正则表达式来检查不同类型的攻击(xss、badrobots、generic和sql)。对于每个请求,我检查所有参数并对照所有这500个正则表
-
java应用程序中的高CPU利用率-为什么?
我有一个Java应用程序(基于web),它有时会在几个小时内显示非常高的CPU利用率(几乎90%)。Linux的TOP命令显示了这一点。重新启动应用程序时,问题就会消失。 所以要调查: 我使用线程转储来查找线程正在执行的操作。有几个线程处于“可运行”状态,一些线程处于其他一些状态。在重复执行线程转储时,我确实看到一些线程总是处于“可运行”状态。因此,他们似乎是罪魁祸首。 但我无法确定,哪个线程占用
-
安德利德警察不尽职
> 新的- 包装test.density.yeah; main.xml代码: 已使用以下设置启动emulator: 决议-480x800 平均LCD密度-190 结果: http://cs5961.userapi.com/u68152416/-3/y_ef134df2.jpg 之后,我使用以下设置启动emulator: 决议-480x800 AVSTRATED LCD密度-240 结果: http
-
如何利用Spring的RestController将JSON反序列化为模型对象
我正在使用Betfair的API开发一个REST web应用程序,因此我需要序列化/反序列化JSON,以便发送HttpRequest并读取HttpResponse。 POM依赖项 我错在哪?
-
程序在多线程中不能顺利结束
我正在我的程序中创建一些线程。这里我使用了join方法,这样主线程就会等待我的所有线程。但是每当我运行这个程序的时候,它并没有完成,所有的信息消息都被打印出来,但是程序仍然没有顺利结束。有没有人能帮我解决这个问题呢? 下面是我的代码: 下面是DeployerThread的代码: 下面是线程转储: “CompilerThread0”后台进程Prio=3 TID=0x002E4310 NID=0x20
-
如何利用Spring-Cloud-Stream实现自定义kafka分区
我试图使用spring cloud stream绑定实现一个自定义的Kafka分区器。我只想对用户主题进行自定义分区,而不对公司主题进行任何操作(在本例中,Kafka将使用DefaultPartitioner)。 我的绑定配置: 我使用以下方式将消息发送到流中: 我的UserPartitioner类: 我最终收到以下异常: 编辑:根据文档,还尝试了以下步骤: User-Out:Destinatio
-
如何利用AWS SageMaker上训练的模型,利用内置的语义分割算法在本地PC机上进行推理?
类似的问题是,经过培训的模型可以部署在其他平台上,而无需依赖sagemaker或aws服务?。 我使用内置的语义分割算法在AWS SageMaker上训练了一个模型。该训练模型被命名为存储在S3上。所以我想从S3下载这个文件,然后用它在本地PC上进行推断,而不再使用AWS SageMaker。由于内置的算法语义分割是使用MXNet Gluon框架和Gluon CV工具包构建的,因此我尝试参考MXN
-
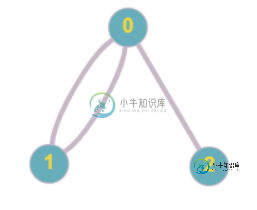 如何在无向图中利用BFS进行循环检测中处理两个顶点之间的平行边?
如何在无向图中利用BFS进行循环检测中处理两个顶点之间的平行边?我是编程和学习算法的新手,当我读到BFS可以用于周期检测时,我正在研究BFS。我试图在一个具有邻接表表示的无向图G上实现同样的方法。我所做的如下: •使用队列执行简单的BFS遍历,同时维护队列中排队节点的父节点。 •如果我遇到一个节点,它有一个邻居,这样已经被访问,但是不是的父节点,那么这意味着图中存在循环。 上面的方法是有效的,除非在两个顶点之间有超过1条边,例如,在下面的例子中,我们在顶点之间
-
利用python中的乘积和平均值公式创建损失率表
我正在尝试从Python中已经有的流率数据帧创建损失率表(见下文)。如果有人能帮我编写代码,我将不胜感激。我在下面复制了excel公式,但如果您需要更多信息,请让我知道。 最后,第13行公式中的平均值是计算损失率后列的简单平均值。即B13中的公式为 提前感谢您的帮助!
-
如何利用Spring Boot和Spring Data Jpa从数据库中获取用户进行登录
我想用我自己的数据库中的数据制作登录表单。我创建了实体用户类: UPD:解决了!我不知道为什么和怎么做。我发现hibernate创建了新表“auth_data”,但没有使用我的表“auth_data”。因此,我将“auth_data”重命名为“auth_data”,现在开始工作了!我还在@data上更改了@getter@setter,在用户存储库中更改了“User findByUsername(S
-
帕斯利。js覆盖默认验证消息
这里有人知道如何在安装过程中覆盖验证消息吗。 我希望能够在安装期间$('form')。parsley()更改/定义验证消息,例如: data parsley required message=“一些相关的自定义消息” 我希望将该字段分配给所有验证,因此如果该字段设置为必需,它将显示自定义消息作为默认值。 提前感谢8-)
-
执行器核心数和利益或其他-火花
需要进行一些运行时澄清。 在我读到的其他地方的一个线程中,有人说Spark Executor应该只分配一个核心。然而,我想知道这是否真的永远是真的。阅读各种so问题和诸如此类的问题,以及Karau、Wendell等人的著作,可以清楚地看到,有相同或相反的专家指出,在某些情况下,每个执行者应该指定更多的内核,但讨论往往更多的是技术性的,而不是功能性的。也就是说,缺少功能性的例子。 > 我的理解是RD