《吉利》专题
-
如何利用导航属性?
OData服务(V2)包含以下多个导航属性: 如上所示,和是导航属性 请求OData服务的代码: 如何通过代码从导航属性中获取URL?我可以通过以下对象获取它: 但我不知道这是不是正确的方式。
-
面试问题:买卖股票以实现利润最大化,但有一次卖出就不买的限制
有一个经典的面试问题,即利润最大化,允许一次交易、n次交易和k次交易购买股票。 有人问我一个类似的问题,但有一个扭曲的限制:你可以购买一只股票任意次数(任何一天不超过一个单位),但你不能在卖出股票后购买。 这有一个引理,你只卖一次。 例:70409011080100 选项1:B卖出=130 选项2:B X B卖出=120 老问题 https://www.geeksforgeeks.org/stoc
-
如何利用spring依赖注入模拟包util类静态方法
我有一个包使用spring依赖注入进行单元测试,使用下面的代码。 我需要在util类中添加一个静态方法,并需要对其进行模拟,以防止现有的单元测试失败。我尝试使用PowerMock,但得到了不同的错误,如下面的错误。
-
穆兴与利巴夫
我有一个程序,它应该demux输入mpeg-ts,将mpeg2转码为h264,然后在转码视频旁边混音。当我用VLC打开结果的混音文件时,我既没有得到音频也没有得到视频。这是相关代码。 我的主要工作循环如下: 初始化libav输出上下文的代码如下: 最后这是编写音频的代码: 可以从这里获得生成的mpeg4文件: 我推荐了write_video_frame code,因为它要复杂得多,而且我在做音频的
-
如何使用jstat或其他基于命令行的工具获得当前/最大jvm堆利用率(单值)?
JConsole或J VisualVM显示最大堆大小和当前堆利用率。如何在应用程序的生命周期内使用基于命令行的工具(例如jstat)获取相同的值? 从我用jstat-gc收集的度量(S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT),我如何计算JConsole/Visual VM给出的(单值)堆利用率?
-
意大利语命名实体识别
我想使用NLP工具从意大利文本中提取名称和数字。 遗憾的是,斯坦福德NLP和Apache OpenNLP都没有为意大利人提供模型。 我能找到一个,或者找到训练数据来制造一个吗?(至少15000句)
-
如何利用瘦客户机在集群节点中不放置jar自动部署计算任务
我们升级到了ignite2.10.0最新版本。并尝试使用瘦客户端配置启动计算任务。
-
Apache Ignite 2. x-我可以利用离堆存储并且仍然具有基于时间的驱逐(从
我正在使用Apache Ignite 2.8.1 我有一个特定的缓存,需要存储在堆外(否则我将面临内存不足的问题)。我还需要分发缓存。 但我还需要一个基于时间的逐出策略来逐出开/关内存缓存中的条目。 Apache Ignite 2是否可能做到这一点。十、 请参见此处的代码片段。我尝试过以各种方式对此进行配置,但除了手动执行之外,没有任何操作会将这些条目从缓存中逐出。 当我运行下面的测试方法时,所有
-
Java9中便利工厂方法返回的特定集合类型
在Java9中,我们有方便的工厂方法来创建和实例化不可变的List、Set和map。
-
Tornado/Async Web服务器理论,如何处理较长时间运行的操作以利用异步服务器
我刚刚开始研究龙卷风和异步Web服务器。在许多龙卷风的例子中,较长的请求由以下内容处理: 致电tornado Web服务器 tornado对api进行异步web调用 让tornado在回调等待调用时继续接收请求 在回调中处理响应。服务器对用户 因此,假设用户在向tornado服务器发出请求将向内部api或w/e。获取请求时,api请求可能需要一秒钟的时间才能运行,然后当它最终返回tornado服务
-
如何利用.yml避免zuul中的超时异常
我有没有eureka服务发现的zuul网关服务器。 我使用如下所示的yml文件连接微服务和zuul。
-
从2015年开始,有没有一种方法可以使用谷歌地图应用编程接口来获取意大利邮政编码的边界?
我看了很多关于类似主题的问题: 谷歌地图API V3:如何获取区域边界坐标(多段线)数据? 谷歌已经开始用粉色突出搜索区域。谷歌地图API 3中是否提供此功能? 在谷歌地图结果中添加"搜索区域"轮廓 谷歌和推特从哪里获得城市、地区和州的政治边界? 在我的国家和地区搜索在线工具和工具: https://market.mashape.com/vanitysoft/boundaries-io/overv
-
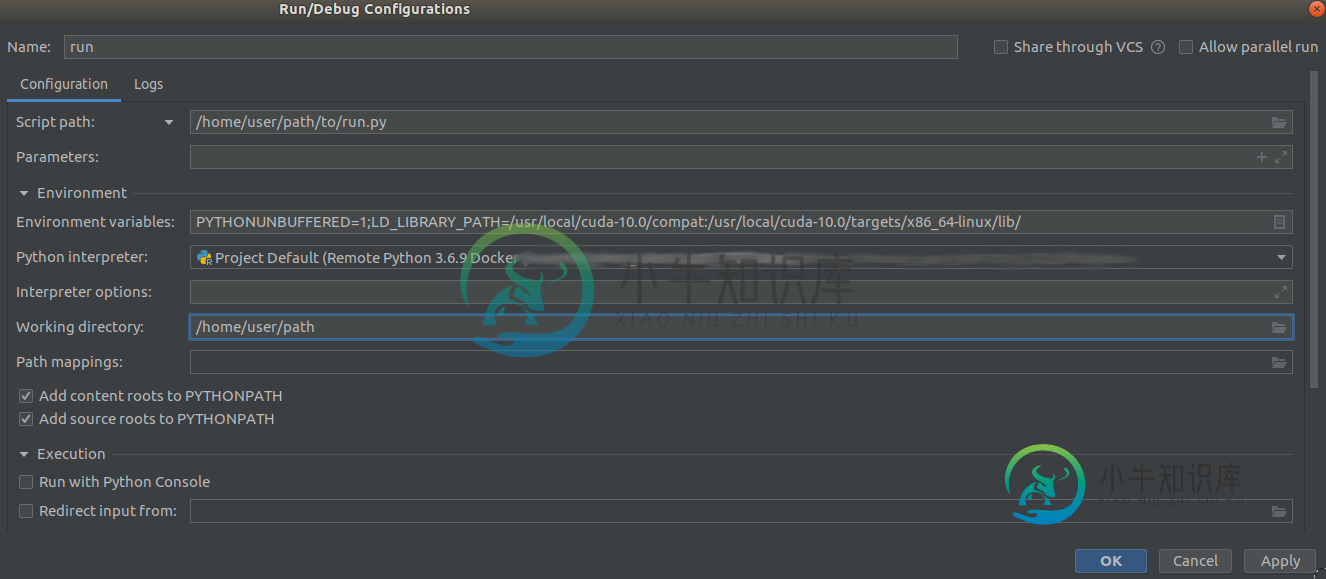 利用docker和GPU进行Pycharm调试
利用docker和GPU进行Pycharm调试在PyCharm中调试一个Python应用程序,其中我使用Tensorflow将解释器设置为自定义docker映像,因此需要GPU。问题是,据我所知,Pycharm的命令构建没有提供一种发现可用GPU的方法。 使用以下命令输入容器,指定要使哪些GPU可用(): 在容器内,我可以运行查看是否找到GPU,并确认Tensorflow找到了它,使用: 如果我不使用标志,就不会发现GPU,这是预期的。注意:
-
利用中心极限定理生成的高斯分布参数
在我正在研究的一个软件(传感器模拟)中,我需要为模拟的传感器信号生成正态分布的噪声。我用了中心极限定理。我生成了20个随机数,并建立了一个平均值来逼近高斯分布。 所以我取“测量”信号,从到生成20个数字,并对它们进行平均。我把结果加到信号上就有噪声了。 现在,对于我的大学,我不得不用它的均值和方差来描述这个高斯分布。好的,mean将是0,但我完全不知道如何将程序中的noiseMax转换为方差。谷歌
-
如何利用Jersey计算多部分请求体MD5哈希
我没有找到获取原始请求体的方法,我需要计算MD5散列。调用资源方法时,()的输入流已经被使用,我无法再次读取它。 我尝试将方法签名更改为: 通过这种方式,我可以获得请求主体的原始字节,并且可以成功地计算MD5散列,但我不知道如何处理多部分请求(拆分部分,获取每个部分,等等)。我必须亲自处理原始请求吗?或者我可以让Jersey做这个肮脏的工作,为我提取S并让我以某种方式计算MD5哈希吗? 谢谢,