《影石Insta360》专题
-
Firebase存储安全规则桶通配符会影响项目中的其他GCS桶吗?
假设您可以在Firebase存储安全规则中提供bucket通配符,例如: 这里声明的规则是否可能覆盖来自同一Google Cloud项目的GCS bucket的规则(如公共读取)?具体地说,在Firebase Storage browser中创建的规则是否会影响同一项目中的其他(即非Firebase)GCS桶? 一个例子: Firebase存储的规则会导致无意中获得公共读取权限吗?
-
 列表视图与微调内:列表视图的第一项影响其最后一项
列表视图与微调内:列表视图的第一项影响其最后一项我有一个奇怪的场景,每次我从的第一项中的微调器中选择一个值,最后一个项的微调器值与第一项相同。只有当ListView项目总数为5个及以上时,才会发生这种情况。我注释掉了代码,只保留了声明,但它仍在发生。这是Android系统的漏洞吗? 澄清: > 我的ListView的为空 我的微调器的被注释掉。 Android SDK工具版本为22.6.2 Android SDK平台工具是19.0.1 以下是适
-
ART 下的方法内联策略及其对 Android 热修复方案的影响分析
ART下的方法内联策略及其对Android热修复方案的影响分析 tomystang 为了解决ART模式下的占用Rom空间问题,Tinker曾经花了一个半月时间实现分平台合成。Android N后对内联的新发现,似乎再一次认证了"热补丁不是请客吃饭"这句话。 研究或填坑的路可能永远不会停,但Tinker团队有决心与信心可以陪大家一起走下去。 0x00 背景 ART(Android Runtime
-
javascript - 如何让子元素的click事件不会影响到父元素的dbclick事件?
子元素有click事件,父元素有dbclick事件,想要做到快速双击子元素的时候,不要触发父元素的dbclick事件 尝试了给子元素添加阻止冒泡、return false等操作,均无效
-
求助,急,关于python的类属性__slots__,为什么修改类属性影响实例?
我有以上代码,为什么修改类属性影响实例属性?有人会说这是由于实例共享类属性,根据mro属性解析顺序是如此,但是这是在实例命名空间没有要搜索的属性时才会访问类的命名空间,在我的代码中,实例(shili)有自己的name属性,但为什么还是共享类属性呢?或者说这是其他什么问题,求大佬解答
-
javascript - browser-image-compression会对图片质量有影响吗?有tinypng的图片压缩库吗?
browser-image-compression 浏览器端需要压缩图片,用browser-image-compression,发现图片质量下降,请问这个库会损坏图片质量吗? 类似tinypng的库有吗
-
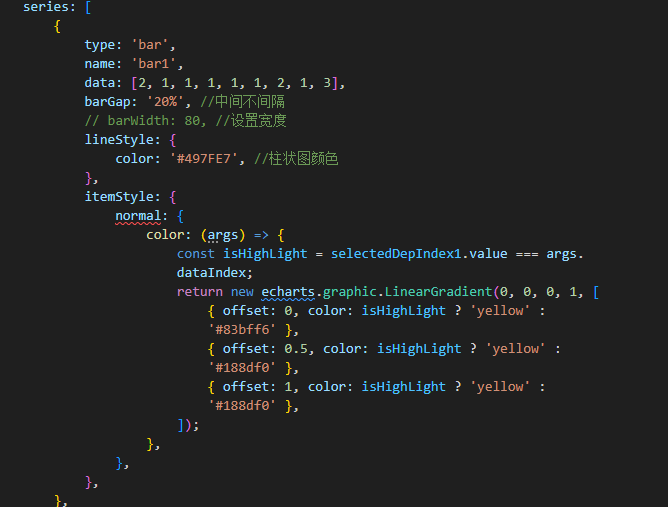 vue.js - echarts点击柱状图给当前柱子高亮并且添加阴影怎么做?
vue.js - echarts点击柱状图给当前柱子高亮并且添加阴影怎么做?现在只能做到点击高亮,但同时添加阴影不知道怎么做,我想和color属性一样用个函数,但是里面的shadow属性好像不支持函数
-
如何在Microsoft SQL Server 2008中运行查询之前知道多少行会受到影响
问题内容: 我已经阅读了一些有关ROWCOUNT的信息,但它并不是我想要的。根据我的理解,行计数指出了运行查询后受影响的行数。我正在寻找的是在运行查询之前知道的。这可能吗? 问题答案: 简短的答案是没有。 在SQL Server中执行查询..atleast之前,您无法获得行数。 最好的方法是使用 然后执行您的实际查询
-
Mongodb。方法来限制仅具有“投影”(即筛选器)的给定字段的子文档?
因为在MongoDB中没有办法过滤子文档(参考:如何使用MongoDB选择子文档) MongoDB中是否有其他方法/方法可以快速删除/过滤没有给定字段、没有下例中的字段的字段? 是唯一的方法来做到这一点,通过处理mongoDB外部的结果,并过滤掉所有空文档? (想象一个情况,当你有一千个具有不同模式的subdocs。我做了一个. search(),得到了1000个子文档,但是900是空的。我只是想
-
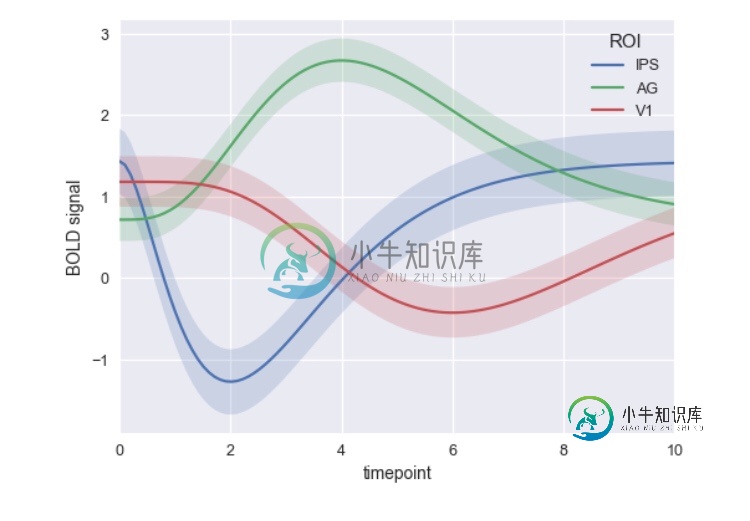 情节:如何制作多条线和阴影区域的图形以显示标准偏差?
情节:如何制作多条线和阴影区域的图形以显示标准偏差?问题内容: 如何使用Plotly生成带有阴影标准偏差的折线图?我正在尝试实现类似于seaborn.tsplot的功能。任何帮助表示赞赏。 问题答案: 对于pandas数据框中的列数,以下方法完全灵活,并使用plotly的默认颜色周期。如果行数超过颜色数,将从一开始就重新使用颜色。截至目前,您可以使用以下任何十六进制颜色序列替换: 完整的代码:
-
查找使用Yash Chopra制作的电影多于其他任何导演的所有演员
问题内容: 塞赫玛 我没有得到正确的输出。 我的行数为零。有人可以修改上面的查询并给我正确的输出,但我尝试了各种查询,但没有得到任何结果 问题答案: 您可以检查以下SQL。 说明-第一个内联视图返回带有“ Yash Chopra”的电影计数的人员列表。第二个内联视图返回与其他导演一起观看电影的人的列表。最后,我筛选了“ Yash Chopra”的电影数量大于“其他导演”的那些人的列表。
-
 解决Python中导入自己写的类,被划红线,但不影响执行的问题
解决Python中导入自己写的类,被划红线,但不影响执行的问题本文向大家介绍解决Python中导入自己写的类,被划红线,但不影响执行的问题,包括了解决Python中导入自己写的类,被划红线,但不影响执行的问题的使用技巧和注意事项,需要的朋友参考一下 1. 错误描述 之前在学习Python的过程中,导入自己写的包文件时,与之相关的方法等都会被划红线,但并不影响代码执行,如图: 看着红线确实有点强迫症,并且在这个过程当时,当使用该文件里的方法时不会自动提示方法名
-
 如何在android中为线性布局创建如下所示的阴影效果?[已关闭]
如何在android中为线性布局创建如下所示的阴影效果?[已关闭]想改进这个问题吗 通过编辑此帖子,更新问题,使其只关注一个问题。 我想知道是否可以在android中为线性布局创建阴影效果,如下所示。任何帮助都将不胜感激...
-
Spring数据JPA-如何使用投影和/或命名查询返回嵌套映射的id?
我有这些实体-项目 和- 我需要运行此sql查询: 我在ItemRepository中使用了这个[1],但性能不好。它正在检索项目和类别中的所有字段(包括我不需要的与类别的联接)。 [1] 我正在尝试使用命名查询和投影来提高性能,但我似乎一事无成。我一直遇到-<代码>验证失败,无法查询方法公共抽象java。util。列出findByItemSet(长)。我尝试创建一个DTO类和一个接口来做同样的事
-
在Elasticsearch中投影与正则表达式匹配的文档中所有字段的总和
问题内容: 在Elasticsearch中,我知道我可以使用来指定要从与查询匹配的文档中返回的字段。 但是,如何返回与特定正则表达式匹配的所有字段的总和(作为新字段)? 例如,如果我的文档如下所示: 我想要每个文档匹配的所有统计信息的总和? 问题答案: 您可以定义一个包含小Groovy脚本的人工字段,它将为您完成工作。 因此,查询之后,您可以添加以下部分: 脚本所做的只是检索名称匹配的所有字段并对