《算法岗》专题
-
加密算法列表
问题内容: 我正在尝试查找可用于加密功能的列表,以替换该功能。 我了解到crypto使用,并且算法特定于每个运行node.js的系统。 使用以下命令,您可以查看系统可用的所有算法的列表。 我已经将这两个命令的内容输出到了要点。 令我困扰的是,这两个列表均未列出。 我真的很想要权威的算法列表。 问题答案: 这里的学习是和不同并且使用不同的算法。使用node的use 和method分别返回具有受支持的
-
 Javascript中的Prim算法
Javascript中的Prim算法本文向大家介绍Javascript中的Prim算法,包括了Javascript中的Prim算法的使用技巧和注意事项,需要的朋友参考一下 Prim的算法是一种贪婪算法,可为加权无向图找到最小生成树。它找到形成树的边缘子集,该树包括每个顶点,树中所有边缘的总权重最小。 该算法的工作方式是,从任意起始顶点一次构建一个树,在每个步骤中,从树到另一个顶点添加最便宜的连接。 Prim的算法如何工作? 让我们看
-
智能分页算法
问题内容: 我正在寻找智能分页的示例算法。聪明地说,我的意思是,例如,我只想显示当前页面的2个相邻页面,因此我截断了它而不是结束一个冗长的页面列表。 这是一个简单的例子,可以使它更清楚……这就是我现在所拥有的: 这就是我要结束的事情: (在此示例中,我仅显示当前页面的2个相邻页面) 我正在PHP / Mysql中实现它,并且已经对“基本”分页(没有任何删节)进行了编码,我只是在寻找一个示例来对其进
-
N路合并算法
作为Mergesort算法的一部分,双向合并被广泛研究。但我有兴趣找出执行N路合并的最佳方法? 比方说,我有N个排序100万整数的文件。我必须将它们合并成1个文件,其中会有那些1亿排序的整数。 请记住,这个问题的用例实际上是基于磁盘的外部排序。因此,在实际场景中也会存在内存限制。因此,一次(99次)合并两个文件的天真方法是行不通的。假设每个阵列只有一个小的内存滑动窗口。 我不确定是否已经有一个标准
-
 python实现SOM算法
python实现SOM算法本文向大家介绍python实现SOM算法,包括了python实现SOM算法的使用技巧和注意事项,需要的朋友参考一下 算法简介 SOM网络是一种竞争学习型的无监督神经网络,将高维空间中相似的样本点映射到网络输出层中的邻近神经元。 训练过程简述:在接收到训练样本后,每个输出层神经元会计算该样本与自身携带的权向量之间的距离,距离最近的神经元成为竞争获胜者,称为最佳匹配单元。然后最佳匹配单元及其邻近的神经
-
什么是A*算法?
本文向大家介绍什么是A*算法?相关面试题,主要包含被问及什么是A*算法?时的应答技巧和注意事项,需要的朋友参考一下 个人感觉类似最佳优先算法,都是维护一个优先队列或堆,将结点按照某个值优先的情况放进去,不同的是这次需要一个估计函数h(n) 算法思想:对于优先队列,每取出一个结点n,将他的所有儿子结点n'放入优先队列,优先级由函数f(n)计算出 g(n):起点到结点n的代价 h(n):结点n到终点的
-
什么是RSA算法?
本文向大家介绍什么是RSA算法?相关面试题,主要包含被问及什么是RSA算法?时的应答技巧和注意事项,需要的朋友参考一下 回答:RSA(Rivest-Shamir-Adelman)算法是用于签名数据和加密的第一个算法。它最广泛用于保护敏感数据。它也被称为非对称密码算法,它对两个不同的密钥(即公共密钥和私有密钥)起作用。公开密钥可以与任何人共享,并且私有密钥必须保密。
-
前向 后向算法
本文向大家介绍前向 后向算法相关面试题,主要包含被问及前向 后向算法时的应答技巧和注意事项,需要的朋友参考一下 https://blog.csdn.net/xueyingxue001/article/details/52396494
-
定长压缩算法
我试图找到一种压缩算法,我可以使用它来编码一个blob,只使用16个固定长度的符号(0b0000-0b1111)。 在没有任何压缩的情况下,我可以使用这16个符号对其各自的位值进行编码(例如,符号5(0b0101)对位0101进行编码,因此如果我的blob是100位长,我需要25个符号来表示它-但这样做不会提供压缩。 我认为我需要的是一个反向霍夫曼(在某种意义上,代码是固定长度的,但它代表可变长度
-
递归迷宫算法
我在用递归解迷宫。我的矩阵是这样的 这是更大矩阵的原型。我的求解递归方法如下所示 你们可以注意到,这里我返回一个布尔值,如果我找到一条路径,它应该会给我一个真值。但它总是给我错误的答案。我不确定我在递归方法中犯的逻辑错误。方法如下 endX=3;endY=10;
-
背包算法变异
我有以下问题: 有一组项目,每个项目有两个不同的正值a和B。 背包有两个值:totalA和totalB。这是所选项目值A和B的最大和。 我必须找出背包能装的最大物品数是多少。 示例: 输入: 总计A:10,总计B:15 项目1 A:3,B:4 项目2 A: 7,B: 2 项目4 A:2,B:1 项目5 A:4,B:6 输出: 3(项目:2、3、4) 如何使用动态规划来解决此任务?
-
最少投币算法
我被硬币面额问题难住了。 我正试图找到最低数量的硬币用来弥补5.70美元(或570美分)。例如,如果硬币数组是{100,5,2,5,1}(100 x 10c硬币,5 x 20c,2 x 50c,5 x$1和1 x$2硬币),那么结果应该是{0,1,1,3,1},此时硬币数组将由相同面额($2,1,50c,20c,10c)组成 我被困在如何从硬币数组中扣除值并返回它。 编辑:新代码
-
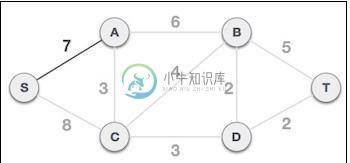
prim算法的解释
我必须使用基于最小堆的优先级队列来实现Prim的算法。如果我的图包含顶点A、B、C和D以及下面的邻接列表...[它被排序为(顶点名称,相邻顶点的权重)] 粗图: 优先级队列是什么样子的?我不知道该往里面放什么。我应该把所有东西都放进去吗?我应该只写A、B、C和D。我不知道,我真的很想得到答案。
-
用餐计划算法?
假设我有一个食物数据库,每个食物都含有一定量的脂肪、碳水化合物和蛋白质。例如,假设我有一个数据库: 什么是一个有效的算法来确定这些食物的哪些组合符合一定范围的脂肪、碳水化合物和蛋白质,并且每种食物都可以多次使用? 比如,如果我想要一个脂肪含量在20-30、碳水化合物含量在170-190、蛋白质含量在100-110之间的组合,那么2杯牛奶、5只鸡、1杯果汁和0份培根将是一个可能的解决方案,0杯牛奶、
-
贪婪背包算法
任务是典型的背包问题。求解时应采用贪婪算法。我设法创建了下面的代码,但它工作得太慢了。你能告诉我怎么加快速度吗?谢谢你。 c是背包的重量限制。n表示价格权重对的数量(这两个数字都是int类型,而不是float)。限制如下:(1)如果在相同重量的元素之间选择,价格最高的元素应该被取;(2)如果在相同价格和相同重量的元素之间选择,第一个输入的元素应该被取。