《管培生》专题
-
 拼多多校招产品培训生面经
拼多多校招产品培训生面经一面 1.自我介绍 2.你觉得自己做的最困难的一个项目是什么?为什么? 3.如果你与其他同事意见不同,被其他人质疑,你会怎么做? 4.你为什么想做产品经理?你觉得做产品最重要的特质是什么? 5.了解拼多多吗?自己会使用拼多多吗? 6.给拼多多提提建议,并说说你的改进方案。 7.反问 二面 1.自我介绍 2.说说你学的专业以及你最喜欢的一门专业课吧 3.说说你觉得自己做的最好的一段实习 4.你觉得实
-
培训因ResourceExausted错误而中断
问题内容: 我是tensorflow和Machine Learning的新手。最近,我正在制作模型。我的模特如下 字符级嵌入向量->嵌入查找-> LSTM1 字级嵌入向量->嵌入查找-> LSTM2 [LSTM1 + LSTM2]->单层MLP-> softmax层 [LSTM1 + LSTM2]->单层MLP-> WGAN鉴别器 他的模型代码 当我使用此模型时,出现以下错误。我以为我的批次太大了
-
Andoid开发人员基础培训
我正在做基本的android开发人员教程,我正在开发dogglers应用程序:https://developer.android.com/codelabs/basic-android-kotlin-training-project-dogglers-app?continue=https://developer.android.com/courses/pathways/android-基础知识-ko
-
AWS提供多种培训工作
我们目前有一个在AWS Sagemaker上运行的系统,其中几个单元有自己训练的机器学习模型工件(使用带Sagemaker SKLearning估计器的SKLearning训练脚本)。 通过使用Sagemaker的多模型endpoint,我们能够在一个实例上托管所有这些单元。 我们面临的问题是,我们需要将这个系统扩展到可以为数十万个单元训练单个模型,然后将结果模型工件托管在多模型endpoint上
-
如何培训定制模型OPENNLP?
我想训练自己的自定义模型。我可以从哪里开始? 我使用这个样本数据来训练一个模型: 基本上,我想从给定的输入中找出一些无意义的文本。 我尝试了opennlp开发文档中给出的以下示例代码,但出现了错误:Model与name finder不兼容!
-
hybris开发人员培训材料
我正在尝试使用Hybris,但无法访问Wiki。我的朋友向我提供了该应用程序的试用版,最近我在阅读论坛时遇到了下面两个文档的名称,这可以帮助我学习。 谁能告诉我怎么才能得到这两个? SAP HY400:SAP Hybris商务开发人员培训–第1部分–Hybris v6。2. SAP HY410:SAP Hybris商务开发人员培训–第2部分–Hybris v6。2. 非常感谢!
-
 米斯特白帽培训讲义
米斯特白帽培训讲义白帽,即通过正常的手段对网站内部优化(包括网站标题,网站结构,网站代码,网站内容,关键词密度等)、网站外部的发布与建设,提高网站关键词在搜索引擎排名的一种seo技术。
-
 畅游游戏策划培训生面经(已oc)
畅游游戏策划培训生面经(已oc)1、自我介绍 2、介绍你在参加比赛时遇到的困难 沟通问题与策划方面的问题,最后说了说解决方案 3、喜欢的游戏,为什么 说了一下简历上的游戏 4、聊聊fgo,你为什么喜欢 ip受众,休闲 5、让你觉得休闲的原因 没有竞争,体验偏单机,关卡难度不高,这些点对养成的要求并不高,唯一让你有动力的就是你所喜欢的人物 6、fgo出了一个蓝苹果,将体力转换成蓝苹果,你觉得他的用途是什么 (下面的答案时我结合面试
-
 腾讯 产品经理培训生 集体面试
腾讯 产品经理培训生 集体面试内容: 一、根据题目思考并提出方案 15min准备+3min回答 顺序:面试官点名,从前往后 二、问答环节 同学相互提问+面试官随机问 顺序:从后到前,针对前边同学的回答提问 我是第一个,很突然,就是那种突然被叫到名字,很紧张 回答一定要控制时间,自己还没说完就被面试官叫停了。感觉自己凉凉了 #如何判断面试是否凉了##腾讯#
-
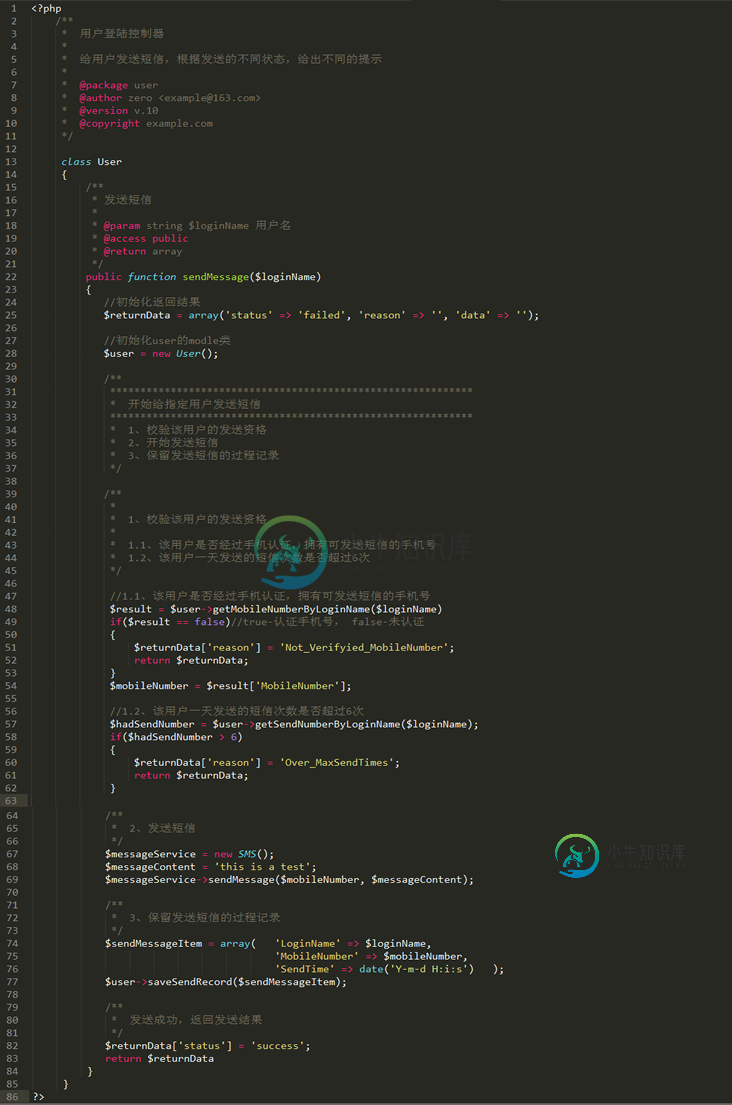 培养自己的php编码规范
培养自己的php编码规范本文向大家介绍培养自己的php编码规范,包括了培养自己的php编码规范的使用技巧和注意事项,需要的朋友参考一下 为什么我们要培养自己的编码规范? 我们写代码的时候,一个好的编码规范,对我们来说能够起到很多意向不到的效果。至少会有一下的好处: 1、提高我们的编码效率。整齐划一的代码方便我们进行复制粘贴嘛! 2、提高代码的可读性。 3、显示我们专业。别人看到了我们的代码,发现整个代码的书写流程都整齐划
-
在TensorFlow培训期间打印损失
问题内容: 我正在看TensorFlow“ MNIST对于ML初学者”教程,我想在每个训练步骤之后打印出训练损失。 我的训练循环目前看起来像这样: 现在,定义为: 我要打印的损失在哪里: 一种打印方式是在训练循环中显式计算: 我现在有两个问题: 鉴于已经在期间进行了计算,因此将其计算两次效率低下,这需要所有训练数据的前向通过次数的两倍。有没有一种方法可以访问在计算期间的value ? 我如何打印?
-
 完成正在进行的Tensorflow培训
完成正在进行的Tensorflow培训数据丢失:不是sstable(错误的幻数):可能您的文件格式不同,您需要使用不同的还原运算符? 我看过这篇文章,但是tf。火车导出元图不起任何作用。另外,如果我尝试在新的终端选项卡中生成输出,如下所示: 我得到这个错误,基本上说我不能生成输出,因为训练数据还没有保存。如何保存并完成培训?
-
如何为xgboost实施增量培训?
问题内容: 问题是由于火车数据大小,我的火车数据无法放入RAM。因此,我需要一种方法,该方法首先在整个火车数据集上构建一棵树,然后计算残差来构建另一棵树,依此类推(就像梯度增强树一样)。显然,如果我在某个循环中调用-这将无济于事,因为在这种情况下,它只会为每个批次重建整个模型。 问题答案: 免责声明:我也是xgboost的新手,但我想我已经明白了。 在进行第一批训练后,请尝试保存模型。然后,在连续
-
 贝壳花桥 培训运营面经
贝壳花桥 培训运营面经意向沟通 部门岗位介绍 工作地点意向 一面 28min 总体比较轻松,面试官节奏把握得比较好,介绍也比较详细。 自我介绍/简历深挖 相关经历中最有成就感的事情 未来职业方向思考 工作生活平衡问题,爱好 老师对自己的评价 家庭情况 主要还是工作地点 反问 二面 30min 总体感觉有点尴尬,面完 没联络应该是g了 发面经攒人品:( 暖场寒暄 自我介绍 相关经历深挖/最大收获 最大优点缺点 工作地点问
-
 蔚来培训运营实习面经
蔚来培训运营实习面经1、自我介绍 2、以后的职业规划 3、为什么想做培训运营(之前只做过社区运营) 4、个人的优势 5、对新能源汽车行业的了解和认识 不知道为什么对蔚来充满好感,感觉名字就很好听🥰#非技术面试记录#