《群面模拟》专题
-
 无法在 Azure DataBricks 群集上执行 scala 代码
无法在 Azure DataBricks 群集上执行 scala 代码我正在尝试为DataBricks设置一个开发环境,因此我的开发人员可以使用VSCODE IDE(或其他一些IDE)编写代码并针对DataBricks集群执行代码。 因此,我阅读了DataBricks Connect的文档,并按照文档中的建议进行了设置。https://docs.databricks.com/dev-tools/databricks-connect.html#overview 发布安
-
单节点Ubuntu集群上的RHadoop作业失败
当我们使用包“RMR”(RHadoop的一部分)并从RStudio中运行的R程序内部调用mapreduce()时,就会出现错误。 为了简化这篇文章,我展示了一个失败的非常简单的程序(其他更大的程序以相同的错误消息失败) 在R-Studio控制台上显示的错误有
-
火花:HDFS块与集群核心与rdd分区
我对spark有疑问:HDFS块vs集群核心vs rdd分区。 假设我正在尝试在HDFS中处理一个文件(例如块大小为64MB,文件为6400MB)。所以理想情况下它确实有100个分裂。 我的集群总共有 200 个核心,我提交了包含 25 个执行程序的作业,每个执行程序有 4 个核心(意味着可以运行 100 个并行任务)。 简而言之,我在rdd中默认有100个分区,100个内核将运行。 这是一个好方
-
Quartz在集群环境中不能正常工作
我在WebSphere8.5.5上使用Quartz-2.2.3,在集群环境中,我有2个节点,每个节点上有3个JVM。 我正在应用程序启动时配置作业。 问题是作业在每个节点上配置一次,我希望它在两个节点上只配置一次,而不是每个节点上都配置一次。 我的配置如下: QuartzConfig.Properties: ApplicationContextListener:
-
活动 MQ:集群中的咨询(代理网络)
我有两个ActiveMQ代理(A和B),它们被配置为具有静态列表的代理网络集群。 正常的消息消耗和存储转发按预期工作。也就是说:连接到代理B的消费者将拾取A上未连接消费者的消息。 我确实看到,咨询信息并非如此。在我当前的设置中,我有一个应用程序通过连接到advisory来监控DLQ:。当消息到达DLQ时,我需要它来触发某些操作。 在测试集群时,我没有看到任何针对代理A上的DLQ消息的建议消息传到我
-
Liferay 7.0获得通过群体继承的角色
我正在努力寻找任何方法来检索通过组继承的角色。 我创建了一个组mygroup和一个角色mygrouprole,将用户分配给mygroup,并将mygroup分配给mygrouprole。当我点击一个用户时,我可以看到他们继承了mygrouprole。 从我的jsp页面,我调用。 当用户被直接分配到角色,但不是通过一个组传递时,这种方法可以很好地工作。 到目前为止,我已经尝试了许多替代功能,但似乎没
-
无法使用strom群集从kafka读取数据
我正在运行Strom集群,其中2个主管和1个灵气正在运行。我在哪里读Kafka与主题ID"topic1"。但在UI上我得到以下错误 JAVARuntimeException:java。lang.RuntimeException:org。阿帕奇。动物园管理员。KeeperException$NoNodeException:KeeperErrorCode=storm中/brokers/topic/to
-
如何从Kafka的两个不同集群消费?
我有两个Kafka集群说A和B,B是A的复制品。仅当 A 关闭且相反,我才希望使用来自集群 B 的消息。然而,使用来自两个集群的消息会导致重复的消息。那么,有什么办法可以将我的 kafka 使用者配置为仅从一个集群接收消息。 谢谢-
-
Kafka集群增加副本因子不起作用
嗨,在执行本文档中的步骤时,我遇到了一个增加Kafka的复制因子的奇怪问题:https://kafka.apache.org/documentation/#basic_ops_increase_replication_factor 症状看起来复制因子增加根本不起作用。 请帮帮忙 我的Kafka设置是 Kafka版本:kafka_2.12-2.1.0 服务器: 主机名服务器-0 (192.168.0
-
GlassFish群集实例中的JMS队列未同步
我在CLUSTERED Glassfish 3.1.1中使用消息驱动bean时遇到问题。问题在于Glassfish中的队列,队列在实例之间不同步。我正在尽力解释下面的情况。 我在GlassFish集群中创建了2个实例,创建了一个JMS QueueConnectionFactory,创建了一个JMS队列。他们的目标对准了集群。然后,我在集群中部署了web应用程序和MessageDrivenBean模
-
hazelcast jet是否从集群发送/接收数据
我们在一台服务器上托管了一个Hazelcast集群,在同一地区的不同服务器上的不同应用程序使用Hazelcast Jet客户端实例使用管道聚合来自Kafka源的数据。 在这个设置中,Jet client实例是否发送它从Kafka源Hazelcast集群接收的数据,这将涉及大量的IO?或者当我们创建管道时,Hazelcast集群本身创建到Kafka的连接,这个连接来自Jet集群而不是客户端应用程序?
-
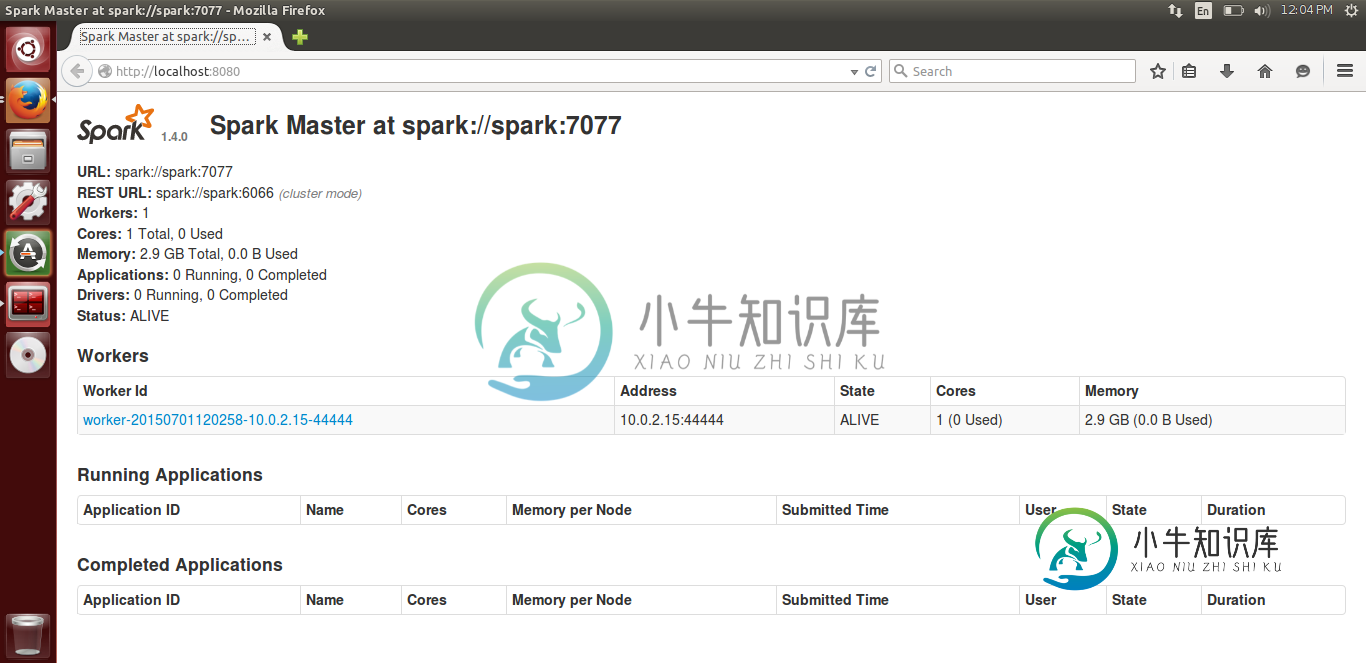 Spark独立集群-从机未连接到主机
Spark独立集群-从机未连接到主机我正试图按照官方文档设置一个Spark独立集群。 我的主人在一个运行ubuntu的本地vm上,我也有一个工作人员在同一台机器上运行。它是连接的,我能够在大师的WebUI中看到它的地位。 以下是WebUi图像- 我已经在两台机器上的/etc/hosts中添加了主IP地址和从IP地址。我遵循了SPARK+独立集群中给出的所有解决方案:无法从另一台机器启动worker,但它们对我不起作用。 我在两台机器
-
在无spark UI的AWS EMR中监控spark集群
我正在AWS EMR上运行一个火花集群。如何在不使用spark UI的情况下获得在AWS EMR上运行的作业和执行器的所有细节。我打算用它来监视和优化。
-
使用spark在Spring创建Redis群集客户端
我有一个项目连接到独立的redis,客户端创建为: 用于绝地武士和spring data redis的库版本为: 现在我需要移动到集群redis,并将客户端创建更改为 通过此代码更改,我在群集中找不到可访问的节点,如下所示: } 由于spark-2.1.3中运行了spark应用程序,由于版本依赖性,我需要使用相同的spring data redis。如果没有jedis和spring data re
-
连接到Apache Kafka多节点集群中的Zookeeper
我按照以下说明设置了一个多节点kafka集群。现在,如何连接到动物园管理员?在JAVA中,只连接一个来自生产者/消费者端的动物园管理员可以吗?或者有办法连接所有的动物园管理员节点吗? 设置多节点阿帕奇动物园守护者集群 在集群的每个节点上,将以下行添加到文件kafka/config/zookeeper.properties中 在群集的每个节点上,在由 dataDir 属性表示的文件夹中创建一个名为