
Spark独立集群-从机未连接到主机

我正试图按照官方文档设置一个Spark独立集群。
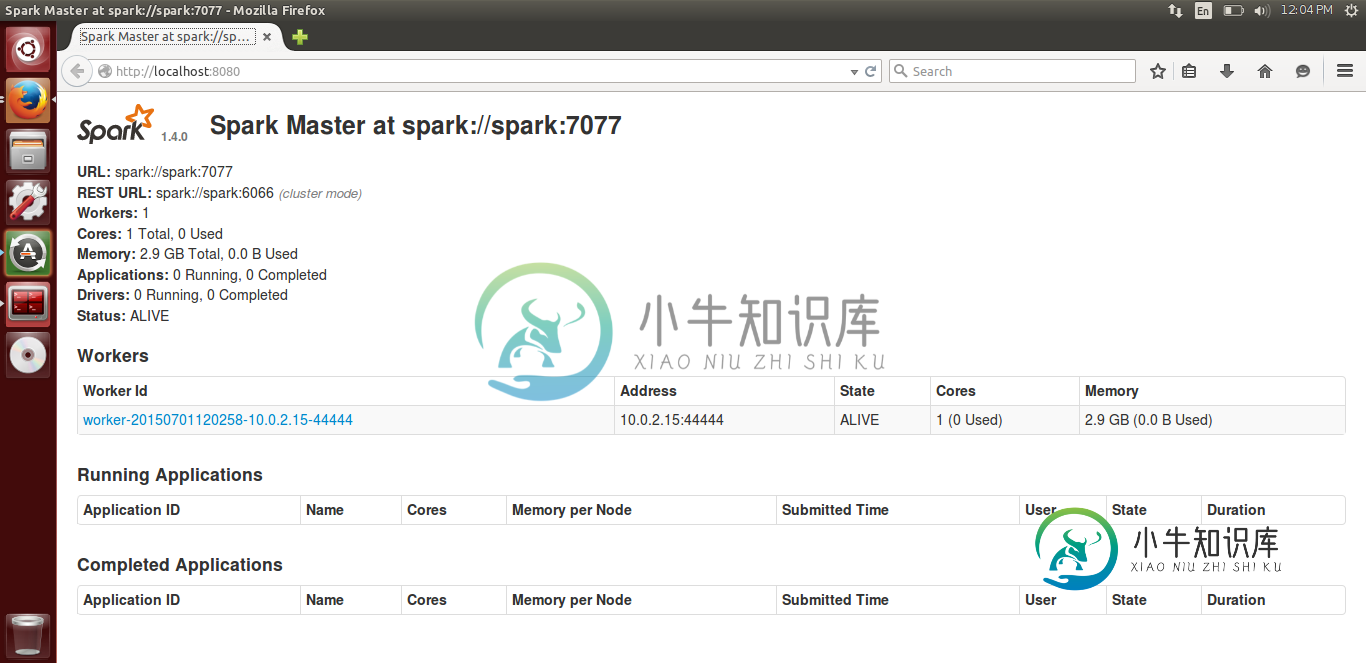
我的主人在一个运行ubuntu的本地vm上,我也有一个工作人员在同一台机器上运行。它是连接的,我能够在大师的WebUI中看到它的地位。
以下是WebUi图像-
15/07/01 11:54:16 WARN ReliableDeliverySupervisor: Association with remote system [akka.tcp://sparkMaster@spark:7077] has failed, address is now gated for [5000] ms. Reason is: [Association failed with [akka.tcp://sparkMaster@spark:7077]].
15/07/01 11:54:59 ERROR Worker: All masters are unresponsive! Giving up.
15/07/01 11:54:59 INFO Utils: Shutdown hook called
root@worker:~# telnet spark 7077
Trying 10.xx.xx.xx...
Connected to spark.
Escape character is '^]'.
Connection closed by foreign host.
我已经在两台机器上的/etc/hosts中添加了主IP地址和从IP地址。我遵循了SPARK+独立集群中给出的所有解决方案:无法从另一台机器启动worker,但它们对我不起作用。
我在两台机器的spark-env.sh中设置了以下配置-
导出SPARK_MASTER_IP=SPARK
非常感谢任何帮助。
共有1个答案

我遇到和你完全一样的问题,只是想出如何让它发挥作用。
问题是您的spark master正在监听主机名(在您的示例spark中),这导致同一主机上的工作人员能够成功注册,但通过命令start-slave.sh spark://spark:7077从另一台计算机注册失败。
解决方案是确保在conf/spark-env.sh文件中用ip指定值SPARK_MASTER_IP
SPARK_MASTER_IP=<your host ip>
-
工人出现在图片上。为了运行我的代码,我使用了以下命令:
-
应用程序不是那么占用内存,有两个连接和写数据集到目录。同样的代码在spark-shell上运行没有任何失败。 寻找群集调优或任何配置设置,这将减少执行器被杀死。
-
我有一个向spark独立单节点集群提交spark作业的maven scala应用程序。提交作业时,Spark应用程序尝试使用spark-cassandra-connector访问Amazon EC2实例上托管的cassandra。连接已建立,但不返回结果。一段时间后连接器断开。如果我在本地模式下运行spark,它工作得很好。我试图创建简单的应用程序,代码如下所示: SparkContext.Sca
-
我可以确认使用spark shell连接到仪表盘,例如。 作品 但是 没有并给出错误
-
当我尝试使用start-slave.sh连接到主服务器时,spark://master:port如这里所述 我正在得到这个错误日志 我尝试使用本地ip和本地名称访问主服务器(我设法同时使用和不使用密码ssh到主服务器、用户和root用户) 谢了!