《群面模拟》专题
-
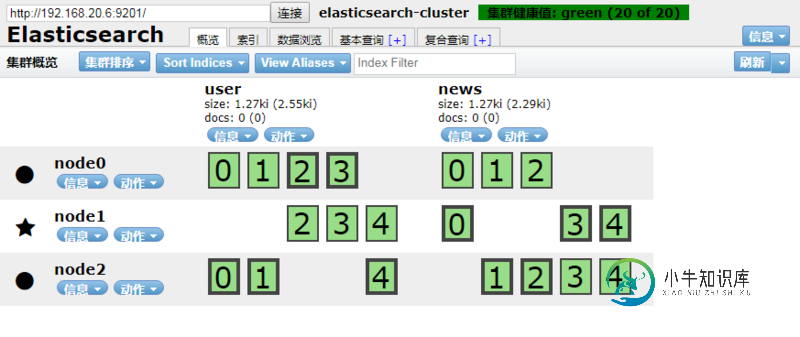 使用docker快速部署Elasticsearch集群的方法
使用docker快速部署Elasticsearch集群的方法本文向大家介绍使用docker快速部署Elasticsearch集群的方法,包括了使用docker快速部署Elasticsearch集群的方法的使用技巧和注意事项,需要的朋友参考一下 本文将使用Docker容器(使用docker-compose编排)快速部署Elasticsearch 集群,可用于开发环境(单机多实例)或生产环境部署。 注意,6.x版本已经不能通过 -Epath.config 参数
-
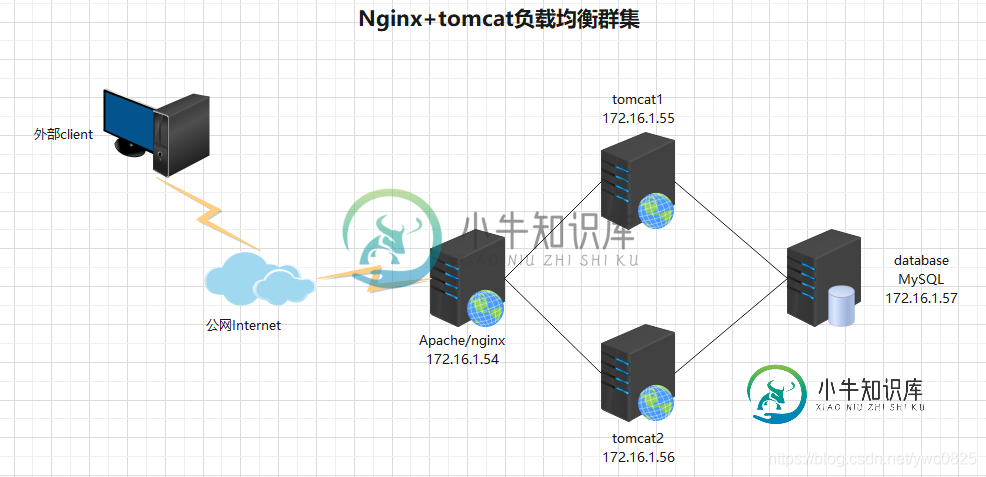 Nginx+tomcat负载均衡集群的实现方法
Nginx+tomcat负载均衡集群的实现方法本文向大家介绍Nginx+tomcat负载均衡集群的实现方法,包括了Nginx+tomcat负载均衡集群的实现方法的使用技巧和注意事项,需要的朋友参考一下 实验环境如下 这里需要准备4台服务器(1台nginx、2台tomcat做负载、一台MySQL做数据存储) 准备软件包如下: 软件包地址连接: 链接: https://pan.baidu.com/s/1Zitt5gO5bDocV_8TgilvRw
-
如何在Elasticsearch集群上最大化CPU核心
问题内容: 我必须设置多少个分片和副本才能使用群集中的每个cpu核心(我希望100%的负载,最快的查询结果)? 我想使用Elasticsearch进行聚合。我读到Elasticsearch使用多个cpu核心,但是没有找到关于cpu核心在分片和副本方面的确切细节。 我的观察是,单个分片在查询时使用的内核/线程不超过1个(考虑到一次仅查询一个)。使用副本时,查询1-shard索引的速度不会更快,因为E
-
Spark:以编程方式获取集群核心数
问题内容: 我在纱线簇中运行我的spark应用程序。在我的代码中,我使用队列的可用数量核心在数据集中创建分区: 我的问题:如何通过编程方式而不是通过配置获取可用的队列核心数? 问题答案: 有多种方法可以从Spark获取执行程序的数量和集群中的核心数量。这是我过去使用的一些Scala实用程序代码。您应该可以轻松地使其适应Java。有两个关键思想: 工人人数是执行者人数减去一或。 每个工人的核心数可以
-
添加Hazelcast集群成员的自定义名称?
我正在做hazelcast监控服务,我需要为每个集群成员添加客户名称,以了解哪个模块不在集群中。 我想要成员的常量名称,而不是 这能做到吗?
-
 Linux切换用户的有效群组(newgrp命令)
Linux切换用户的有效群组(newgrp命令)主要内容:newgrp命令的底层实现我们知道,每个用户可以属于一个初始组(用户是这个组的初始用户),也可以属于多个附加组(用户是这个组的附加用户)。既然用户可以属于这么多用户组,那么用户在创建文件后,默认生效的组身份是哪个呢? 当然是初始用户组的组身份生效,因为初始组是用户一旦登陆就获得的组身份。也就是说,用户的有效组默认是初始组,因此所创建文件的属组是用户的初始组。那么,既然用户属于多个用户组,能不能改变用户的初始组呢?使用命令
-
有没有得到kubernetes集群的外部端口
我在kubernetes集群中所有节点的外部端口上公开了一个服务,该服务来自: 您已经在集群中所有节点的外部端口上公开了服务。如果要将此服务公开到外部internet,则可能需要为服务端口(TCP:30002)设置防火墙规则以服务通信量。 有关详细信息,请参阅http://releases.k8s.io/release-1.2/docs/user-guide/services-firewalls.
-
使用LoadBalancer服务在Kubernetes中公开Kafka集群
什么是port和targetport? 是否为每个代理设置LoadBalancer服务? 这些多个代理是否映射到cloud LB的单个公共IP地址? K8S/Cloud之外的服务如何访问单个代理?通过使用?或者使用?。还有,这里用的是哪个端口?还是? 如何在Kafka Broker的属性中指定此配置?对于k8s集群内部和外部的服务,As端口可能不同。 请帮忙。
-
如何替代/过渡一个Kafka消费群体?
我有一个包含多个Kafka作品的资源库。我想将其中一个流提取到它自己的存储库中。但是,我不确定如何处理那个流的消费群体。我的意思是:在新的存储库中,流将有一个不同的< code>application.id。据我理解,消费者组的名称是基于< code>application.id设置的。如果我简单地关闭旧流,对于每个主题的每个分区,新流将从第零个偏移量开始,而不是从旧流停止的偏移量开始。这将导致输
-
elasticsearch集群运行中的Perm Gen空间问题
我们正在运行带有6个节点的集群,最近几天我在集群中面临java.lang.OutOfMemoryError PermGen空间问题,这会影响到节点,同样也会掉下来。我正在重新启动特定节点以使其处于活动状态。 我们试图通过给集群重负载来解决这个问题,但不幸的是,它无法复制。但我们在生产过程中会一次又一次地遇到同样的问题。 这里介绍了一些yml文件配置 内存配置 使用以下配置更新问题 我怀疑与此问题相
-
检查akka集群中是否存在参与者
我遇到了一个场景,我需要检查特定的参与者是否存在,这可以通过ActorSystem完成。actorSelection方法,指定参与者路径 但是,当本地节点上存在此类参与者时,此方法可以正常工作。若actor系统由多个节点组成,并且actor存在于另一个节点上,则该方法告诉我们actor不存在。若我给出指定远程参与者系统的字符串,那个么这个方法可以工作。但在actorSelection方法中指定远程
-
带有Spring应用程序的JBoss AS7 JMS集群
我在JBoss7 JMS集群上运行Spring webapp时遇到了一个问题。 exampleListener.java如下所示: 当我启动live服务器时,消息由ExampleListener处理--这是可以的。当我启动备份服务器时,我得到了错误javax.naming.NameNotFoundException beacause在JNDI下没有公开--这时只有主服务器在工作,它不是集群。当li
-
使用无法访问的群集IP的kubernetes api
这很奇怪。我是不是在设置过程中漏掉了什么 我似乎无法从集群上的任何地方到达10.100.0.1地址。但是,其他一些clusterIP地址可以从节点访问 但是,如果我用另一个地址检查相同的路径,项将被重调
-
Spark挂起了Docker Mesos集群的身份验证
我试图使用Docker和Zookeeper模拟一个多节点Mesos集群,并尝试在其上运行一个简单的(py)Spark作业。这些Docker容器和pyspark脚本都在同一台机器上运行。但是,当我执行Spark脚本时,它挂在: Mesos从机不断输出: 而Mesos主控器不断输出:
-
群集密钥上的Spark Cassandra连接器联接
我试图在卡桑德拉的一小部分数据上运行一个火花工作。我手头有一个键的RDD(分区和集群列),我只想在这些键上运行我的作业。 我在BoundStatementBuilder上收到以下错误:19