《运营人求职交流聚集地》专题
-
 游戏运营/发行面经(二)
游戏运营/发行面经(二)接上篇 三面 项目大大大leader面 腾讯会议面 43min 1.玩得最久的游戏 段位 最喜欢的游戏 2. 老头环做的好的点和做的不好的点 3. 有没有关注王者的活跃或者付费类活动 会不会参加 印象最深刻的游戏活动 4. 策划活动 举最关键的三个点 5. 实习经历中 那一个活动最让你有成就感 具体什么东西让你有成就感 你扮演了什么角色 6. 人生中最有压力和挫败感的事情 7. 遇到很多繁琐的事情
-
 腾讯云运营开发oc timeline
腾讯云运营开发oc timeline5.24笔试 5.25一面 5.26二面 5.29三面 6.5 oc! 一面技术官主要问的项目的东西,中间根据项目问了我springsecurity,涉及到到的整个登录流程,然后我服务器的一些东西聊的很开心,一个小时左右,反问了技术栈,氛围,岗位职责 二面总监面,自我介绍过后介绍项目,根据项目问我知识注入是什么,然后开idea手撕一道算法。算法很简单,但是要求要对使用者友好,并且优雅,半个小时左右
-
 途虎养车 仓储运营岗
途虎养车 仓储运营岗二面是一名物流管理专业的学长,对岗位介绍的很清楚 1.自我介绍 2.对实习经历进行提问 3.职业规划 4.谈谈你过去两年最成功的案例 5.对岗位具体介绍 6.反问 主要考察语言沟通能力,项目组织策划能力。 介绍岗位需要对接上下级,负责仓储部门的培训以及和讲师进行对接,制定培训计划等等。 学长讲的很透彻很中肯,从应届生的角度出发,但是面试时表达出现问题,导致和岗位匹配度不高,大概率GG了
-
 新希望六和产品运营
新希望六和产品运营没有人回答相关的经历,我来做第一个嘿嘿 笔试:很简单的行测题(属于我从来没刷过题都能做的)当时以为要开摄像头所以计算题心算奈何垃圾选错了(一面的时候面试官还问我为啥丢分了哈哈哈哈哈好丢人) 一面:业务面,业务官非常有礼貌,问的问题都在运营常规问题内,感觉很聊得来,果然面完2个小时就收到通知通过了约了第二天的群面 二面(终面):群面,各个岗位的同学们,其中不乏优秀的大佬。主要三个环节:自我介绍,估算
-
 华为运营岗秋招面试
华为运营岗秋招面试一面:群面,二十个人左右。 大概问的问题:本硕毕业院校、在校学习成绩、在校所获荣誉;在校期间从事的和应聘岗位相关的科研项目;大厂实习经验;项目经历和实践经历;实践过程中技术亮点和个人突出成果;职业规划;EHS和抗压能力 面试的时候尽量要早到半个小时左右,给自己留出一些缓冲、准备时间,群面的时候人是比较多的,尽量展现自己自信的一面,让面试官关注到你,回答的时候一定要大方、条理清晰,让所有人都能够听清
-
 拼多多-运营管陪 面经
拼多多-运营管陪 面经#非技术2023笔面经# 第一轮业务面: 1. 请介绍一下你对拼多多的了解和认识? 2. 你认为拼多多的核心竞争力是什么? 3. 请分享一下你在其他电商平台的运营经验,有哪些成功案例? 4. 你对拼多多的用户画像有什么了解? 5. 请谈谈你对拼多多的营销策略的看法? 6. 百亿补贴的看法,为什么京东也要做百补? 7. 请谈谈你对拼多多的供应链管理的看法? 8. 你如何评估拼多多的产品质量和售后服务
-
分别写出数组的交集、并集、差集、补集这四个方法
本文向大家介绍分别写出数组的交集、并集、差集、补集这四个方法相关面试题,主要包含被问及分别写出数组的交集、并集、差集、补集这四个方法时的应答技巧和注意事项,需要的朋友参考一下 这几个方法全是 O(n2) 的复杂度…性能很差
-
公证人签署后,发起人无法将状态提交给vault_linear_states
我有一个基于UUID检索未消费州的查询。 问题陈述:在 Corda 3.0 上,使用 Postgres。查询保管库时,同一 UUID 的多个/缺少未使用状态。由 2 个参与者、借款人和贷款人组成的义务状态,从不同的交易过渡到不同的生命周期。但在某些时候 当借款人查询其保险库以查找该uuid的未使用状态时,它返回了2条记录。 当贷方查询其保管库以查找该uuid的未使用状态时,它返回了0条记录。 在公
-
Maven-用于聚集的“全部”或“父”项目?
问题内容: 出于教育目的,我设置了一个这样的项目布局(为了更好地配合日食,将其布置为扁平状): 父级包含一个包含核心,优化和全部的汇总项目。Core实现了应用程序的强制性部分。Opt是可选部分。所有人都应该将核心与opt相结合,并将这两个模块列为依赖项。 我现在正在尝试制作以下工件: product-core.jar product-core-src.jar 产品核心与dependencies.j
-
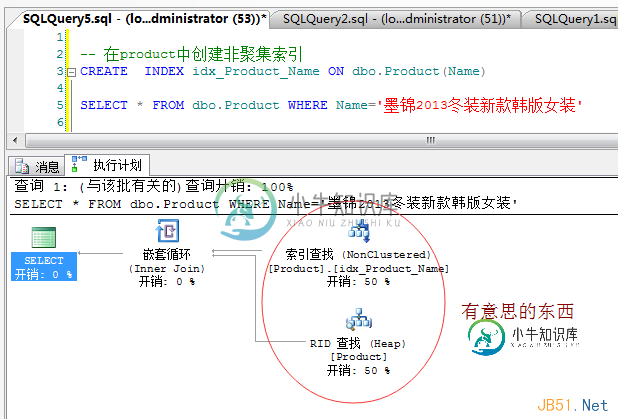 Sql Server中的非聚集索引详细介
Sql Server中的非聚集索引详细介本文向大家介绍Sql Server中的非聚集索引详细介,包括了Sql Server中的非聚集索引详细介的使用技巧和注意事项,需要的朋友参考一下 非聚集索引,这个是大家都非常熟悉的一个东西,有时候我们由于业务原因,sql写的非常复杂,需要join很多张表,然后就泪流满面了。。。这时候就有DBA或者资深的开发给你看这个猥琐的sql,通过执行计划一分析。。。或许就看出了不该有的表扫描。。。万恶之源。
-
SQL Azure无法识别我的聚集索引
问题内容: 当我尝试将行插入到SQL Azure表中时,出现以下错误。 此版本的SQL Server不支持没有聚集索引的表。请创建一个聚集索引,然后重试。 我的问题是我在该表上确实有一个聚集索引。我使用SQL Azure MW生成Azure SQL脚本。 这是我正在使用的: 为什么SQL Azure无法识别我的群集密钥?我的脚本错了吗? 问题答案: 您的脚本只会创建该表(如果该表尚不存在)。也许还
-
是Spring集成聚合器单线程执行
我在应用程序中使用拆分器聚合器模式。我有以下配置- 我的所有通道(CH1、CH2、CH3)都是。Splitter输入通道CH1的源代码是一个文件。 在我的测试中,我观察到即使在CH1通道中添加两个文件,在给定时间也只有一个文件被处理。所以我在我的CH1通道中添加了一个轮询器,现在正在同时处理CH1通道上的多个输入消息。 在聚合器方面,我也注意到执行总是单线程的,即直到第一个线程完成执行,第二个线程
-
TWIML:动词聚集和停顿没有作用
-
对数正态分布中的聚集参数
我想知道是否有可能从一个对数正态分布中得到一个聚合参数。在生态学中,通常使用负二项式中的聚集参数k,该参数度量数据中聚类或聚集或异质性的数量:越小的k意味着更多的异质性。负二项分布的方差为μ+μ2/k,当k变大时,方差接近均值,分布接近泊松分布。在R中,聚合参数称为size参数(Bolker,2008)。 当我在fitdistr中拟合我的数据时,我的数据比负二项式、gamma和Poisson更符合
-
使用spring批量远程分区将工作移交给spring集成工作流
我想写一个批处理,从一个表读取数据,对数据进行分区,并将其交给一个spring集成工作流。 批处理和集成工作流都是独立的maven项目,集成项目是批处理项目中的依赖项。 我的批处理有一个非常小的作业上下文(xml)。只有一个分区器和一个任务。在这个任务中,我将数据(为了测试目的而硬编码)放入一个spring集成网关。之后,我将消息传递到outbound-channel-adapter中,它只是将消