《留学生》专题
-
Julia-并行数学优化器
我通过Julia使用GLPK,我需要反复优化同一个GLPK。Prob。每次优化之间的变化是变量的某些组合固定为0 简单的放入伪代码 当我运行这个程序时,看起来CPU1就像一个调度器,保持在9-11%的范围内,CPU3和CPU4上的负载在0和100%之间交替,尽管从来没有同时发生过。。。CPU2上的负载保持在0% 这可能需要一点时间,我想使用所有的核心 然而,使用Julia的并行功能有点麻烦,尤其是
-
使用mutate_each的数学运算
我想在dplyr中构建mutate_each/summarise_each:如何选择某些列并为变异列命名?线程。它讨论了将mutate应用于多个列。然而,我知道我们可以使用函数,如等,但我不知道如何应用数学运算,如加法、乘法、除法和减法。 以下是我的数据: 我怎样做才能最大限度地减少重复? 应用上述操作后的预期输出:
-
通用浮点数学查询
为什么当输出0.3时,它能解释错误(如果是的话),而当相加发生时,它却不能解释错误呢?
-
scikit学习GridSearchCV弃用警告
我正在使用scikit-learn 0.14的GridSearchCV,但总是得到以下警告: /Library/Frameworks/epd 64 . framework/Versions/7.2/lib/python 2.7/site-packages/sk learn/grid _ search . py:706:deprecation warning:忽略GridSearchCV的附加参数!
-
学习拟合函数分类
我在scikit learn中使用fit函数进行分类培训。例如,在使用随机林时,通常使用以下类型的代码: 不幸的是,在使用Python 3时,我得到了以下错误: C:\Anaconda3\lib\site-pack\skLearning\base.py:175: DeprecationWarning:inspect.getargspec()已弃用,请使用inspect.signature()代替林
-
 机器学习算法面试
机器学习算法面试问题答案可关注公众号 机器学习算法面试,回复“资料”即可领取啦~~ 1.机器学习理论 1.1 数学知识 1.1.1 机器学习中的距离和相似度度量方式有哪些? 1.1.2 马氏距离比欧式距离的异同点? 1.1.3 张量与矩阵的区别? 1.1.4 如何判断矩阵为正定? 1.1.5 距离的严格定义? 1.1.6 参考 1.2 学习理论 1.2.1 什么是表示学习? 1.2.2 什么是端到端学习? 1.2
-
 美团机器学习面经
美团机器学习面经8.6笔试 四道算法题+三道多选题,算法题简单到中等难度 8.15一面 总结:全程1个小时,面试官人很好,会引导,会告诉你简历怎么改还有面试方面的问题,并且提问问题我回答之后面试官都会说一下自己的看法和正确的解答,我觉得还挺有帮助的。 先确认面试者信息,并介绍了下自己,然后让我自我介绍 挑一个自己参与度高的项目讲一讲 挖各种细节,挖的很深,所有流程都问得很仔细,并且看得出面试官有在思考和针对提问
-
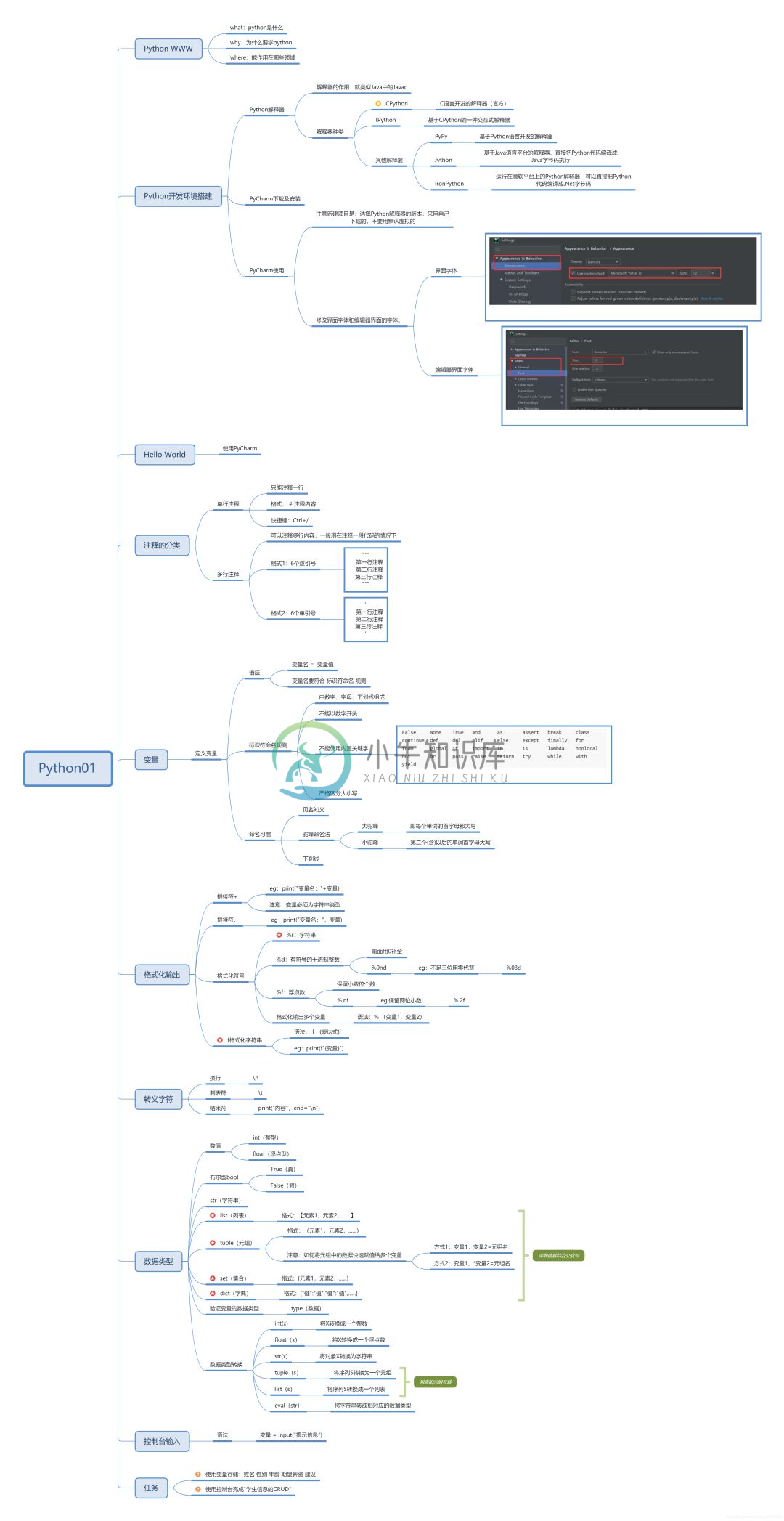 Python:必看学习路线图
Python:必看学习路线图导语:这是我刚开始学习python时的一套学习路线,从入门到上手。一、Python入门、环境搭建、变量、数据类型二、Python运算符、条件结构、循环结构三、Python函数四、做一次综合练习,做一个控制台的员工管理"""需求:员工管理系统功能:1.添加员工信息2.删除员工信息3.修改员工信息4.查看单个员工信息5.查看所有员工信息6.退出技术:函数、数据类型(字典列表)、循环、条件语句
-
机器学习:聚类分析
监督学习使用标记数据对 (x,y) 学习函数:X\rightarrow Y 。但是,如果我们没有标签呢?这类没有标签的学习方式被称为无监督学习。 无监督学习:如果训练样本全部无标签,则是无监督学习。例如聚类算法,就是根据样本间的相似性对样本集进行聚类试图使类内差距最小化,类间差距最大化。 主要用途: 自动组织数据。 理解某些数据中的隐藏结构。 在低维空间中表示高维数据。
-
机器学习:梯度下降
迭代与梯度下降求解 求导解法在复杂实际问题中很难计算。迭代法通过从一个初始估计出发寻找一系列近似解来解决优化问题。其基本形式如下
-
机器学习:Rademacher复杂度
对于给定训练集 {D}' ,我们希望基于学习算法 L 学得的模型所对应的假设 h 尽可能接近目标概念 c。 为什么不是希望精确地学到目标概念c呢?因为机器学习过程受到很多因素的制约: 获得训练结果集 {D}' 往往仅包含有限数量的样例,因此通常会存在一些在 {D}' 上“等效”的假设,学习算法无法区别这些假设。 从分布 D 采样得到的 {D}' 的过程有一定偶然性,即便对同样大小的不同训练集,学得结果也可能有所不同。
-
机器学习:特征降维
主成分分析是一种降维方法,通过将一个大的特征集转换成一个较小的特征集,这个特征集仍然包含了原始数据中的大部分信息,从而降低了原始数据的维数。换句话说就是减少数据集的特征数量,同时尽可能地保留信息。降维是将训练数据中的样本(实例)从高维空间转换到低维空间,该过程与信息论中有损压缩概念密切相关。同时要明白的,不存在完全无损的降维。
-
机器学习:基本概念
机器学习即Machine Learning,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。目的是让计算机模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断完善自身的性能。简单来讲,机器学习就是人们通过提供大量的相关数据来训练机器。
-
 网易机器学习一面
网易机器学习一面【写面筋积累好运】 半小时的第一次面试,也是时隔1个月来的面试,希望不是kpi吧。 #网易信息集散地# #23届找工作求助阵地# 项目没有怎么问,基本上是问的项目里面的八股文。 手写某某网络传播公式。 手写xgb的计算公式。 解释用到的网络结构。 问dataset和dataloader的区别。 问python的迭代器什么的(不会) 手撕了一个回溯算法的题,写出来了,但是面试官说没有看到输出,慌得一
-
 居学科技技术面(golang)
居学科技技术面(golang)1. 介绍gfs项目时,首先总体:在线的分布式文件系统。再具体聊接口函数 2. channel如何实现(从channel的底层实现上来说):并发安全 3. http的三次握手,为什么两次不行呢 4. rpc和grpc的区别 5. defer的先后顺序 6. redis的数据类型。 7. mysql的事务隔离级别,事务的四个特性 面试体验感很低,反正就是找马上能上手的,不好评论