《设计人秋招体验最好的公司》专题
-
多个选项,选择最好的?[重复]
我有一个可以包含多个可选ID的类,该类将选择第一个可用ID并将其返回给调用方。像下面这样。 我想使用像map和orElse这样的可选方法,但在这种情况下,它会导致太多的嵌套。另外两个伪代码选项可能是。 有没有比我现有的方法更好的方法?我很想通过做香草isPresent()检查来避免嵌套。
-
计算矩阵的最小值和最大值
这个问题可能是封闭的,因为它听起来很模糊,但我真的问这个,因为我不知道或者我的数学背景不够。 我试图实现一个挑战,其中一部分挑战要求我计算矩阵的最小值和最大值。我对矩阵的实现及其操作没有任何问题,但是什么是矩阵的最小值和最大值?考虑到3x3矩阵是9个数中最小的数,最大的是最大的还是其他什么?
-
django设计模式/最佳实践:筛选查询集
为了提供良好的用户体验,实现需要做一些事情 视图中的 : 检查传递的筛选器参数是否有效 检查筛选器的类型(基于其他模型或自定义筛选器),以便将正确的条件应用于查询集 (可选)使筛选器累积的方法(即可以不断添加筛选器) 根据筛选器选择显示正确的结果集n 显示筛选器时,请识别应用的筛选器,以便当前应用的筛选器显示为文本,而不是超链接。
-
UI 设计基础 为 Apple Watch 而设计
重要: 本文档是开发过程中使用的API或者技术的初步文档。苹果提供该文档以帮助你按照文档中描述的方式为将来采用苹果产品上使用的技术和界面设计做好准备。后期该文档中信息可能会有所变动,所以依据本文档开发的软件应使用最终的操作系统软件和最终文档进行测试。该文档可能会根据相关API或技术进行更新。 Apple Watch主要体现如下主题: 1.个体化.Apple Watch属于可穿戴设备,其UI需要适应
-
 Kafka高性能设计之架构设计
Kafka高性能设计之架构设计主要内容:1.Kafka 的技术难点,2.Kafka 架构设计,3.Kafka的宏观架构设计,4.Kafka 的整体架构1.Kafka 的技术难点 Kafka 为实时日志流而生,要处理的并发和数据量非常大。可见,Kafka 本身就是一个高并发系统,它必然会遇到高并发场景下典型的三高挑战:高性能、高可用和高扩展。 为了简化实现的复杂度,Kafka 最终采用了很巧妙的消息模型:它将所有消息进行了持久化存储,让消费者自己各取所需,想取哪个消息,想什么时候取都行,只需要传递一个消息的 offset 进行
-
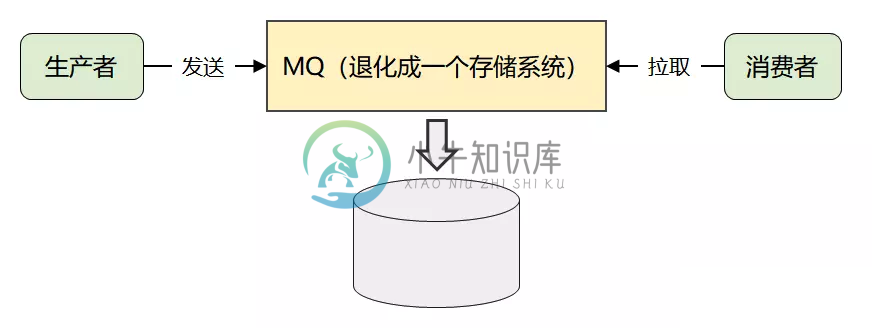
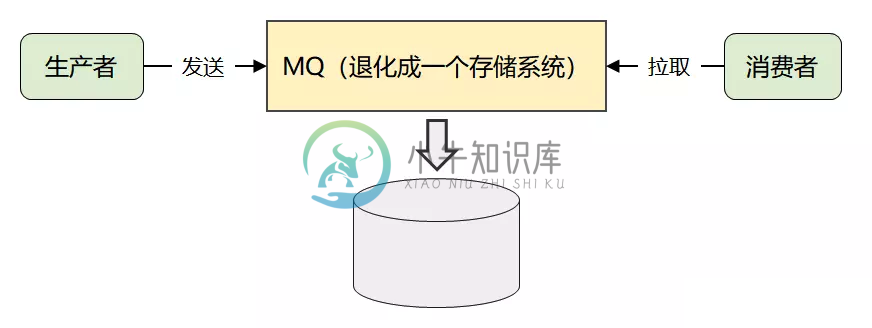 Kafka高性能设计之存储设计
Kafka高性能设计之存储设计主要内容:1.Kafka存储难度,2.Kafka 的存储选型分析,3.Kafka 的存储设计Kafka使用的是Logging(日志文件)这种很原始的方式来存储消息 对于存储设计有一些知识点: Append Only、Linear Scans、磁盘顺序写、页缓存、零拷贝、稀疏索引、二分查找等等。 Append Only Data Structures 的一些存储系统比如HBase, Cassandra, RocksDB 1.Kafka存储难度 Kafka 通过简化消息模型,将自己退化成了一
-
 写给熟人的面试经验总结
写给熟人的面试经验总结主要是写给熟人看的,防定位,个人信息会写的模糊一些。以前通篇都是基于本人的一些理解,可能会略有一些主观。 背景 求职方向:后端开发 学历背景:985本+211硕 均非科班 战绩 今年比较狂,只面了10余家有名有姓的大公司,索性没有翻大车。 几个package在40w-65w,base在24k-35k的offer。(好吧其实直接拒了两个开的低的) 我大约是做出选择了,选的既不是package最大的,
-
 秋招的一波社招面经:蚂蚁金服、拼多多、字节跳动
秋招的一波社招面经:蚂蚁金服、拼多多、字节跳动蚂蚁金服 一面 算法题,给了长度为 N 的有重复元素的数组,要求输出第 10 大的数。 需要在 2 小时内完成。 二面 自我介绍 目前在部门做什么,业务简单介绍下,内部有哪些系统,作用和交互过程说下 Dubbo 踩过哪些坑,怎么解决的? 对线程安全的理解 乐观锁和悲观锁的区别? 这两种锁在 Java 和 MySQL 分别是怎么实现的? 事务有哪些特性? 怎么理解原子性? HashMap 为什么不是
-
 23届秋招 科大讯飞飞凡计划Java开发岗11.5笔试凉经
23届秋招 科大讯飞飞凡计划Java开发岗11.5笔试凉经笔试时间是11.5晚上七点到九点,由于实验没做完,我七点半才开始考试,感觉寄了。 题型:25道单选题,每题2分;3道编程题,分值分别为15、15、20分,总分100分。 选择题挺难的,考了很多Linux还有多线程的内容,我都没学过,寄了,还考了不少算概率期望的题目。 编程题: 第1题:问一个字符串是否是另一个字符串删减掉中间的部分得到。这题比较简单,遍历字符串就行,ac了。 第2题:问一个数组的完
-
C#设置窗体最大化且不遮挡任务栏的方法
本文向大家介绍C#设置窗体最大化且不遮挡任务栏的方法,包括了C#设置窗体最大化且不遮挡任务栏的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#设置窗体最大化且不遮挡任务栏的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的C#程序设计有所帮助。
-
Kafka消费群体将当前的抵消行为设置为最早?
我有一个kafka主题,有25个分区,集群已经运行了5个月。 根据我对给定主题的每个分区的理解,偏移量从0,1,2开始...(无界) 我看到log-end-offset值很高(现在- 我创建了一个新的消费群体,偏移设置为最早;因此,我预期该消费者组的客户端将从偏移量0开始的偏移量。 我用来创建一个偏移量为最早的新消费者组的命令: 我看到正在创建消费者组。我预计当前偏移量为0;然而,当我描述消费者组
-
数组公式计数每行单独计数
我尝试
-
弹性搜索计算膜压的公式
目前有几个Java服务我们想在上面添加监视/警报。 所以我们从JVM收集一些关于内存使用的信息,然后我们注意到ElasticSearch有一个叫做Memmory Pressure的“度量”,这听起来也很不错,可以用来计算那些Java服务。 问题是我一辈子都找不到它,我试着从他们的github repo中搜索代码中的内存/压力。 在搜索关于内存压力如何工作的公式或解释时,总是找到基本相同的两篇理解内
-
公式不会自动计算
我有一张大表,上面有很多公式,它们之间有一个依赖层次结构。它以具有日期值的单元格开始。然后,单元格x:y(和其他单元格)有依赖于该日期的公式。那么单元格w:z(和其他单元格)有一个依赖于单元格x:y的公式。诸如此类... 这个带有日期值的主单元格使用apache POI填充。 现在我的问题是:当我打开生成的excel文件时,日期在那里,但没有一个公式被计算出来。它们都存在错误“”。似乎当公式试图自
-
请针对你最喜欢的一位歌手或艺人设计一份采访提纲,不少于10个问题
本文向大家介绍请针对你最喜欢的一位歌手或艺人设计一份采访提纲,不少于10个问题相关面试题,主要包含被问及请针对你最喜欢的一位歌手或艺人设计一份采访提纲,不少于10个问题时的应答技巧和注意事项,需要的朋友参考一下 采访吴磊。 1.最近都在做些什么? 2.最近有拍什么戏吗? 3.你喜欢的女生需要具备什么条件呢? 4.你有想过几岁结婚吗? 5.你认为作为一个明星需要具备些什么? 6.最近有什么有趣的事情