《学习路径》专题
-
ASP.NET MVC学习教程之Razor语法
本文向大家介绍ASP.NET MVC学习教程之Razor语法,包括了ASP.NET MVC学习教程之Razor语法的使用技巧和注意事项,需要的朋友参考一下 前言 ASP.NET MVC 3配有一个新的名为“Razor”的视图引擎选项(除了已有的.aspx视图引擎)。Razor尽量减少编写一个视图模板需要敲入的字符数,实现快速流畅的编程工作流。与大部分模板的语法不同,你不必在HTML中为了明确地标记
-
 PyTorch学习笔记之回归实战
PyTorch学习笔记之回归实战本文向大家介绍PyTorch学习笔记之回归实战,包括了PyTorch学习笔记之回归实战的使用技巧和注意事项,需要的朋友参考一下 本文主要是用PyTorch来实现一个简单的回归任务。 编辑器:spyder 1.引入相应的包及生成伪数据 其中torch.linspace是为了生成连续间断的数据,第一个参数表示起点,第二个参数表示终点,第三个参数表示将这个区间分成平均几份,即生成几个数据。因为torch
-
神经网络无法学习异或
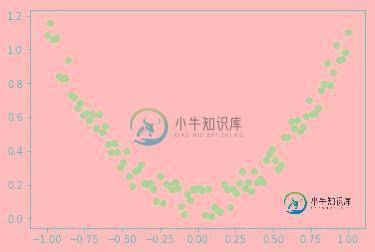
我创建了一个神经网络,其结构如下: Input1-Input2-输入层。 N0-N1-隐藏层。每个节点3个权重(一个用于偏移)。 N2——输出层。3个砝码(一个用于偏置)。 我正在尝试使用以下测试数据对其进行XOR函数训练: 0 1-期望结果:1 1 0-期望结果:1 0 0-所需结果:0 1 1-所需结果:0 训练后,测试的均方误差(当寻找1结果时){0,1}=0,我认为这很好。但是测试的均方误
-
 机器学习图像特征提取
机器学习图像特征提取在机器学习中,灰度图像的特征提取是一个难题。 我有一个灰色的图像,是用这个从彩色图像转换而来的。 我实际上需要从这张灰色图片中提取特征,因为下一部分将训练一个具有该特征的模型,以预测图像的彩色形式。 我们不能使用任何深度学习库 有一些方法,如快速筛选球。。。但我真的不知道如何才能为我的目标提取特征。 以上代码的输出就是真的。 有什么解决方案或想法吗?我该怎么办?
-
学习Android Java-应用程序失败
我一直在为Android开发尝试学习Java,所以我决定尝试做一个简单的转换器应用来学习。目前,我有一个简单的用户界面,我正在尝试将摄氏转换为华氏。转换器在工作时可在摄氏、华氏和开尔文之间转换。 当我单击应该运行计算方法的按钮时,我得到的错误是“不幸的是,转换器已经停止了。”下面是我的代码,我还包含了视图的XML。 查看XML代码: 有没有人能指出我哪里错了,我不知道。谢谢
-
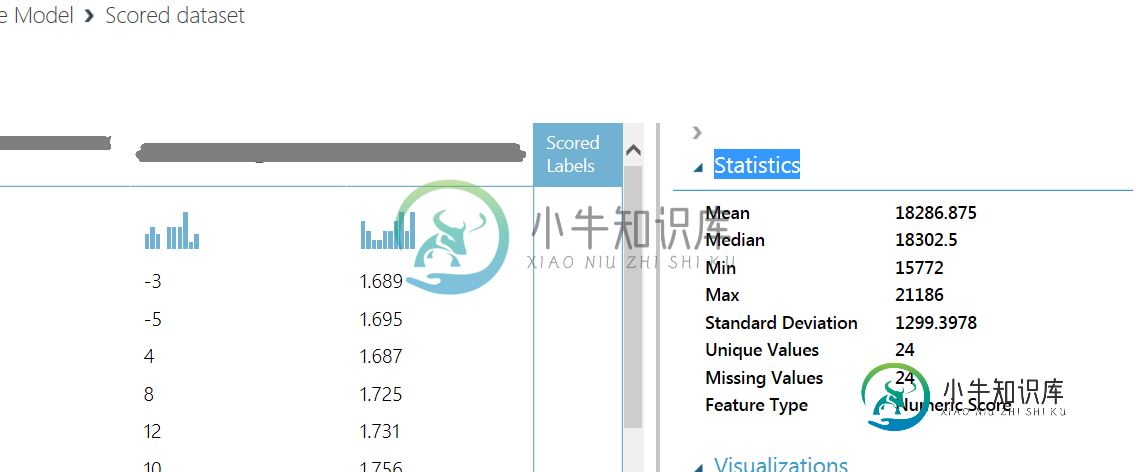 Azure机器学习-空分数结果
Azure机器学习-空分数结果我训练了一个模型,在测试集上的测试结果是可以的。现在,我已经将模型保存为“训练模型”,并将一个新的实验转化为一个新的数据集,以便在我没有实际值的情况下进行预测。 通常,训练过的模型给我一个每个实例的评分标签结果。但是现在,打分的标签结果是空的。另外,当我将得分结果转换为CSV时,得分标签列是空的。 更奇怪的是,当我查看score Visualize选项卡的统计数据时,我确实看到了得分值的统计数据。
-
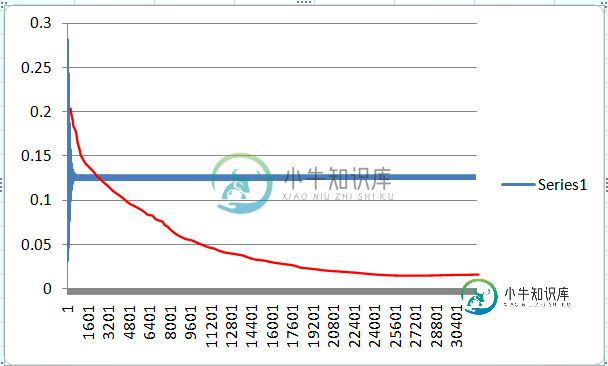 神经网络异或门不学习
神经网络异或门不学习我试图用两个感知器网络做一个异或门,但由于某种原因,网络没有学习,当我在图中绘制误差的变化时,误差达到一个静态水平,并在该区域振荡。 目前我没有给网络添加任何偏见。 这是错误随着学习轮数的变化而变化。这是正确的吗?红色线是我所期望的错误将如何改变的线。
-
支持向量回归在线学习
我正在用支持向量回归预测股票价格。我已经训练了一些价值,但当我预测的价值,每次我都必须训练的基础上(在线学习)。因此,我已经传递了这些值,以便在预测后在循环中进行训练。 那么,当我每次调用fit函数时,svr训练是如何基于一个输入在内部工作的呢?
-
深度学习南部损失原因
也许这是一个过于笼统的问题,但谁能解释什么会导致卷积神经网络发散? 规格: 我正在使用Tensorflow的iris_training模型和我自己的一些数据,并不断获得 错误:张量流:模型因损失=NaN而发散。 追踪。。。 tensor flow . contrib . learn . python . learn . monitors . nanlosduring training error:
-
强化学习(实践):REINFORCE,AC,TRPPO,PPO
随着收集到的轨迹越来越多,REINFORCE 算法有效地学习到了最优策略。不过,相比于前面的 DQN 算法,REINFORCE 算法使用了更多的序列,这是因为 REINFORCE 算法是一个在线策略算法,之前收集到的轨迹数据不会被再次利用。此外,REINFORCE 算法的性能也有一定程度的波动,这主要是因为每条采样轨迹的回报值波动比较大,这也是 REINFORCE 算法主要的不足。
-
机器学习:支持向量机(SVM)
支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面,可以将问题化为一个求解凸二次规划的问题。与逻辑回归和神经网络相比,支持向量机,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
-
机器学习:感知机算法(PLA)
感知机可以理解为几何中的线性方程:w*x+b=0 对应于特征空间 R^n 中的一个超平面 S ,其中 w 是超平面法向量,b 是超平面的截距。这个超平面将特征空间划分为两个部分。位于两部分的点(特征向量)分别被分为正、负两类。
-
第十八章 机器学习入门
入门文章 一文读懂机器学习,大数据/自然语言处理/算法全有了
-
8. 大数据与机器学习 - Tensorflow
Kubeflow 是 Google 发布的用于在 Kubernetes 集群中部署和管理 tensorflow 任务的框架。主要功能包括 用于管理 Jupyter 的 JupyterHub 服务 用于管理训练任务的 Tensorflow Training Controller 用于模型服务的 TF Serving 容器 部署 部署之前需要确保 一套部署好的 Kubernetes 集群或者 Mini
-
8. 大数据与机器学习 - Spark
Kubernetes 从 v1.8 开始支持原生的Apache Spark应用(需要Spark支持Kubernetes,比如v2.2.0-kubernetes-0.4.0),可以通过 spark-submit 命令直接提交Kubernetes任务。比如计算圆周率 bin/spark-submit --deploy-mode cluster --class org.apache.spark.