《大数据求职》专题
-
 联通数科 大数据开发
联通数科 大数据开发一面(11/3) 自我介绍 拷打项目 然后问了一个Flink反压的问题 二面(11/10) 自我介绍 拷打项目 问了前端展示大量数据,如何考虑?(可能大佬就是前端的) 问了用了哪些数据库? 问了Kafka 和 Flume 的应用场景? (可能时间比较紧张,所以问的比较急,二面没有遇到反问环节了)
-
求元素和/个数最大的子数组
O(n^2)算法简单。有没有人对此有更好的算法?
-
 快手数据研发一面(大数据、数仓、数开)
快手数据研发一面(大数据、数仓、数开)项目为sgg经典离线数仓 1. 自我介绍 2. 项目介绍(难点、亮点) 3. 根据难点亮点提问 4. 数据域是什么,如何划分数据域,为什么这样划分数据域 5. DIM层维度表的设计原则 6. DWD层事实表设计要点 7. mapreduce shuffle流程 8. maptask和reduce task 与哪些因素有关 9. 数据热点(数据倾斜)在哪些场景下出现,如何解决 10. spark是为
-
Java:如何优化大数组求和
问题1[主]:是否可以优化? 我尝试过:避免使用非常大的数字的操作。所以我决定使用辅助数据。例如,我将转换为,其中。 问题:但是似乎比快十倍。这里是我的测试:
-
javascript - 数组组装,求大佬指导?
我想要的结果:相同进度的不要叠加一起,让它往前走一格,第2个0%让它往前走+1变成1%,第3个0%让它往前走2格+2变成2%,若1%,2%已存在,在前面的基础2%,加+1,变成3%,4%,以此类推! 备注:一般只有0%和100%才会出现多个相同的,最多4个相同的数据
-
 大数据技术十大核心原理
大数据技术十大核心原理主要内容:1.数据核心原理:从“流程”核心转变为“数据”核心,2.数据价值原理:有功能是价值转变为数据是价值,3.全样本原理:从抽样转变为需要全部数据样本,4.关注效率原理:由关注精确度转变为关注效率,5.关注相关性原理:由因果关系转变为关注相关性,6.预测原理:从不能预测转变为可以预测,7.信息找人原理:从人找信息,转变为信息找人,8.机器懂人原理:由人懂机器转变为机器更懂人,9.电子商务智能原理:大数据改变了电子商务模式,让电子商务更智能,科学进步越来越多地由数据来推动,海量数据给数据分析既
-
 科大讯飞一面凉经 | 大数据
科大讯飞一面凉经 | 大数据一面 共 30min 自我介绍 实习经历介绍 项目介绍:数仓分层的理解 为什么用spark而不用hadoop 为什么spark比hadoop快 spark开始计算的标志 java抽象类和接口的区别 对继承和多态的理解 最近有想要学习的新技术吗 #科大讯飞##秋招##大数据#
-
 求中证数据数据技术岗面经😭
求中证数据数据技术岗面经😭#面经# #中证数据#
-
插入sql数据库时处理大量数据
问题内容: 在我的代码中,用户可以上传一个excel文档,希望其中包含电话联系人列表。作为开发人员,我应阅读excel文件,将其转换为dataTable并将其插入数据库。问题是某些客户拥有大量的联系人,例如说5000个和更多的联系人,而当我尝试将这种数据量插入数据库时,它崩溃了,并给了我一个超时异常。避免这种异常的最佳方法是什么?它们的任何代码都可以减少insert语句的时间,从而使用户不必等
-
将大量数据加载到Oracle SQL数据库
问题内容: 我想知道是否有人对我即将从事的工作有任何经验。我有几个csv文件,它们的大小都在一个GB左右,我需要将它们加载到oracle数据库中。虽然加载后我的大部分工作都是只读的,但我仍需要不时加载更新。基本上,我只需要一个很好的工具即可一次将多行数据加载到数据库中。 到目前为止,这是我发现的内容: 我可以使用SQL Loader来完成很多工作 我可以使用批量插入命令 某种批量插入。 以某种方式
-
根据数组的值求和
问题内容: 我有未排序的索引数组: 我也有一个相同长度的值数组: 我有期望值为零的数组: 现在,我想根据v在d中的索引将其添加到元素中。 如果我用普通的python做,我会这样: 这是丑陋且效率低下的。我该如何更改? 问题答案: 我们可以使用据称对这种累积加权计数非常有效的方法,所以这里有一个- 或者,使用输入参数,对于一般情况,当可以是任何数组,而我们想添加到该数组中时, 运行时测试 本节将本文
-
param数据的Python请求Post
这是对API调用的原始请求: 此请求返回成功(2xx)响应。 现在,我正尝试使用发布此请求: 对我来说一切都很好,我不太确定我发布了什么错误来获得400回复。
-
存储齐射请求数据
我是一个人开始的,研究了很多,但没有发现任何与这个简单的问题。 不管怎么都要谢谢您!
-
了解TCP数据包大小限制和UDP数据包大小限制
我正在使用在我的客户端应用程序中执行以及 最大数据包大小限制也存在于中,即?但是我可以使用中的发送大于最大数据包大小的数据块 这是怎么运作的?这是因为是基于流的,负责在较低层创建数据包吗?有什么方法可以增加UDP中的最大数据包大小吗? 当我在客户端读取时,我从服务器端发送的UDP数据包的一些字节是否可能丢失?如果是,那么有没有办法只检测UDP客户端的损失?
-
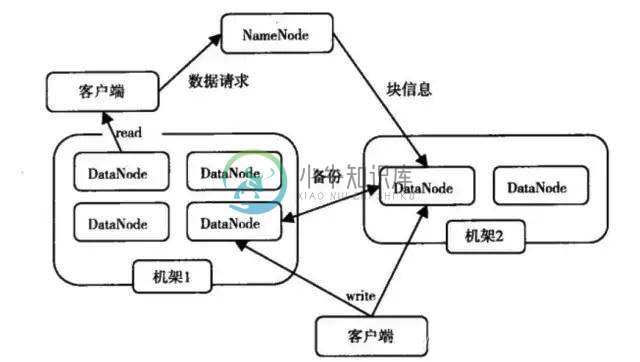
 上海银行大数据开发(数仓)数据一面
上海银行大数据开发(数仓)数据一面离线数仓项目介绍 hdfs读流程 hdfs 中datanode怎么与namenode交互 mr过程 hive数据倾斜,介绍原因和解决方案 介绍一下网络结构,tcp在哪一层 java有哪些集合类 介绍java接口 MySQL索引 数据结构(B+树) 反问 上海银行数仓技术框架