《大数据求职》专题
-
3. 请求数据获取 - 3.1 GET请求数据获取
使用方法 在koa中,获取GET请求数据源头是koa中request对象中的query方法或querystring方法,query返回是格式化好的参数对象,querystring返回的是请求字符串,由于ctx对request的API有直接引用的方式,所以获取GET请求数据有两个途径。 1.是从上下文中直接获取 请求对象ctx.query,返回如 { a:1, b:2 } 请求字符串 ctx.que
-
如何在大型数据集中求全局平均值?
我正在编写简单的mapreduce程序来查找我的数据(许多文本文件)中存在的平均值,最小数字和最大数字。我想使用组合器首先在单个映射器处理的数字中查找所需的内容会使其更有效率。 然而,我关心的事实是,为了能够找到平均、最小数或最大数,我们将要求来自所有映射器(因此所有组合器)的数据进入单个缩减器,以便我们能够找到通用平均、最小数或最大数。这在较大数据集的情况下将是一个巨大的瓶颈。 我相信在hado
-
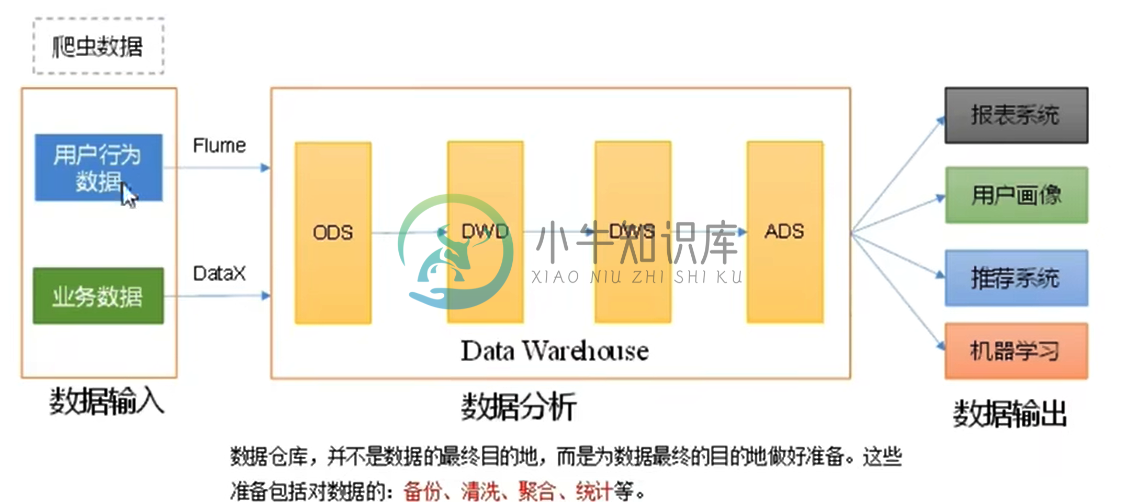 大数据平台之数据存储
大数据平台之数据存储主要内容:1.大数据生态技术,2.数据存储,3.数据存储的发展,4.数据存储的方式1.大数据生态技术 数据存储处理: 清洗, 关联, 规范化, 组织建模, 通过数据质量的检测, 数据分析然后提供相应的数据服务 离线数仓: 实时数仓: 以Kafka, cancal/Maxwell/FlinkCdc为区分, 离线数仓为Hive, Sqoop 实时数仓:分层: Ods, Dwd, Dim, Dwm, Dws, Ads 离线数仓分层: Ods. Dwd, Dws, Dwt, Ads 实
-
请求数据编码
目前,许多浏览器不随着 Content-Type 头一起发送字符编码限定符,而是根据读取 HTTP 请求确定字符编码。如果客户端请求没有指定请求默认的字符编码,容器用来创建请求读取器和解析 POST 数据的编码必须是“ISO-8859-1”。然而,为了向开发人员说明客户端没有指定请求默认的字符编码,在这种情况下,客户端发送字符编码失败,容器从getCharacterEncoding 方法返回 nu
-
pandas数据框的最大大小
问题内容: 我试图使用s或函数读取稍大的数据集,但我一直遇到s。数据框的最大大小是多少?我的理解是,只要数据适合内存,数据帧就应该可以,这对我来说不是问题。还有什么可能导致内存错误? 就上下文而言,我试图在《2007年消费者金融调查》中阅读ASCII格式(使用)和Stata格式(使用)。该文件的dta大小约为200MB,而ASCII的大小约为1.2GB,在Stata中打开该文件将告诉我,对于22,
-
 科大讯飞大数据一面
科大讯飞大数据一面#科大讯飞求职进展汇总##春招# 面试官人很好,还挺帅(有点像shy哥? 全程拷打简历,会重点问实习和2个左右项目 本来我在不断引导面试官问我数据库和机器学习方面的内容,但是面试官好像不怎么想问,连数据怎么清洗的这种都没问,就问了聚类了解那些?k-means聚类怎么优化?肘部法则和肘部加速的区别? 由于我项目大都是deep learning方向的,所以都在让我讲dl方向的东西 还有就是项目遇到了哪
-
用于管理api每分钟最大请求数的数据结构
我需要向一个外部api发送数据,但是这个API对每个endpoint的请求有一个限制(即:每分钟60个请求)。 数据来自 Kafka,然后每条消息都会转到 redis(因为我可以发送包含 200 个项目的请求)。因此,我使用简单的缓存来帮助我,我可以保证如果我的服务器出现故障,我不会丢失任何消息。 问题是,有些时候,Kafka开始向许多消息发送消息,然后redis开始增长(超过100万条消息发送到
-
大数据增量PCA
问题内容: 我只是尝试使用sklearn.decomposition中的IncrementalPCA,但它像以前的PCA和RandomizedPCA一样引发了MemoryError。我的问题是,我要加载的矩阵太大,无法放入RAM。现在,它以形状〜(1000000,1000)的数据集形式存储在hdf5数据库中,因此我有1.000.000.000 float32值。我以为IncrementalPCA可
-
大数据集的TFIDF
问题内容: 我有一个大约有800万条新闻文章的语料库,我需要以稀疏矩阵的形式获取它们的TFIDF表示形式。我已经能够使用scikit-learn来实现相对较少的样本数量,但是我相信它不能用于如此庞大的数据集,因为它首先将输入矩阵加载到内存中,这是一个昂贵的过程。 谁知道,对于大型数据集,提取TFIDF向量的最佳方法是什么? 问题答案: Gensim具有高效的tf-idf模型,不需要一次将所有内容存
-
大数据多处理
问题内容: 我用来并行化一些繁重的计算。 目标函数返回大量数据(庞大的列表)。我的RAM用完了。 如果不使用,我只需将生成的元素依次计算出来,就将目标函数更改为生成器。 我了解多处理不支持生成器- 它等待整个输出并立即返回,对吗?没有屈服。有没有一种方法可以使工作人员在数据可用时立即产生数据,而无需在RAM中构造整个结果数组? 简单的例子: 这是Python 2.7。 问题答案: 这听起来像是队列
-
1.5.3.2.16 大数据分析
SuperMap iClient for Leaflet 对接了 SuperMap iServer 的分布式分析服务,为用户提供大数据分析功能,主要包括: 密度分析 点聚合分析 单对象空间查询分析 区域汇总分析 矢量裁剪分析
-
编写大型数据
由于网络的原因,如何有效的写大数据在异步框架是一个特殊的问题。因为写操作是非阻塞的,即便是在数据不能写出时,只是通知 ChannelFuture 完成了。当这种情况发生时,你必须停止写操作或面临内存耗尽的风险。所以写时,会产生大量的数据,我们需要做好准备来处理的这种情况下的缓慢的连接远端导致延迟释放内存的问题你。作为一个例子让我们考虑写一个文件的内容到网络。 在我们的讨论传输(见4.2节)时,我们
-
 10.24京东大数据
10.24京东大数据1.自我介绍 2.大数据项目battle 3.对于窗口函数的了解 有什么,什么场景,怎么用 4.文本拼接函数是什么 5.hbase负载均衡怎么实现 6.cv项目battle 不同模型的区别 网络+部署 7.反问 京东商城核心检索业务 和leader讨论面试结果,一周内hr会联系
-
 soul大数据面经
soul大数据面经1.自我介绍 2.你的优势是什么 3.对数仓怎么看 4.sql,有id,score。怎么实现按score排序并且要排名,不能使用开窗函数。
-
 tplink大数据开发
tplink大数据开发6.27一面 20min 问简历,介绍项目提到的各种模型,做了什么优化 有没有spark实践的经历 介绍一下hadoop 了解哪些机器学习算法 xgboost和随机森林的区别 有用Java做过项目吗(无...) 反问 6.28二面 35min 简历项目一个一个详细讲 transformer编码器解码器区别 transformer位置编码的情况 spark实践经历 反问