《数据分析工程师》专题
-
将JSON解析为数据结构
我正在尝试将上面的JSON解析为数据结构。我最初使用Gson,但大多数解决方案建议创建一个反映我的Gson结构的类结构并使用fromJson(String, Class),但我不想这样做,因为JSON的结构可能会改变,我不想每次都格式化我的类。
-
Android改造无法解析数据
无法解析以下json数据。获得成功响应但返回的正文为空以下是我通过Web浏览器获得的json响应。 下面是用于解析所用响应类的模型类 Departure.java 调用api 我从浏览器中得到了正确的响应。但当通过改装库调用时,获得成功响应(200),但正文为空。 我从浏览器中得到了正确的响应。但当通过改装库调用时,获得成功响应(200),但正文为空。
-
如何使用REGEXP_SUBSTR解析数据?
问题内容: 我有一个这样的数据集(请参见下文),我尝试提取以下形式的数字:{variable_number_of_digits} {hyphen} {only_one_digit}: 我没有得到正确的结果集,应为以下内容 如何实现呢? 问题答案: 如果要从第二个和第三个定界的组中获取结果,则: 输出 : 更新 : 如果只希望第一个和第二个模式匹配,并且不在乎它们在字符串中的位置,则: 输出 :
-
php解析xml格式的数据
我试图解析通过api调用获取的xml数据。我可以使用file\u get\u内容来读取字符串,但simpleXML\u load\u字符串似乎无法读取它。我可以将它保存到一个文件中,然后simpleXML\u load\u文件工作。但我宁愿不把内容写入文件。我似乎也不明白如何使用DOM或XMLParse。我不熟悉PHP和解析XML。api调用的输出数据如下所示。 我发现问题在于我在浏览器中看到的实
-
Spring Boot:最初是数据解析
我正在寻找一种方法,在spring boot应用程序启动时读取和解析大量数据,并能够在以后的其他类中使用这些数据。 我从一个类开始,并用对它进行了注释,以便以后能够注入它。我计划读取这里的数据,并将其注入到任何其他需要数据的类中。 但如何才能实现只在应用程序启动时解析一次数据呢?spring boot应用程序应该只有在解析完成的情况下才可访问。
-
修改2解析传出数据
你好StackOverflow的伙计们!这是我的第一个帖子,真的是我的大问题与改造2,我希望一些人帮助解决。 这是我的接口类: 和apimanager类: 我以这种方式使用代码: 最后,我的HttpLoggingInterceptor显示,我在restApi中找不到什么和如何解析它 我找不到从restApi改版2.1.0到restApi的内容,以及哪一部分是我的字符串或图像数据?我确实根据stac
-
1.6.4 云端数据解析脚本
更新时间:2018-09-15 13:44:21 概述 本章节主要针对采用透传/自定义格式上报数据的设备,您如果使用了Alink协议可以跳过,可以直接参考 Alink 协议文档完成设备端的开发和接入,无需编辑数据解析脚本。 Link Develop开发平台为开发者提供了用于数据解析的在线脚本编辑器,方便您进行在线的编辑和模拟调试。 数据解析流程: 数据解析将为您提供: 脚本在线编辑器,支持 Jav
-
标准TVL格式数据解析
TLV格式数据解析。 什么是TLV数据?传送门:http://blog.csdn.net/chexlong/article/details/6974201 在标准的TLV数据解析过程中会遇到很多问题。在目前的开源的C/C 的项目中代码十分的庞大,整合起来十分不方便并没有OC的代码,故作者封装了这个类库供需要使用TLV格式数据的同学们学习使用。 [Code4App.com]
-
Azure数据工厂v2复制数据活动递归
我是新的Azure数据工厂v2 我有一个文件夹,里面有两个文件。csv和F2。在blob存储中存储csv。 我创建了一个复制数据管道活动,用3个参数将数据从文件加载到azure DWH中的一个表中,并将其递归复制为false。 参数1:容器 参数2:目录 参数3:F1.csv 将上述参数用于复制数据活动时成功执行。 但数据是从两个文件加载的,只有一个文件作为活动的参数提供
-
python实现的分析并统计nginx日志数据功能示例
本文向大家介绍python实现的分析并统计nginx日志数据功能示例,包括了python实现的分析并统计nginx日志数据功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python实现的分析并统计nginx日志数据功能。分享给大家供大家参考,具体如下: 利用python脚本分析nginx日志内容,默认统计ip、访问url、状态,可以通过修改脚本统计分析其他字段。 一、脚本运行方式
-
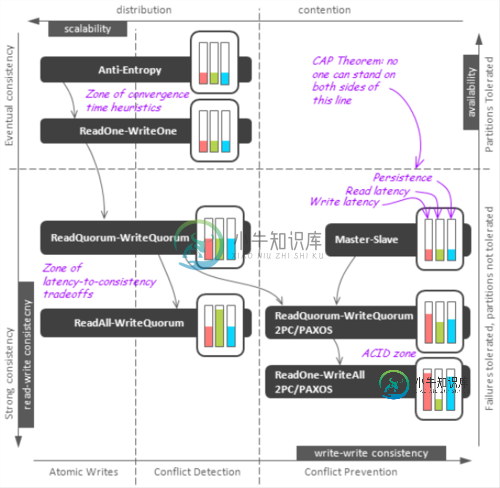 深入解析NoSQL数据库的分布式算法(图文详解)
深入解析NoSQL数据库的分布式算法(图文详解)本文向大家介绍深入解析NoSQL数据库的分布式算法(图文详解),包括了深入解析NoSQL数据库的分布式算法(图文详解)的使用技巧和注意事项,需要的朋友参考一下 尽管NoSQL运动并没有给分布式数据处理带来根本性的技术变革,但是依然引发了铺天盖地的关于各种协议和算法的研究以及实践。在这篇文章里,我将针对NoSQL数据库的分布式特点进行一些系统化的描述。 系统的可扩展性是推动NoSQL运动发展的的主要
-
IC角色,用于创建物理表,分析SAP HANA中的数据
本文向大家介绍IC角色,用于创建物理表,分析SAP HANA中的数据,包括了IC角色,用于创建物理表,分析SAP HANA中的数据的使用技巧和注意事项,需要的朋友参考一下 要创建物理表,需要上传数据并创建信息视图IC_MODELER角色。如果仅为这些用户分配IC_PUBLIC角色,则他们可以查看其他用户创建的信息视图,但不能创建自己的视图。
-
将聚类分析结果转换为数据。R中的帧格式
这篇文章来自于这个主题,使用R对单词中的相同模式进行分类。解决方案很好,但是我需要数据帧格式。数据是相同的 我们来进行聚类分析 代码完成后,如何将结果转换为data.frame? 预期产出 s=as。数据(函数(…,row.names=NULL,check.rows=FALSE,check.names=TRUE)中的frame(拆分(文本,集群))错误:参数表示行数不同:7,1,2 所以理想的输出
-
用Java进化生物学库(JEBL)分析数据注释树节点
我使用JEBL和跌跌撞撞的API,因为我找不到非常清晰的留档或示例。 我想做的是在一棵树上阅读,树上的树枝标注了长度,节点也标注了长度。然后,我应该能够获取树叶并向上遍历树,同时检查节点的注释(使用JEBL遍历很容易,我的问题实际上是注释)。 它们是系统发育树,其中每个节点都是一个物种,注释将标记特定节点上是否存在某些基因,并且可能有足够少的基因,一个字符串就足够了(例如,如果有三个基因a、B和C
-
 脉脉数据分析实习生面经+入职体验(内推DD)
脉脉数据分析实习生面经+入职体验(内推DD)1.一面前的笔试题: 在通过简历筛选后,会有hr通过邮件以pdf的形式发送sql笔试题目进行作答,分为初级中级和高级三个等级,在每一个等级中挑一到题目作答,会给一到两张用户活跃表,根据需求求取dau等相应指标。(题目比较基础) 2.一面: 在通过笔试之后,hr会通过邮件发送飞书面试邀约,一面的面试官是入职后的mentor。在开始面试之前,面试官要求在线手写两道sql笔试题目,给半小时的时间,以pd