《数分面经》专题
-
 得物L【95分】商业分析师面试0221~
得物L【95分】商业分析师面试0221~今年第三家面试公司是得物旗下的95分商业分析师。现在看录音回放,感觉当时的回答好糟糕啊!!! 面试得物的是一个超级无敌温柔的商业分析师。感觉就像是小姐姐一样亲切一直引导你,但我还是经验尚浅。准备的不够充分吧。 开头一贯都是先让做自我介绍。 然后接下来就问我目前所在位置+实习能够实习多久之类的问题。 接下来就是扔给我之前HR发我的两道题,一道是有关费米估算问题的求解,另一道是SQL题。 费米估算问题
-
素数分解-列表
问题内容: 我正在尝试实现一个函数,该函数将正整数作为输入并返回包含的素数分解中所有数字的列表。 我已经走了这么远,但我认为最好在这里使用递归,不确定如何在这里创建递归代码,基本情况是什么?首先。 我的代码: 问题答案: 一个简单的审判部门: 具有复杂性(最坏的情况)。您可以通过特殊情况2并仅在奇数上循环(或特殊情况下将更多小质数并在可能的除数上循环)来轻松改进它。
-
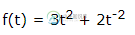 Matlab微分和导数
Matlab微分和导数主要内容:基本微分规则的验证,指数,对数和三角函数的导数,计算高阶导数,查找曲线的最大和最小值,求解微分方程MATLAB提供用于计算符号导数的命令。 以最简单的形式,将要微分的功能传递给命令作为参数。 例如,计算函数的导数的方程式 - 例子 创建脚本文件并在其中键入以下代码 - 执行上面示例代码,得到以下结果 - 以下是使用Octave 计算的写法 - 执行上面示例代码,得到以下结果 - 基本微分规则的验证 下面简要说明微分规则的各种方程或规则,并验证这些规则。 为此,我们将写一个第一阶导数和二
-
SQLite 分离数据库
主要内容:语法,实例SQLite 的 DETACH DATABASE 语句是用来把命名数据库从一个数据库连接分离和游离出来,连接是之前使用 ATTACH 语句附加的。如果同一个数据库文件已经被附加上多个别名,DETACH 命令将只断开给定名称的连接,而其余的仍然有效。您无法分离 main 或 temp 数据库。 如果数据库是在内存中或者是临时数据库,则该数据库将被摧毁,且内容将会丢失。 语法 SQLite 的 DET
-
SQL Server数据分组
SQL Server中分组查询通常用于配合聚合函数,实现分类汇总统计的信息。而其分类汇总的本质实际上就是先将信息排序,排序后相同类别的信息会聚在一起,然后通过需求进行统计计算。 SQL Server中常用的数据分组相关查询如下: GROUP BY - 根据指定列表达式列表中的值对查询结果进行分组。 HAVING - 指定组或聚合的搜索条件。 GROUPING SETS - 生成多个分组集。 CUB
-
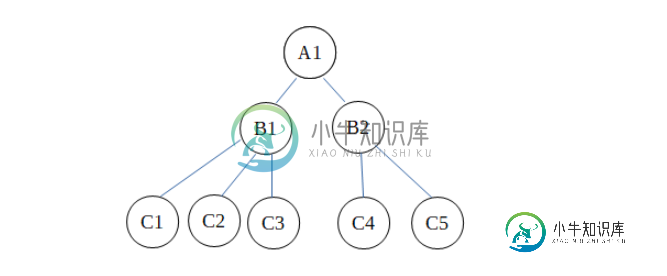 分层数据模型
分层数据模型本文向大家介绍分层数据模型,包括了分层数据模型的使用技巧和注意事项,需要的朋友参考一下 分层数据模型是最早的数据模型之一。该模型是基于文件的模型构建,就像树一样。在此树中,父节点可以与多个子节点关联,但是一个子节点只能有一个父节点。 对于目录和文件,可以说单个目录进一步包含多个文件或目录,然后这些目录包含更多文件,依此类推。 这可以表示为- 示例 使用关系数据库的层次模型的示例如下- <员工> E
-
Fortran 可分配数组
本文向大家介绍Fortran 可分配数组,包括了Fortran 可分配数组的使用技巧和注意事项,需要的朋友参考一下 示例 数组可以具有可分配的属性: 这将声明变量,但不会为其分配任何空间。 一旦不再需要一个变量,就可以释放它: 如果由于某种原因allocate语句失败,程序将停止。如果通过stat关键字检查状态,可以防止这种情况: 该deallocate语句也具有stat关键字: status 是
-
Django ForeignKey数据分组
Django ForeignKey需要分组 我想列出所有的记者和他们的所有文章显示以下格式。怎么可能呢?
-
分治返回数组
我最近正在学习分而治之算法。 如果返回值假定为某个整数,我就能够解决这些问题。 例如:1。二进制搜索,这里我只需要返回1如果找到,否则-1。 例:2。数组中的最大数,只需返回一个数字。 但是当涉及到返回一个数组时,就像我们需要整个数组作为输出(Ex:排序)。 我觉得很难。 有人能帮你找到最好的方法吗? 下面是我的二进制搜索方法。
-
Cassandra:低基数分区
假设我有一张桌子,像这样: 这遵循了所需的Cassandra模式,跨分区分布良好(假设默认的Murmur3哈希分区器)。 但是,我也需要(很少)按时间顺序执行范围查询。这在Cassandra中似乎是不可能的。实际上,我确实需要按组访问数据,所以是可以接受的。由于似乎没有办法让辅助索引有多个列,我想正确的做法是将其反规范化,如下所示: 除了< code>group基数很低,比方说< code>('A
-
Spring数据mongo分页
我想用Spring Data Mongo实现分页。有很多教程和文档建议使用PagingAndSorting Repository,如下所示: 因此,因为PagingAndSorting Repository提供了用于分页查询的api,我可以像这样使用它: 我的问题是这里的findAll方法实际上是在哪里实现的?我需要自己编写它的实现吗?实现StoryRepo的StoryRepoImpl需要实现这个
-
1.5.3.2.16 大数据分析
SuperMap iClient for Leaflet 对接了 SuperMap iServer 的分布式分析服务,为用户提供大数据分析功能,主要包括: 密度分析 点聚合分析 单对象空间查询分析 区域汇总分析 矢量裁剪分析
-
WinPcap: 分析数据包
现在,我们可以捕捉并过滤网络流量了,那就让我们学以致用,来做一个简单使用的程序吧。 在本讲中,我们将会利用上一讲的一些代码,来建立一个更实用的程序。 本程序的主要目标是展示如何解析所捕获的数据包的协议首部。这个程序可以称为UDPdump,打印一些网络上传输的UDP数据的信息。 我们选择分析和现实UDP协议而不是TCP等其它协议,是因为它比其它的协议更简单,作为一个入门程序范例,是很不错的选择。让我
-
如何分析数据
当你检查一个商业活动并且发现了把它转换为软件应用程序的需求时,数据分析是软件开发早期的一个过程。这是一个官方的定义,当你,一个程序员,应该集中注意力在写别人设计的东西的代码时,这可能会让你相信数据分析是一种更应该归入系统分析的行为。如果我们严格遵循软件工程范式,这可能是正确的。有经验的程序员会成为设计者,最尖锐的设计者变成商业分析师,因此被冠名去思考所有数据需要,并且给你充分定义的任务去执行。这不
-
分组数字(Grouping Digits)
使用DecimalFormat的setGroupingSize()方法,可以更改默认的数字分组。 以下示例说明了相同的内容。 IOTester.java import java.text.DecimalFormat; public class I18NTester { public static void main(String[] args) { double number =