
分层数据模型

分层数据模型是最早的数据模型之一。该模型是基于文件的模型构建,就像树一样。在此树中,父节点可以与多个子节点关联,但是一个子节点只能有一个父节点。
对于目录和文件,可以说单个目录进一步包含多个文件或目录,然后这些目录包含更多文件,依此类推。
这可以表示为-
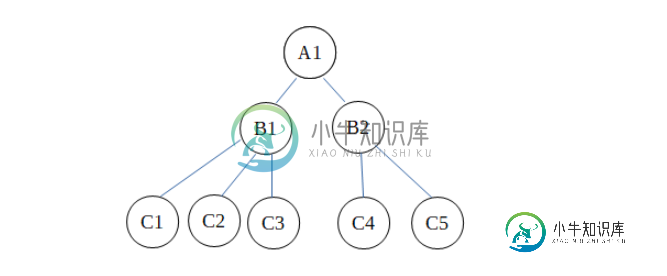
示例
使用关系数据库的层次模型的示例如下-
<员工>
| Emp_Number |
Emp_Name |
Emp_Designation |
Emp_Salary |
| 1 |
布拉德 |
作家 |
60000 |
| 2 |
汤姆 |
软件工程师 |
15000 |
| 3 |
凯文 |
秘书 |
70000 |
<计算机>
| 序列号 |
类型 |
Emp_Number |
| A100001 |
个人电脑 |
1 |
| 930 |
个人电脑 |
2 |
| C101703 |
个人电脑 |
3 |
在上面给出的示例中,Employee表是父表,而Computer表是子表。计算机表指向雇员表,因为它指定哪个雇员正在使用哪台计算机。
层次模型的缺点
- list-paddingleft-2">
在分层模型中,一对一关系可以轻松显示,因为一个父节点具有多个子节点。但是使用这种模型显示多对多关系要复杂得多。
层次模型是僵化的,不是很灵活。如果需要将另一个节点或关系添加到模型中,则可能会破坏整个现有结构。
-
问题内容: 我有一个与父子关系的表,我需要递归查询的帮助 表结构 我正在尝试进行递归查询,但是我无法做到这一点,建议我应该如何查询数据库 问题答案: 正如上面所指出的,这并不是真正的递归,但是如果您知道最大需要深入多少步,则可以沿以下方向使用某些方法(也许使用PHP生成查询): 我首先将父ID设置为NULL而不是0,但这是个人喜好。 ^^在这种情况下,您需要走多远。 [ 下一点没有严格意义 ] 然
-
我是反应式编程的新手。我必须开发一个简单的Spring启动应用程序来返回一个json响应,其中包含公司及其所有子公司和员工的详细信息 创建了一个Spring Boot应用程序(Spring Webflow Spring data r2dbc) 使用以下数据库表来表示公司和子公司以及员工关系(这是一种与公司和子公司的层次关系,其中一个公司可以有N个子公司,而这些子公司中的每个子公司可以有另N个子公司
-
模块可以分配到文件/目录的层次结构中。让我们将可见性小节例子 的代码拆开分到多个文件中: $ tree . . |-- my | |-- inaccessible.rs | |-- mod.rs | `-- nested.rs `-- split.rs 在 split.rs 文件: // 此声明将会查找名为 `my.rs` 或 `my/mod.rs` 的文件,并将该文件的内容插入到 /
-
我知道可能的性能问题,但是我们可以使用Hibernate/JPA映射类似的东西吗?
-
我在Spark(v2.1.1)中有一个数据集,其中有3列(如下所示)包含分层数据。 我的目标是根据父子层次结构为每一行分配增量编号。从图形上可以说,分层数据是树的集合 根据下表,我已经根据“Global_ID”对行进行了分组。现在,我想以增量顺序生成“值”列,但基于“父”列和“子”列的数据层次结构 表格表示(值是所需的输出): 树形表示(每个节点旁边都显示了所需的值): 代码片段: 经过大量研究并
-
开发手册的这一部分关注于中间层开发,并明确描述了这一层的数据访问职责。 先是,详细阐述了Spring全面的事务管理支持,随后,详细说明了Spring Framework如何支持多种中间层数据访问的框架和技术。 第 10 章 事务管理 第 11 章 DAO支持 第 12 章 使用JDBC进行数据访问 第 13 章 使用ORM工具进行数据访问 目录 10. 事务管理 10.1. 简介 10.2. 动机