《数据分析面试》专题
-
入口页面提供的信息及价值分析
使用指南 - 数据报告 - 访问分析 - 入口页面提供的信息及价值分析 入口页面,也称为着陆页(Landing page),是从外部(访客点击您站外广告、搜索结果页链接或者其他网站上的链接)访问到您网站的第一个入口,即每个访问的第一个受访页面。在入口页面报告中,您可以重点从流量质量、新访客和转化三个维度进行分析。其中流量质量分析:重点考量访问次数、访客数、跳出率、平均访问时长、平均访问页数和贡献浏
-
 人保科技-需求分析师终面(已通过)
人保科技-需求分析师终面(已通过)之前人保一面的时候,是在2023年1月份进行的,是过年的一到两周前。二面通知在过年后,一对四面试。一位面试主持人,三位面试官,均为男士,仅有两位提出询问。 面试时长约为20分钟左右,时间较为久远,只记得印象比较深刻的点。 简短自我介绍,内容要准备好。 第一位面试官,根据简历内容问了一些大致的问题,并没有过多深挖。主要围绕需求分析的逻辑,自我理解,相关概念进行询问。比如,怎么理解需求,如何提取需求,
-
 快手国际化数分面经(HR面挂)
快手国际化数分面经(HR面挂)bg:211本+qs50水硕 大中小厂实习各一段 kaggle银 3月投递。。5月被捞。。两周走完面试流程 三轮业务面+一轮交叉面+HR面 HR面秒挂 第一轮 1h 先SQL现场笔试三道题 1.自我介绍 2.实习项目经历 3.t检验 z检验 区别及应用 4.业务场景题 指标异动 要评估视频质量,怎么搭建指标体系 5.英语能力(接下来英语对话10分钟,太突然了,回答的不是很好) 6.反问 第二轮 4
-
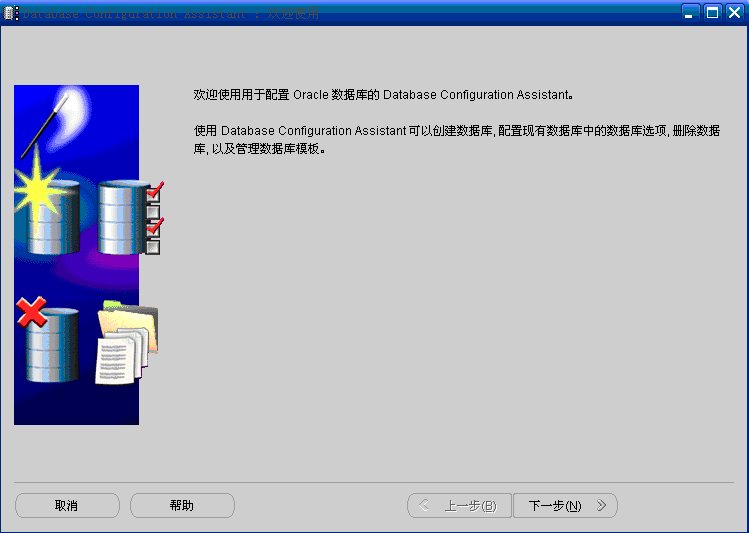 深入浅析Oracle数据库管理之创建和删除数据库
深入浅析Oracle数据库管理之创建和删除数据库本文向大家介绍深入浅析Oracle数据库管理之创建和删除数据库,包括了深入浅析Oracle数据库管理之创建和删除数据库的使用技巧和注意事项,需要的朋友参考一下 Oracle数据库的数据文件(扩展名为DBF的文件)是用于保存数据库中数据的文件,系统数据、数据字典数据、临时数据、索引数据、应用数据等都物理地存储在数据文件中。用户对数据库中数据的操作,例如数据的插入、删除、修改和查询等,其本质都是对数据
-
Mongo分片不删除源分片中分片集合的数据
我在5台机器上安装了MongoDB 3.2.6,这些机器都形成了由2个碎片组成的碎片集群(每个碎片都是具有主次仲裁器配置的副本集)。 我还有一个数据库,其中包含非常大的集合(约50M记录,200GB),它是通过mongos导入的,mongos将其与其他集合一起放入主分片。 我在该集合上生成了散列ID,这将是我的分片密钥。 在thay之后,我用: 命令返回: 它开始碎裂。碎片的状态如下所示: 这一切
-
 中行数字资产运营中心 数据运营岗 秋招面经分享
中行数字资产运营中心 数据运营岗 秋招面经分享面试:群面+结构(都是线上面试,是用腾讯会议进行面试) 群面:应该算是剧本杀,反正就是某个地方有人die了,然后n个嫌疑人,m条线索。最后汇报是组内统一意见选出嫌疑人,以及最多3条还需要搜索的线索。 读题10分钟,讨论+汇报 30min,没有个人陈述。 结构化:就像是政府岗结构化面试,按照编号一个个进入面试间,有两个部分,一个是情景题和一个专业题 情景题是: 1.列举一个用专业知识说服对方的事例
-
句子级到文档级的情感分析。新闻分析
我需要使用斯坦福NLP工具对关于特定主题的新闻文章进行情感分析。 这样的工具只允许基于句子的情感分析,而我想提取关于我的主题的整个文章的情感评价。 例如,如果我的主题是苹果,我想知道关于苹果的新闻文章的观点。 另一方面,将我的句子过滤到只包含Apple这个词的句子中,会遗漏类似“Apple的产品A很好。但是,它缺乏以下关键功能:...”的文章。在这种情况下,如果我只使用包含Apple这个词的句子,
-
第9章 案例分析:图像聚类 - 9.4 性能分析
为了展示不同的内核实现对于性能的影响,我们将这些内核都在Radeon HD 7970 GPU上执行了一遍。为了展示对不同数据大小的性能优化,我们也生成除了对应的SURF描述符和集群质心。生成的SURF描述符数量为4096,16384和65536。同时,对应质心的数量为16,64和256。我们选取数量较大的SURF特征,是因为对于一张高分辨率的图来说,通常都包含成千上万个特征。不过,对于质心来说其数
-
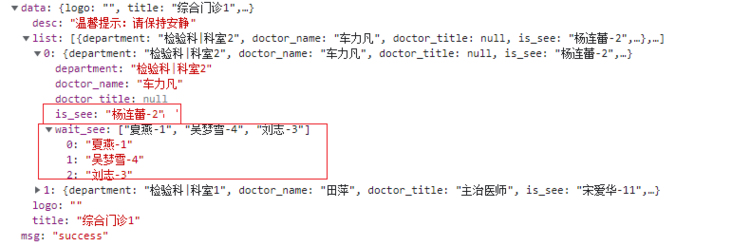 javascript - 怎么把后端返回的数据名字和数字分开,并分别渲染到页面上?
javascript - 怎么把后端返回的数据名字和数字分开,并分别渲染到页面上?这个是后端返回的数据,想把is_see和wait_see数据里面的名字和数字分开,然后分别把名字和数字渲染到页面上 这个是dom做遍历渲染 请问这个问题该怎么去弄呢?
-
jQuery根据name属性进行查找的用法分析
本文向大家介绍jQuery根据name属性进行查找的用法分析,包括了jQuery根据name属性进行查找的用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了jQuery根据name属性进行查找的用法。分享给大家供大家参考,具体如下: 例如:$(":input[name='login']") 表示查找的是name为login的表单 更多关于jQuery相关内容感兴趣的读者可查看本站专题
-
 沐瞳科技数分一面(moba)
沐瞳科技数分一面(moba)总评:整体面试难度对我来说还是比较大的,主要是因为对于游戏业务不熟悉,之前接触的更多是广告变现和电商业务。问了很多moba相关游戏细节,关于用户体验方向,确实了解比较少,还得多弥补下。 一、简历深耕: 1. 关联规则挖掘项目的背景,结果详细说下? 算法支持度和置信度阈值如何设定的? 2. 建立用户转化分类模型怎么选取特征的?承接策略有哪些? 3. 选
-
 3.7富途数分实习面经
3.7富途数分实习面经1. 自我介绍 2. 详细说一下实习,讲讲做了什么项目得到什么成果 3. 讲讲简历里面的abtest课程项目 4. 考了sql,概率,指标异动分析 5. 反问:团队组织结构,对我的建议 反思: 1. 介绍项目的时候没有框架,是按着项目流程来讲,且讲的时间太长了,会让人没有听得欲望。之后要练习用star法则串起来。 2. sql边学边忘,答的很不好,一定要每天都练。概率一直不太行……指标异动分析还要
-
 快手国际化数分面经
快手国际化数分面经1. 自我介绍,介绍之前的实习经历、个人技能、对这段实习的期望。 2. 做提数需求具体做了哪些分析,可以举个例子。 3. 在上一段实习中有哪些做的好的地方。 4. 有哪些不足之处。 5. python用的多吗。 6. 笔试题: ○ 第一题很简单,窗口函数排序; ○ 第二题:直播表A:date author live_id brodcast_time ○ 观众表B:date audience liv
-
 虎彩数分实习岗-面经
虎彩数分实习岗-面经#面经# #虎彩集团# 2024.4.2 bg双非二本,非科班,第一次面试,表现不错 40min业务面,电话面之后的线上约面,不知道算是几面 1.自我介绍 2.介绍一个觉得比较有价值的经历(表达清晰,答得挺好,不过可以更简洁,直接说要点) 3.针对经历深挖 4.表达对于数据分析的理解 5.数据分析所需的技能 6.excel常用函数,sumif和sumifs区别,countif和countifs区别
-
 快手数分秋招一二面
快手数分秋招一二面部门是:内容安全风控 写个面经 攒人品让我进三面吧 一面8.5 面试官没开摄像头 1.自我介绍 2.实习经历深挖 3.从用户和内容维度搭建指标 4.sql 如何监控平台安全健康(自己给字段,sql说思路) 5.反问 一面大概半个小时,以为挂了,8.9通知8.12二面(三个工作日,还挺快) 二面8.12 面试官开摄像头了 1.自我介绍 2.两段实习经历深挖 3.一道概率题 A、B服从U(0,1),求