《数据分析面试》专题
-
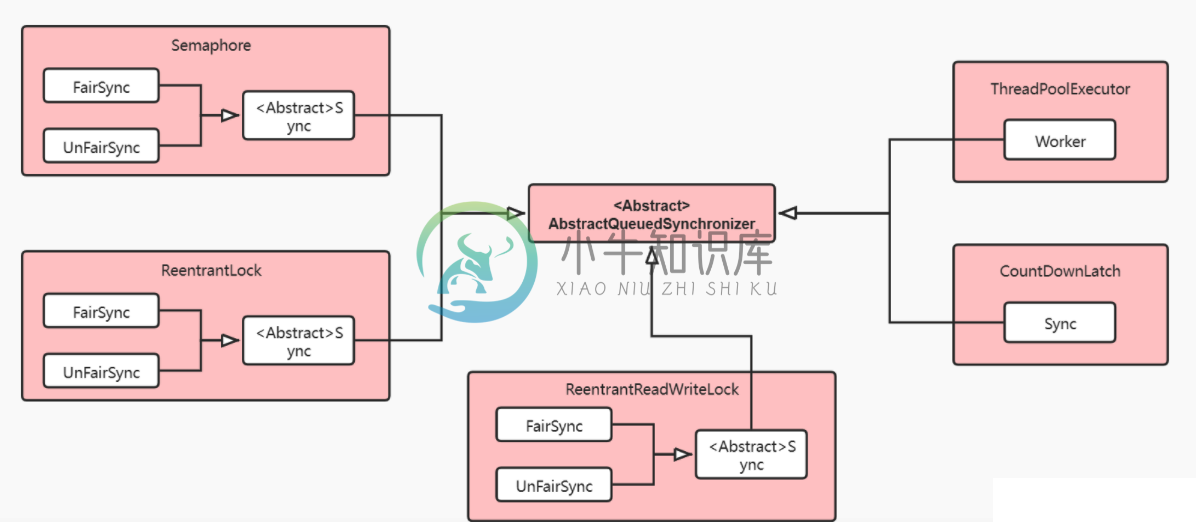 AQS之ReentrantLock分析 (四)
AQS之ReentrantLock分析 (四)主要内容:1.AQS 子类,2.ReentrantLock 简介,3.获取锁,4.释放锁1.AQS 子类 Semphore: 共享锁案例 ReentrantLock: 排他锁案例 ReentrantReadWriteLock: 共享锁和排它锁案例 ThreadPoolExecutor CountDownLatch: 共享锁案例 2.ReentrantLock 简介 ReentrantLock 为可重入锁。 2.1 Sync 和Semaphore相似,ReentrantLock也是通过
-
 数据开发 - 面经 - 来未来(医疗大数据)
数据开发 - 面经 - 来未来(医疗大数据)2024.1.9 面试 Boss直聘沟通 公司要求驻场开发,接受加班,接受出差 你是25届是吧?能在六个月左右是吗?目前在校吗? 后续有什么规划? 你怎么理解数据开发这个岗位的? 讲讲简历上这两个项目?是你在学校做的是吧? 项目你是全程参与是吧? 聊天这个项目的数据源是哪里来的呀? 项目整体是落在HDFS上是吧? 单一架构,嗷,然后可视化,是哇? 下一个电商项目介绍一下? 数据来源讲讲? 那意思是
-
 人大金仓数据库测试一面面经(10.26)
人大金仓数据库测试一面面经(10.26)1.自我介绍 2.数据库语言,DDL,DQL,DML... 3.考察数据库语言,建表,更改等 4.事务的四大特性 5.利用session模拟读已提交(完蛋,一点都不会) 6.对隔离的理解 7.项目中你如何进行测试,自己的项目 8.使用什么进行测试的,Jmeter 9.Jmeter怎么进行并发的检测,设置线程数(问性能测试) 10.linux的基本命令 11.软件测试模型VW 12.熟悉python
-
 2023秋招-大数据开发面试-百度-三面
2023秋招-大数据开发面试-百度-三面1、 项目一直挖 2、 Spark调优 3、 Shuffle之类的优化 4、 平常写SQL注重优化之类的问题 5、 第一道题让看下面Java代码写输出。 private static void test(int[] arr) { for (int i = 0; i < arr.length; i++) { try { if (arr[i] % 2
-
C#中分部方法和分部类分析
本文向大家介绍C#中分部方法和分部类分析,包括了C#中分部方法和分部类分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了C#中分部方法和分部类。分享给大家供大家参考。 具体代码如下: 希望本文所述对大家的C#程序设计有所帮助。
-
1.13 第十二部分 独立成分分析
第十二部分 独立成分分析(Independent Components Analysis ) 接下来我们要讲的主体是独立成分分析(Independent Components Analysis,缩写为 ICA)。这个方法和主成分分析(PCA)类似,也是要找到一组新的基向量(basis)来表征(represent)样本数据。然而,这两个方法的目的是非常不同的。 还是先用“鸡尾酒会问题(cocktai
-
 联通数科 一面 数据开发
联通数科 一面 数据开发昨天面的,三个面试官。 开始就是自我介绍。 1、第一个面试官问了问我一个数学建模的题目。我自己提了一嘴lstm,问了一下三个门 2、问了个sql题目,id不一样,邮箱有重复,怎么选出来,说用pandas也可以,问我pandas,不过我确实不常用pandas就没答出来 3、场景题,有通讯时间、地点、上网记录,如何判断哪些人是学生。 第二个问我懂不懂kafka、Hbase这些,我说不懂,就结束了。 感
-
 快手数分实习转正二面+三面面经
快手数分实习转正二面+三面面经风格是氛围轻松但是内容压力的笑面虎面。都是聊一件最能体现你个人能力的项目or工作。然后细致掰扯细节+追问。追问的特别特别细,两面都是+2的leader,提问的角度都特别刁钻特别详尽。 具体内容涉及业务就不展开说了,我试试抽象一下问法。 内容上,任何下意识想不到定义和明确说法的说法/数据口径他们会追问,相关数据最近是一个什么值他们也要“为难”你一下,看你了不了解。项目里任何处理细节都会问,只要有一个
-
 从面试官角度分析下:如何准备产品经理实习生面试
从面试官角度分析下:如何准备产品经理实习生面试最近2年,连续带了4个实习生,3个转正,1个继续读研; 看着他们从最初叫我“总”,到叫我“哥”,再到喊我“师傅”; 看着他们在转正庆祝聚餐的时候,从开心的提前订餐点菜,到兴奋的手舞足蹈,再到激动的掩面而泣; 觥筹交错间,我觉得应该写点什么,以此对过去的那些难忘时光聊表纪念,也希望可以为更多的莘莘学子,点亮一盏灯,带来一些暖。 第一篇,从如何准备产品经理的面试开始谈起 PS:这里的产品经理,特指系统
-
Java/Android引用类型及其使用全面分析
本文向大家介绍Java/Android引用类型及其使用全面分析,包括了Java/Android引用类型及其使用全面分析的使用技巧和注意事项,需要的朋友参考一下 Java/Android中有四种引用类型,分别是: Strong reference - 强引用 Soft Reference - 软引用 Weak Reference - 弱引用 Phantom Reference - 虚引用 不同的引用
-
使用Node.js和XPath对页面进行性能分析
问题内容: 我正在使用Node.js进行一些Web抓取。我想使用XPath,因为我可以使用几种GUI半自动生成它。问题是我找不到有效的方法。 非常慢。它会在一分钟左右的时间内解析500KiB文件,并具有完整的CPU负载和大量内存。 流行的HTML解析库(例如)既不支持XPath,也不公开W3C兼容的DOM。 很明显,有效的HTML解析是在WebKit中实现的,因此可以使用或将其作为一种选择,但这些
-
使用AngularJS跟踪Google Analytics(分析)页面浏览量
问题内容: 我正在使用AngularJS作为前端设置一个新应用。客户端上的所有操作都是通过HTML5 pushstate完成的,我希望能够在Google Analytics(分析)中跟踪页面浏览量。 问题答案: 如果您在Angular应用中使用,则可以监听事件并将跟踪事件推送到Google Analytics(分析)。 假设您已经在主index.html文件中设置了名称为的跟踪代码,并且MyCtr
-
ImageJ:在计算面积%时使用ROI分析颗粒
我是一个使用ImageJ的初学者。我有一张直径为4“的有空洞的晶圆的图像。我首先缩放图像。然后做一个阈值颜色,只突出空洞。然后在晶圆周围放置一个ROI。 然后我运行“分析粒子”例程,它很好地包围了空隙,在汇总表中,“总面积”列似乎得出了正确的“总空隙面积”。但是%Area列#很低,我认为是因为它使用了总面积\整个图像区域。我想让它告诉我晶圆中空洞的百分比,即总空洞面积\ ROI面积(晶圆面积)。有
-
 满帮校招一二三面凉经 经营分析
满帮校招一二三面凉经 经营分析时间线:09.06笔试,09.16一面,09.21二面,09.22三面,09.26收到感谢信 一面:业务 30min 深挖实习经历 面试官比较注重是否了解目标值以及项目整体的了解情况,而不是具体的执行细节 有问指标体系搭建和增长目标制定的问题 二面:hr 30min 1. 经营分析的理解 2. 如何看待“扬长避短” 3. 从经营分析的角度评价实习部门的业务情况 4. 职业规划 三
-
受访页面提供的信息及价值分析
使用指南 - 数据报告 - 访问分析 - 受访页面提供的信息及价值分析 受访页面提供的信息及价值分析 受访页面报告提供了访客对您网站内各个页面的访问情况数据。通过这个报告,您可以获得以下一些信息: 1)访客进入您网站后通常首要访问和次要访问的页面是哪些。 这些页面是访客形成对您网站第一印象的重要页面,对于访客是否继续关注您的网站、以及最终是否选择您的产品或服务起着决定性的作用。您可以从界面美观性、